【杨立昆亲自发布:Meta最强世界模型开源】
文章图片

文章图片
文章图片

文章图片
文章图片
文章图片

文章图片

文章图片

智东西
编译 | 云鹏
编辑 | 漠影
智东西6月12日消息 , 刚刚 , Meta发布了最新的开源世界模型V-JEPA 2 , 称其在物理世界中实现了最先进的视觉理解和预测 , 从而提高了AI agents的物理推理能力 。
Meta副总裁、首席AI科学家杨立昆(Yann LeCun)在官方视频中提到 , 在世界模型的帮助下 , AI不再需要数百万次的训练才能掌握一项新的能力 , 世界模型直接告诉了AI世界是怎样运行的 , 这可以极大提升效率 。
比如AI会预测我们舀出一勺东西是要放入另一个容器中:
AI甚至可以理解运动员的复杂跳水动作 , 并进行动作拆解:
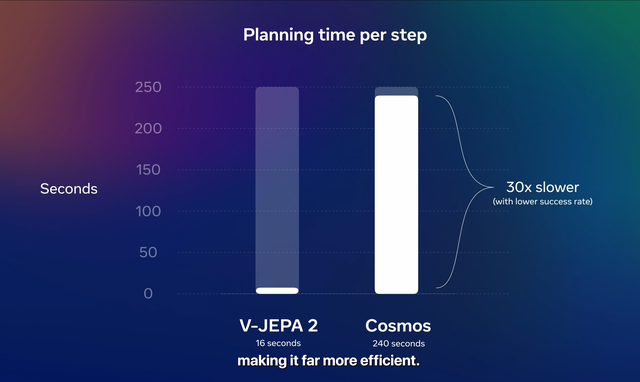
据Meta测试数据 , V-JEPA 2在测试任务中每一步的规划用时缩短至英伟达Cosmos模型的三十分之一 , 同时成功率还更高 。 据称V-JEPA 2使用了一百多万小时的视频来进行自监督学习训练 。
在Meta看来 , 物理推理能力对于构建在现实世界中运作的AI agents、实现高级机器智能(AMI)非常重要 , 可以让AI agents真正可以“三思而后行(Think Before Acts)” 。
此外 , Meta还发布了三个新的基准测试 , 用于评估现有模型从视频中推理物理世界的能力 。
昨天Meta刚刚曝出要成立新AI实验室、招揽28岁华裔天才少年 , 并豪掷148亿美元(约合人民币1061亿元)收购Scale AI 49%股份的消息 , 今天Meta发布新世界模型 , 并让杨立昆出来大讲Meta AI重点研究方向和愿景做法 , 颇有些要为招兵买马“打广告”的意味 。
论文地址: https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
一、世界模型让AI有“类人直觉” , 强化AI agents理解、预测、规划能力理解世界物理规律听起来并不复杂 , 但这是AI与人类差距非常大的一个方面 。
比如你把球抛向空中时 , 知道重力会将其拉回地面;当你穿过一个陌生的拥挤区域时 , 你会一边朝目的地移动 , 一边避免撞到沿途的行人或障碍物;打曲棍球时 , 你会滑向冰球即将到达的位置 , 而非它当前的位置 。
判断篮球的运动轨迹
但AI很难掌握这种能力 , 很难构建这种理解物理世界的“心理模型” 。
Meta的世界模型 , 主要会强化AI agents的理解、预测、规划三项核心能力 。
二、关键架构创新大幅提升学习效率 , 高性能同时兼顾准确率Meta使用视频来训练 V-JEPA 2 , 帮助模型学习物理世界中的重要规律 , 包括人类如何与物体互动、物体在物理世界中的运动方式 , 以及物体之间的相互作用 。
据称V-JEPA 2通过自监督学习 , 训练了超过1百万小时的视频 。
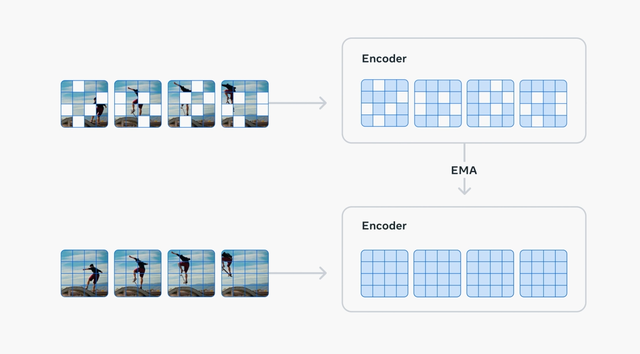
V-JEPA 2是一种联合嵌入预测架构(Joint Embedding Predictive Architecture)模型 , 这也是“JEPA”的名称由来 。
模型包括两个主要组成部分:
一个编码器 , 负责接收原始视频 , 并输出包含对于观察世界状态语义上有用的内容的嵌入(embeddings) 。
一个预测器 , 负责接收视频嵌入和关于要预测的额外内容 , 并输出预测的嵌入 。
V-JEPA 2跟传统预测像素的生成式模型有很大性能差异 , 根据Meta测试数据 , V-JEPA 2执行任务时每个步骤的规划用时缩短至Cosmos模型的三十分之一 , 不仅用时短 , V-JEPA 2的成功率还更高 。
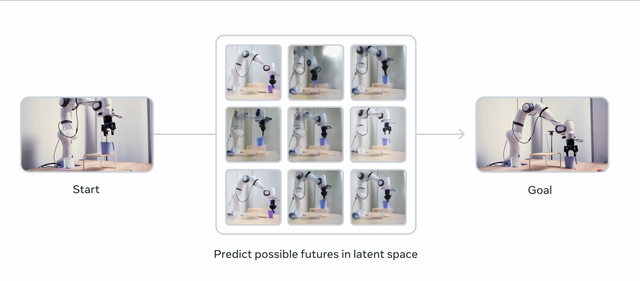
V-JEPA 2的能力对现实世界agents理解复杂运动和时间动态(temporal dynamics) , 以及根据上下文线索预测动作都非常关键 。
基于这种预测能力 , 世界模型对于规划给定目标的动作顺序非常有用 , 比如从一个杯子在桌子上的状态到杯子在桌子边上的状态 , 中间要经历怎样的动作 。
如今大部分AI都需要专业的训练去解决特定的任务 , 而V-JEPA这种自监督的方式 , 只需要为数不多的案例 , 就可以掌握新的能力 , 在不同的任务和领域中实现更高的性能表现 。
