
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
智东西6月21日消息 , 6月18日 , 前OpenAI联合创始人、深度学习专家安德烈·卡帕西(Andrej Karpathy)在Y Combinator(YC)于美国旧金山Moscone会议中心举办的AI创业学院(AI Startup School)活动上 , 以《软件正在发生根本变化》(Software Is Changing (Again))为题发表40分钟主题演讲 , 系统阐释了大语言模型是如何将软件开发从“写代码/调参数”转向“自然语言指挥AI” 。
卡帕西在演讲中透露 , 软件开发已进入“Software 3.0”阶段 。 他提出 , 传统的手写代码时代 , 即Software 1.0 , 以及训练神经网络权重的Software 2.0时代 , 正被“提示词即程序”的Software 3.0所取代 。 自然语言正成为直接控制计算机的新编程接口 。
同时 , 卡帕西定义了大语言模型的三重核心属性:大语言模型兼具类似电网的基础设施服务属性、类似芯片晶圆厂的百亿级资本密集投入属性 , 以及类似操作系统的复杂生态构建与分层管理属性 。
当提到大语言模型存在的认知缺陷时 , 卡帕西说大语言模型主要有两大关键认知缺陷:一是“锯齿状智能”(Jagged Intelligence) , 表现为处理复杂任务能力突出 , 却在如数值比较、拼写的基础逻辑上频繁出错;二是信息一旦超出设定的上下文窗口便无法被保留 。
针对大语言模型的自主性控制挑战 , 卡帕西提出了仿钢铁侠战甲的动态控制框架 。 这个框架的核心是通过自主性调节器 , 实现类似特斯拉Autopilot的L1-L4分级决策权限分配 。
就像钢铁侠的战衣一样 , 人们可以根据任务的复杂性和风险程度 , 动态调整AI的自主程度 , 从简单的辅助建议到完全自主决策 , 让人类始终保持对系统的最终控制权 。
以下是卡帕西所发表演讲的完整编译(为提高可读性 , 智东西在不违背原意的前提下进行了一定的增删修改):
01 软件进化路径:从写代码、教电脑 , 到“说话”指挥AI今天我很兴奋能在这里和大家聊AI时代的软件 。 我听说你们很多人是学生 , 本科生、硕士生、博士生等等 , 即将进入这个行业 。 现在进入行业其实是一个极其独特、非常有趣的时刻 。
根本原因在于软件正经历根本性变革 。 我说“再次” , 是因为它持续剧变 , 这让我总有新材料创作新演讲 。
粗略地说 , 我认为软件在根本层面上70年没大变 , 但最近几年快速变化了两次 。 这带来了海量的软件编写和重写工作 。 我几年前观察到软件在变化 , 出现了一种新型软件 , 我称之为Software 2.0 。
我的想法是:Software 1.0是你编写的计算机代码;Software 2.0本质上是神经网络的权重 。 你不是直接编写它 , 而是通过调整数据集和运行优化器来创建这些参数 。
当时神经网络常被视为另一种分类器 , 但我认为这个框架更贴切;现在 , 我们在Software 2.0领域有了类似GitHub的存在 , 我认为Hugging Face是Software 2.0领域的GitHub , 其推出的Model Atlas也在其中扮演着重要角色 。
作为一个极具影响力的平台 , Hugging Face为开发者提供了丰富的资源与便捷的工具 , 就像GitHub在传统软件开发中所做的那样 , 它推动着Software 2.0领域的技术交流与创新发展 , 而模型地图(Model Atlas)如同一个庞大的模型资源库 , 进一步丰富了平台的生态 , 让开发者能够更轻松地获取和使用各类模型 , 助力不同项目的开发与落地 。 模型地图是一种可视化模型仓库的开源工具 , 针对Software 2.0设计 。
