
文章图片
文章图片

文章图片

ZPressor能高效压缩3D高斯泼溅(3DGS)模型的多视图输入 , 解决其在处理密集视图时的性能瓶颈 , 提升渲染效率和质量 。 通过信息瓶颈原理 , 将视图分为锚点和支持集 , 利用交叉注意力机制压缩信息 , 显著降低内存占用和推理时间 , 同时提升性能 , 让3DGS在高视图输入下也能高效运行 。
在增强现实(AR)和虚拟现实(VR)等前沿应用领域 , 新视角合成(Novel View Synthesis NVS)正扮演着越来越关键的角色 。
近年来 , 3D高斯泼溅(3D Gaussian Splatting 3DGS)技术横空出世 , 凭借其革命性的实时渲染能力和卓越的视觉质量 , 迅速成为NVS领域的一大突破 。
然而 , 传统3DGS对耗时的「逐场景优化」的依赖 , 严重限制了其在实际应用中的部署 。 前馈3DGS(Feed-Forward 3DGS) , 通过单次前向推理获取场景的三维信息 。
这种演进看似解决了核心问题 , 但随之而来的挑战却让其在「多视角」前步履维艰:当前的前馈3DGS模型在处理密集输入视图时 , 其可扩展性受到了根本性的制约 。
深入分析现有前馈3DGS模型的架构 , 可以发现其核心症结在于编码器容量的有限性 。 当输入视图变得密集时 , 编码器难以有效处理随之而来的「信息过载」 , 导致计算成本飙升 。
这种现象并非偶然 , 而是源于场景总信息量(即所有视图特征的联合熵)中存在大量冗余信息 。 在特征提取之后 , 如何去除这些不相关信息 , 同时保留其预测能力 , 是高效利用输入视图信息的关键 。
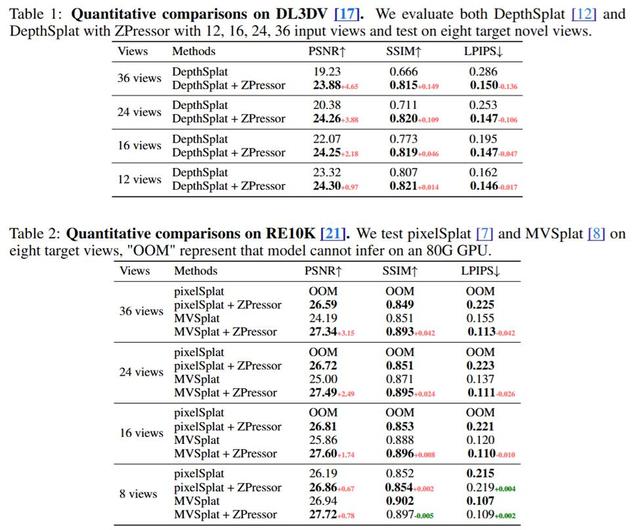
以当前最先进的模型DepthSplat为例 , 实验结果清晰地表明 , 随着输入视图数量的增加 , 其性能会显著下降 , 同时计算成本也急剧攀升 。
例如 , 在处理36个输入视图时 , DepthSplat的PSNR等指标会大幅降低 , 推理时间和内存占用也会显著增加 。 这揭示了信息过载对模型性能和资源消耗的直接因果关系:过多的冗余信息不仅拖慢了处理速度 , 更降低了最终的渲染质量 。
浙江大学的研究人员提出ZPressor , 一种即插即用的轻量级模块 , 压缩前馈3DGS特征 , 增强模型密集视角扩展性和性能 , 36个输入视图下提升4.65dB , 推理时间减少70% , 显存占用减少80% , 并拓展可输入的视图数目到接近500个 。
论文地址:https://www.arxiv.org/abs/2505.23734
项目主页:https://lhmd.top/zpressor
代码链接:https://github.com/ziplab/ZPressor
为了从理论层面理解并解决信息过载问题 , 研究人员引入了信息瓶颈(Information Bottleneck IB)原理 。
IB原理为学习紧凑型表示提供了一个坚实的理论基础 , 其核心思想是:从输入(X)中提取一个压缩表示(Z) , 使Z尽可能地保留与目标(Y)相关的信息 , 同时尽可能地压缩X中与Y无关的信息 。
可以直观地理解为 , IB原理旨在最小化「压缩分数」(即Z携带关于X的信息量) , 同时最大化「预测分数」(即Z对于预测目标Y的有效信息量) 。
该原理为3DGS面临的「信息过载」这一「甜蜜负担」提供了理论上的「减负」之道 。
基于对信息瓶颈原理的理解 , 研究人员提出了ZPressor , 一个轻量级、且 「架构无关」的模块 。
ZPressor的核心功能在于高效地将多视图输入压缩成一个紧凑的潜在状态Z , 这种压缩并非简单地丢弃信息 , 而是巧妙地保留了场景中的必要信息 , 同时有效剔除冗余 , 从而直接解决了前向式3DGS模型长期以来面临的「信息过载」难题 (1) 。
三步走 , 打造高效「信息压缩机」ZPressor的精妙之处在于其将复杂的信息压缩过程分解为三个步骤 , 打造了一个高效的「信息压缩机」 。