模型可以部署在机械臂上 , 去执行物体操作类的任务 , 比如触碰(Reach)、抓?。 ℅rasp)、选择和摆放物体(Pick-and-place) , 而不需要大量的机器人数据或者针对性的任务训练 。
根据测试数据 , V-JEPA 2在执行这三类任务时的成功率分为别100%、45%和73% 。
三、杨立昆展示世界模型应用场景 , 首发三个专项基准测试世界模型可能会有哪些应用场景 , 杨立昆也给大家做了一些展示 。
世界模型加持下的AI agents , 可以帮助视障人群更好的认知世界;
MR头显中的AI agents可以给更复杂的任务提供指导 , 比如让教育更加的个性化;
AI编程助手可以真正理解一行新的代码会如何改变程序的状态或变量;
世界模型对自动化系统同样非常重要 , 比如自动驾驶汽车和机器人;
Meta认为世界模型会为机器人开启一个新的时代 , 让现实世界中的AI agents不需要学习天文数字的训练数据就可以做家务或体力劳动 。
除了发布V-JEPA 2 , Meta还分享了三个新基准测试 , 用来帮助研究界评估现有模型通过视频学习和推理世界的能力:
1、IntPhys 2:用于测试模型在复杂合成环境中的直观物理理解能力(Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments) 。
2、一种基于最小视频对的、感知捷径的物理理解视频问答基准测试(A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs) 。
3、CausalVQA:面向视频模型的物理基础因果推理基准测试(A Physically Grounded Causal Reasoning Benchmark for Video Models) 。
基准测试地址:
IntPhys 2: https://ai.meta.com/research/publications/intphys-2-benchmarking-intuitive-physics-understanding-in-complex-synthetic-environments/
CausalVQA : https://ai.meta.com/research/publications/causalvqa-a-physically-grounded-causal-reasoning-benchmark-for-video-models/
Shortcut-aware Video-QA Benchmark: https://ai.meta.com/research/publications/a-shortcut-aware-video-qa-benchmark-for-physical-understanding-via-minimal-video-pairs/
结语:AI认知世界提速 , AI从数字世界加速走向物理世界Meta二代世界模型的发布进一步优化了模型的性能和准确率 , 让物理世界的AI agents可以更高效地执行任务 , 而不需要海量的数据训练 , 这一方向可以说是目前AI圈关注的焦点赛道之一 。
随着数据瓶颈问题越来越凸显 , 如何在底层技术层面实现突破显得更为关键 , Meta在模型架构层面的创新是其世界模型的核心优势 。
随着如今越来越多的视频模型发布 , AI逐渐从文本、图像走向动态的视频 , AI理解世界、认识世界的速度不断加快 , 从英伟达、Meta、谷歌这样巨头到各路创企 , 都对打造世界模型饶有兴致 , 世界模型之战 , 或许将成为后续AI产业技术竞争的关键看点 。
来源:Meta官网
推荐阅读














- AMD MI350 AI加速器本周发布:推理能力提升35倍,直指NVIDIA
- 小米新机入网:6月份,正式发布
- 华为Pure 80系列发布,Pro版本6499元起售,产品配置、价格汇总
- 首款OLED电竞小平板发布,12GB+256GB卖3499元,可以吗?
- 华为FreeBuds 6悦彰耳机玫瑰金新色发布,时尚与实用价值兼备的随身单品
- 华为新品震撼发布 鸿蒙5全面覆盖手机、平板、电脑、穿戴等全场景
- AirPods 迎来史诗级更新!新款终于即将发布
- OpenAI发布新推理模型o3-pro,并下调o3价格
- 6月首批新机官宣:6月11日/12日,正式发布
- 华为新品震撼发布 鸿蒙5全面覆盖手机、平板、电脑、穿戴等全场景多终端