例如 , 那个巨大的中心圆圈代表Flux图像生成器的参数 , 每次在其基础上调整 , 就相当于一次git commit , 创建一个新的图像生成器 。
所以 , Software 1.0通过编写代码对计算机进行编程 , Software 2.0则借助如AlexNet等神经网络的权重实现对神经网络的编程 。
直到最近 , 这些神经网络都是固定功能的 。 我认为一个根本性的变化是:神经网络通过大语言模型变得可编程了 。 我认为这非常新颖独特 , 是一种新型计算机 , 值得称为Software 3.0 。
在Software 3.0中 , 你的提示词就是编程大语言模型的程序 。 值得注意的是 , 这些提示是用英语写的 , 这是一种非常有趣的编程语言 。
比如你想让电脑进行一下情感分类 , 完成判断一条评论是夸人还是骂人的任务 , 有不同的方法 。
Software 1.0的老方法:你得像个老师傅 , 自己动手写一堆代码 , 告诉电脑看到哪些词算夸、哪些词算骂;进化一点的Software 2.0:你像个教练 , 找一堆标好了“夸”或“骂”的评论例子 , 让电脑自己琢磨学习规律;Software 3.0:你像个老板 , 直接对大语言模型下命令:“看看这条评论是夸还是骂?只准回‘夸’或‘骂’!”就这一句话 , AI就懂了 , 马上给你答案 。 你要是把命令改成“分析下这条评论是积极还是消极” , 它回答的方式也跟着变 。
我们看到GitHub上的代码不再仅是代码 , 还夹杂着英语 , 这是一种正在增长的新代码类别 。 这不仅是一个新范式 , 同样令我惊讶的是它使用英语 。 这让我几年前震惊并发布了推文 。
我在特斯拉研发Autopilot时观察到:起初栈底是传感器输入 , 经过大量C++(1.0)和神经网络(2.0)处理 , 输出驾驶指令 。 随着Autopilot改进 , 神经网络能力和规模增长 , C++代码被删除 。 许多原本由1.0实现的功能迁移到了2.0 。 Software 2.0栈实实在在地“吃掉”了1.0栈 。
在特斯拉研发Autopilot时观察到的2.0吞噬传统代码栈
我们正再次看到同样的事情发生:Software 3.0正在“吃掉”整个栈 。 现在我们有了三种完全不同的编程范式 。 我认为进入行业时精通三者是明智的 , 它们各有优劣 。 你需要决定:某个功能该用1.0、2.0还是3.0实现?是训练神经网络还是提示大语言模型?这该是显式代码吗?我们需要做这些决定 , 并可能需要在范式间流畅转换 。
02 大语言模型成为新操作系统 , 计算呈分时共享模式软件正在经历根本性的变化 , 这种变化在过去70年中从未如此剧烈 。 大约70年来 , 软件的底层范式几乎未变 , 但在过去几年里 , 它连续发生了两次结构性巨变 。 现在 , 我们正站在软件重写的浪潮上 , 有大量的工作要做、大量的软件要写 , 甚至重写 。
几年前 , 我注意到软件开始向一种新形式演化 , 我当时给它取名叫Software 2.0 。 Software 1.0是传统意义上我们手写的代码 , 而Software 2.0指的是神经网络的参数 。 我们不再直接写“代码” , 而是调数据、跑优化器 , 生成参数 。
如今 , 在Software 2.0世界中也有了类似GitHub的东西 , 比如Hugging Face和模型地图 , 它们就像代码库一样存储着不同的模型 。 每次有人在Flux模型基础上进行调整 , 就相当于在这个空间创建了一次代码提交 。