第一步:锚点视图选择(Anchor View Selection)ZPressor首先通过 「最远点采样」(farthest point sampling)方法来选择锚点视图 。 这一迭代过程基于相机位置 , 确保所选的锚点在空间上具有多样性 , 并能最大限度地代表整个场景 。
第二步:支持视图归属(Support-to-Anchor Assignment)一旦锚点视图确定 , 每个剩余的支持视图都会根据相机距离被分配到其最近的锚点视图 。 精准的归属机制确保了支持视图中互补的场景细节能够与空间上最相关的锚点视图进行分组 , 保证了信息的「对口」融合 , 避免了无序 。
第三步:视图信息融合(Views Information Fusion)这是ZPressor实现信息压缩的关键步骤 。 它采用定制化的交叉注意力(cross-attention)模块进行信息融合 。
具体而言 , 从锚点视图中提取的特征充当「查询」(query) , 而支持视图的特征则提供「键」(keys)和「值」(values) 。
通过这种方式 , 支持视图的信息被有效地整合到锚点视图中 , 不仅捕捉了两者之间的关联性 , 还在保持紧凑性的同时避免了冗余 。
最终 , 交叉注意力机制的运用 , 让这些互补信息真正「融会贯通」 , 形成精炼而全面的Z态 。
性能飙升 , 内存狂降 , 让3DGS「脱胎换骨」ZPressor对前向式3DGS模型产生了变革性的影响 , 这一点通过对DepthSplat、MVSplat和pixelSplat等经典模型在DL3DV-10K、RealEstate10K和ACID等大规模基准数据集进行的广泛实验中得到了充分验证 。
更令人振奋的是 , ZPressor解决了现有模型在内存方面的根本性障碍 。 例如 , pixelSplat在输入视图超过8个时就因「内存溢出」(OOM)而无法运行 , 而ZPressor不仅使其能够成功运行至少36个视图 , 还在性能上带来了显著提升 。
ZPressor在效率方面的优势同样令人惊叹 。 它有助于在输入视图数量增加时 , 保持3D高斯数量、测试时推理延迟和峰值内存使用量的稳定 。 这与基线模型中这些指标呈线性增长的趋势形成了鲜明对比 , 后者很快就会变得难以承受 。
研究人员也通过实验验证了场景中确实存在可见的信息瓶颈 , 并且信息瓶颈在平衡压缩和信息保存方面至关重要 。
不止于此 , 应用前景更加广阔本研究对现有前馈3DGS模型的容量限制进行了深入分析 , 并从信息瓶颈原理的视角揭示了其根本原因 。
在此基础上 , 研究团队提出了ZPressor——一个轻量级、架构无关的模块 , 通过高效压缩多视图输入 , 成功帮助模型克服了固有的局限性 , 实现了对更多输入视图的处理能力 。
实验结果表明 , ZPressor不仅在适中视图设置下持续提升了现有基线模型的性能 , 更在密集输入场景下显著增强了模型的鲁棒性 , 同时保持了极具竞争力的效率(包括内存和速度) 。
ZPressor所带来的持续性能提升和效率改进 , 其意义远不止于基准测试中的亮眼数据 。 这种可扩展性、鲁棒性和效率的提升 , 直接指向了ZPressor在现实世界应用中的深远影响 。 ZPressor的出现 , 使得AR/VR能够提供更流畅、更逼真的体验 , 同时降低对硬件资源的需求 , 从而加速这些技术的普及和应用 。
研究人员提出的基于信息瓶颈的「化繁为简」压缩范式 , 也绝不只局限于3DGS领域 。
有理由相信 , 在众多存在「冗余信息」和「信息瓶颈」挑战的其他AI领域——无论是多模态数据处理、大规模传感器融合 , 还是复杂系统状态估计——ZPressor所蕴含的「信息瓶颈」智慧 , 都可能成为解决之道 , 开启一个全新的「通用信息压缩」时代!
参考资料 【3D高斯泼溅,可输入视图量高达500,推理速度提升3倍,内存少80%】https://www.arxiv.org/abs/2505.23734