而现在 , 大语言模型的出现带来了更根本的改变 。 我认为这是一种全新的计算机 , 甚至值得被称为Software 3.0 。 你的提示现在就是对大语言模型编程的程序 , 而且这些提示是用英语编写的 。 这是一种非常有趣的编程语言 。
Andrew Ng曾说“AI是新时代的电力” , 这句话点出了关键点 , 比如OpenAI、谷歌、Anthropic等投入资本来训练模型 , 然后用运营开销通过API向开发者“输送智能” , 模型按token计价 , 像电力一样被“计量使用” 。 我们对这些模型的要求也非常像“基础设施”:低延迟、高可用、稳定输出 。
如OpenAI、Gemini、Anthropic投入资本训练模型 , 类似构建电网
但大语言模型不仅具有公用事业的属性 , 它们更像是复杂的软件操作系统 。 OpenAI、Anthropic就像是Windows和macOS , 而开源模型则更像Linux 。 操作系统的作用不是“运行某个功能” , 而是构建一个“平台”来承载更多功能 。
闭源供应商如Windows、Mac OS有开源替代方案Linux
更准确地说 , 大语言模型并非独立完成任务 , 而是作为承载提示词、工具及Agent等组件的“运行时系统”来发挥作用 。 这些组件如同插件般嵌入大语言模型框架中 , 通过模型的推理能力协调运作 , 共同实现复杂任务的处理 。
从计算模式来看 , 我们现在的大语言模型计算处于1960年代的阶段 。 大语言模型推理成本仍然很高 , 模型计算集中部署在云端 , 我们如同瘦客户端(Thin Client)通过网络远程访问 。
这就像“分时共享”计算模式:多用户排队使用同一模型 , 云端以“批处理”方式依次执行任务 , 就像多人轮流使用一台超级计算机 , 按序获取计算资源 。
有趣的是 , 大语言模型颠倒了传统技术扩散的方向 。 通常 , 新技术首先由政府和企业使用 , 之后才扩散到消费者 。 但大语言模型不同 , 它首先服务的是普通人 , 比如帮助用户煮鸡蛋 , 而政府和企业反而在落后地采用这些技术 。
大语言模型帮助用户煮鸡蛋
这完全颠倒了传统路径 , 也可能启示我们:真正的杀手级应用会从个人用户端长出来 。
总结来看 , 大语言模型本质上是复杂的软件操作系统 , 我们正在“重新发明计算” , 就像1960年代那样 。 而且它们现在以“时间共享”的方式提供服务 , 像公用事业一样被分发 。
真正不同的是 , 它们不是掌握在政府或少数企业手里 , 而是属于我们每一个人 。 我们每个人都有电脑 , 而大语言模型只是软件 , 它可以在一夜之间传遍整个星球 , 进入数十亿人的设备 。
现在 , 轮到我们进入这个行业 , 去编程这个“新计算机” 。 这是一个充满机遇的时代 , 我们需要熟练掌握Software 1.0、2.0和3.0这三种编程范式 , 在不同场景下灵活运用 , 以发挥它们的最大价值 。
03 拥有超强记忆 , 却存在“记忆碎片”式健忘症与认知错误研究大语言模型时 , 我们得花些时间思考它们究竟是什么 。 我尤其想聊聊它们的“心理” 。 在我看来 , 大语言模型有点像人的灵魂 , 是对人类的静态模拟 。 这里的模拟工具是自回归变换器 , 变换器本质上是一种神经网络 , 它以token为单位 , 一个token接一个token地处理信息 , 处理每个token所耗费的计算量几乎相同 。
当然 , 这个模拟过程涉及一些参数权重 , 我们根据互联网上的所有文本数据对其进行拟合 , 最终得到这样一个模拟工具 。 它是基于人类文本数据训练的 , 因此产生了类似人类的“心理”特征 。
首先 , 我们会注意到 , 大语言模型拥有百科全书式的知识和超强的记忆力 。 它们能记住的内容比任何一个普通人都要多得多 , 因为它们“阅读”了海量信息 。 这让我想起电影《雨人》 , 强烈推荐大家去看看 , 这是一部很棒的电影 。
达斯汀·霍夫曼在影片中饰演一位患有自闭症的天才 , 拥有近乎完美的记忆力 , 他可以读完一本电话簿 , 并记住所有的姓名和电话号码 。 我觉得大语言模型和他很相似 , 它们能轻松记住哈希值等各种各样的信息 , 在某些方面确实拥有“超能力” 。
不过 , 大语言也存在一些认知缺陷 。 它们经常会产生幻觉 , 编造一些内容 , 而且缺乏足够完善的自我认知内部模型 。 虽然这方面已经有所改善 , 但仍不完美 。
它们的智能表现参差不齐 , 在某些问题解决领域展现出超人的能力 , 但也会犯一些人类几乎不会犯的错误 , 比如坚称9.11大于9.9 , 或者认为“strawberry”里有两个“r” , 这些都是很有名的例子 。 总之 , 它们存在一些容易让人“踩坑”的认知盲区 。
此外 , 大语言模型还存在遗忘问题 。 打个比方 , 如果有新同事加入公司 , 随着时间推移 , 这位同事会逐渐了解公司 , 掌握大量公司相关背景信息 , 晚上回家休息时巩固知识 , 久而久之积累专业知识 。
但大语言模型天生不具备这种能力 , 在大语言模型的研发中 , 这一问题也尚未得到真正解决 。 上下文窗口就好比工作记忆 , 我们必须非常直接地对其进行编程设定 , 因为大语言模型不会默认自动变得更智能 。
我认为很多人会被流行文化中的一些类比误导 , 我建议大家看看《记忆碎片》和《初恋50次》这两部电影 。 在这两部电影中 , 主角的记忆权重是固定的 , 每天早上上下文窗口都会被清空 。 在这种情况下 , 去工作或者维持人际关系都变得非常困难 , 而这恰恰是大语言模型经常面临的情况 。
我还想指出一点 , 就是使用大语言模型时在安全方面的相关限制 。 例如 , 大语言模型很容易被欺骗 , 容易受到提示注入风险的影响 , 可能会泄露你的数据等等 , 在安全方面还有许多其他需要考虑的因素 。
简而言之 , 大语言模型既是拥有超能力的“超人” , 又存在一系列认知缺陷和问题 。 那么 , 我们该如何对它们进行编程 , 如何规避它们的缺陷 , 同时又能充分利用它们的超能力呢?
04 最大机遇是做带自主调节功能的半自动化应用 , 有好用的界面和操作体验现在 , 我想转而谈谈如何利用这些模型 , 以及其中最大的机遇是什么 。 我最感兴趣的是“部分自主化应用”这一方向 。 以编程场景为例 , 你可以直接使用ChatGPT复制粘贴代码、提交bug报告 , 但为什么要直接与操作系统交互呢?更合理的方式是构建专用应用 。
我和在座很多人一样在用Cursor , 它是早期大语言模型应用的典范 , 具备几个关键特性:保留传统手动操作界面的同时集成大语言模型处理大块任务;大语言模型负责大量上下文管理;编排多轮模型调用 , Cursor底层实际上整合了代码嵌入模型、聊天模型以及用于代码差异应用的模型 。
专用GUI的重要性常被低估 。 文本交互难以阅读和操作 , 而可视化diff以红色标识删除、绿色标识新增 , 配合Command+Y/N快捷键能大幅提升审查效率;还有“自主滑块”设计 , 比如Cursor中从代码补全到修改整个文件甚至整个代码库的不同自主层级 , 用户可根据任务复杂度调整放权程度 。
【说话就能编程的时代来了,AI大神卡帕西40分钟演讲精华】另一个成功案例是Perplexity , 它同样整合多模型调用、提供可审计的GUI , 用户能点击查看引用来源 , 也设有自主滑块 , 提供快速搜索、深度研究等不同模式 。
我认为未来大量软件将走向部分自主化 , 这需要思考几个核心问题:大语言模型能否感知人类所见、执行人类所行?人类如何有效监督这些尚不完美的系统?传统软件的交互设计如何适配大语言模型?
当前大语言模型应用的关键在于优化“生成-验证”循环效率 。 一方面 , GUI利用人类视觉系统快速审查结果 , 读文本费力而看图轻松;另一方面 , 必须控制AI的“自主性”:10000行代码的diff对开发者毫无意义 , 人类仍是质量瓶颈 。 我在实际编程中始终坚持小步迭代 , 避免过大变更 , 通过快速验证确保质量 。
教育领域的应用设计也遵循类似逻辑:教师端应用生成课程 , 学生端应用提供结构化学习路径 , 中间课程作为可审计的中间产物 , 确保AI在既定教学大纲和项目流程内工作 , 避免“迷失” 。
回顾在特斯拉的经历 , 自动驾驶系统同样采用部分自主模式:仪表盘实时显示神经网络感知结果 , 用户通过“自主滑块”逐步放权 。 2013年我首次体验完全无干预的自动驾驶时 , 曾认为技术已成熟 。
当时朋友在Waymo工作 , 带我在帕洛阿尔托的高速和街道上行驶了30分钟 , 全程零干预 , 我用谷歌眼镜记录下了这一幕 。 但12年后的今天 , 即便能看到Waymo的无人驾驶车辆上路 , 背后仍依赖大量远程操作和人工介入 。 这说明软件系统的复杂性远超预期 , AI Agent的发展将是长期过程 , 需保持谨慎 。
同样地 , 类比钢铁侠战衣可知:当前更应聚焦“增强型工具” , 而非“全自主机器人” 。
构建部分自主产品时 , 需做好两点:一是设计定制化GUI与UX(用户体验) , 确保“生成-验证”循环高效运转;二是保留自主滑块机制 , 以便逐步提升产品自主性 。 这正是我眼中的重要机会方向 。
05 自然语言编程让人人能开发 , 加快Agent基础设施转型我认为大语言模型用英语编程这件事 , 让软件变得极具可访问性!同时我想补充另一个独特维度:如今不仅出现了允许软件自主运行的新型编程语言 , 而且它以英语这种自然界面编程 。
突然之间 , 每个人都能成为程序员 , 因为人人都会说英语这样的自然语言 , 这让我感到非常振奋 , 也觉得前所未有的有趣 。 过去 , 你需要花5到10年学习才能在软件领域有所作为 , 但现在完全不同了 。
不知道大家有没有听说过“Vibe Coding”(基于自然语言交互的编程方式)?这个概念最初由一条推文引入 , 现在已经成了一个热门梗 。
说起来有趣 , 我在Twitter上待了15年左右 , 至今仍搞不懂哪条推文会爆火 , 哪条会无人问津 。 当时我发那条推文时 , 以为它会石沉大海 , 毕竟那只是我洗澡时的随想 , 结果它成了全网梗 , 甚至有了维基百科页面 , 这算是我对行业的一大贡献吧 。
HuggingFace的Tom Wolf分享过一个很棒的视频 , 里面是孩子们在“Vibe Coding” 。 我特别喜欢这个视频 , 它太治愈了 , 看了这样的画面 , 谁还会对未来感到悲观呢?我觉得这会成为软件开发的“入门药” 。 我对这代人的未来并不悲观 , 真的很爱这个视频 。 受此启发 , 我也尝试了“Vibe Coding” , 因为它太有趣了 。
比如当你想做一个特别定制化、市面上不存在的东西 , 又恰逢周六想随性发挥时 , 这种编程方式就很合适 。 我曾用它开发了一个iOS应用 , 虽然我完全不会Swift , 但居然能做出一个超基础的应用 , 过程很简单 , 我就不细说了 , 但那天花了一天时间 , 晚上应用就在我手机上运行了 , 我当时真的觉得“太神奇了” , 不用花五天时间啃Swift教程就能上手 。
我还“Vibe Coding”了一个叫Menu Genen的应用 , 现在已经上线 , 大家可以在menu.app试用 。 我开发它的初衷很简单:每次去餐厅看菜单 , 我都不知道那些菜是什么 , 需要配图 , 但市面上没有这样的工具 , 于是我就“Vibe Coding”了一个 。 用户注册后能获得5美元credits , 但这对我来说是个巨大的成本中心 。
现在这个应用还在亏钱 , 我已经搭进去很多钱了 。 不过有趣的是 , 开发Menu Genen时 , “Vibe Coding”的代码部分其实是最简单的 , 真正难的是把它落地成可用的产品:认证系统、支付功能、域名注册和部署 , 这些都不是写代码 , 而是在浏览器里点点点的DevOps工作 , 极其繁琐 , 花了我一周时间 。
比如给网页添加谷歌登录时 , 文档里全是“去这个URL , 点击下拉菜单 , 选择这个 , 再点那个”之类的指令 , 简直像电脑在指挥我做事 , 为什么不是它自己做呢?这太疯狂了 。
所以我演讲的最后一部分想探讨:我们能否为Agent构建基础设施?大语言模型正在成为数字信息的新型主要消费者和操控者 , 我不想再做那些繁琐的手动工作了 , 能不能让Agent来做?
概括来说 , 数字信息的消费者和操控者范畴正在扩展:过去只有通过GUI交互的人类 , 或通过API交互的计算机 , 现在多了Agent , 它们是像人类一样的计算机 , 是互联网上的“数字精灵” , 需要与我们的软件基础设施交互 。
比如 , 我们可以在域名下创建lm.txt文件 , 用简单的Markdown告诉大语言模型这个域名的内容 , 这比让它们解析HTML更高效 , 因为HTML解析容易出错 。 现在很多文档还是为人类编写的 , 有列表、粗体、图片 , 但大语言模型难以直接理解 。
我注意到Vercel和Stripe等公司已经开始将文档转为大语言模型友好的Markdown格式 , 这是很好的尝试 。
举个例子 , 由斯坦福大学数学系毕业生格兰特·桑德森(Grant Sanderson)创建的YouTube频道3Blue1Brown的动画视频文档写得很棒 , 我不想通读 , 就把文档复制给大语言模型 , 告诉它我的需求 , 结果它直接帮我生成了想要的动画 。
如果文档能让大语言模型读懂 , 会释放巨大的应用潜力 。 但这不仅是转换格式的问题 , 比如文档里的“点击此处”对大语言模型毫无意义 , Vercel就把所有“点击”替换成了大语言模型Agent可用的curl命令 。
此外 , Anthropic的模型上下文协议MCP(model context protocol)也是直接与Agent交互的新方式 , 我很看好这些方向 。
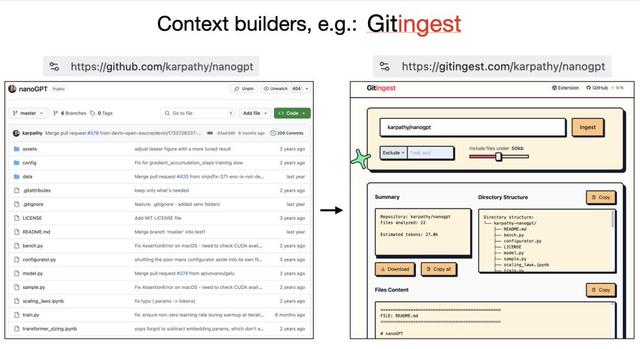
还有一些工具也在助力大语言模型友好的数据处理:比如把GitHub仓库的URL改成get.ingest , 就能将所有文件合并成可直接喂给大语言模型的文本;Deep Wiki不仅提取文件内容 , 还能分析GitHub仓库并生成文档 , 方便大语言模型理解 。 这些工具只需修改URL就能让内容适配大语言模型 , 非常实用 。
虽然未来大语言模型可能具备点击操作的能力 , 但现在让它们更便捷地获取信息仍有必要 , 毕竟当前大语言模型调用成本较高 , 且操作复杂 , 很多软件可能不会主动适配 , 所以这些工具很有存在价值 。
总结来看 , 现在进入这个行业正是时候:我们需要重写大量代码 , 未来专业开发者和大语言模型都会成为代码的生产者 。 大语言模型就像早期的操作系统 , 这些“会犯错的数字精灵”需要我们调整基础设施来适配 。
今天我分享了高效使用大语言模型的方法、相关工具 , 以及如何快速迭代产品 。 回到“钢铁侠战衣”的比喻 , 未来十年 , 我们会见证人机协作的边界不断拓展 , 我已经迫不及待想和大家一起参与其中 。
推荐阅读
















- 为什么一个弹幕,就能让主播喵一百声?
- 华为HarmonyOS 6来了,还有自研编程语言丨两分钟发布会
- 同一天开源新模型,一推理一编程,MiniMax和月之暗面开卷了
- 看一下就能买单 全球首个智能眼镜支付来了
- 20瓦就能运行下一代AI?科学家瞄上了神经形态计算
- 让用户在Mac上玩3A游戏,不如直接就能运行手游
- 618就要结束了 这几款热门手机仅2000元出头就能拿下
- 爱立信破解运营商“管道化”困局:可编程网络与AI双轮驱动
- 三星电子计划下月引入AI编程助手 以提高软件开发效率
- Cursor 1.0来袭!自动捉bug,秒改屎山代码,AI编程分水岭已至