文章图片

文章图片
文章图片
智东西6月10日报道 , 近日 , 大模型开源圈迎来重磅跨界新玩家——小红书开源了首个大模型dots.llm1 。
dots.llm1是一个1420亿参数的MoE(混合专家)模型 , 仅激活140亿参数 , 可在中英文、数学、对齐等任务上实现与阿里Qwen3-32B接近的性能 。 在中文表现上 , dots.llm1最终性能在C-Eval上达到92.2分 , 超过了包括DeepSeek-V3在内的所有模型 。
小红书开源大模型的一大特色在于数据 。 dots.llm1.ins在预训练阶段使用了11.2万亿的非合成数据 。 作为最新估值直飙2500亿元的国民级社交内容平台 , 小红书试图证明的是:通过高效的设计和高质量的数据 , 可以扩展大型语言模型的能力边界 。
根据小红书hi lab团队(Humane Intelligence Lab , 人文智能实验室)公布的技术报告 , 其主要贡献总结如下:
1、增强的数据处理:团队提出了一个可扩展且细粒度的三阶段数据处理框架 , 旨在生成大规模、高质量和多样化的数据 , 以进行预训练 。 完整的过程是开源的 , 以此增强可复现性 。
2、性能和成本效益:团队推出了dots.llm1开源模型 , 在推理过程中仅激活14B参数 , 同时提供全面且计算高效的性能 。 dots.llm1使用团队的可扩展数据处理框架生成的11.2万亿个高质量tokens进行训练 , 在各种任务中展示了强大的性能 , 所有这些都无需依赖合成数据或模型蒸馏即可实现 。
3、基础设施:团队引入了一种基于1F1B通道调度和高效的分组GEMM实现的创新MoE全对多通信和计算重叠配方 , 以提高计算效率 。
4、模型动力学的开放可访问性:通过以开源形式发布中间训练检查点 , 团队的目标是使研究界能够透明地了解训练过程 , 从而更深入地了解大型模型的动力学 , 并促进LLM领域的加速创新 。
Hugging Face地址: https://huggingface.co/rednote-hilab GitHub地址: https://github.com/rednote-hilab/dots.llm1
01 性能打平Qwen2.5-72B , 仅需激活14B参数首先看下dots.llm1的模型效果 , 团队训练得到的dots.llm1 base模型和instruct模型 , 均在综合指标上打平Qwen2.5-72B模型 。
根据评估结果 , dots.llm1.inst在中英文通用任务、数学推理、代码生成和对齐基准测试中表现较好 , 仅激活了14B参数 , 与Qwen2.5-32B-Instruct和Qwen2.5-72B-Struct相比效果更好 。 在双语任务、数学推理和对齐能力方面 , dots.llm1.inst取得了与Qwen3-32B相当或更好的性能 。
具体来看 , 在英语表现上 , dots.llm1.inst在MMLU、MMLU-Redux、DROP和GPQA等问答任务中 , 与Qwen2.5/Qwen3系列模型相比具有竞争力 。
在代码性能上 , 该模型与Qwen2.5系列相比不相上下 , 但与Qwen3和DeepSeek-V3等更先进的模型相比仍有差距 。
在数学表现上 , dots.llm1.inst在AIME24上获得了33.1分 , 凸显了其在复杂数学方面的高级问题解决能力;在MATH500的得分为84.8 , 优于Qwen2.5系列 , 并接近最先进的结果 。
在中文表现上 , dots.llm1.inst在CLUEWSC上获得了92.6分 , 与行业领先的中文语义理解性能相匹配 。 在C-Eval上 , 它达到了92.2 , 超过了包括DeepSeek-V3在内的所有模型 。
对齐性能方面 , dots.llm1.inst在IFEval、AlpacaEval2和ArenaHard等基准测试中表现出有竞争力的性能 。 这些结果表明 , 该模型可以准确地解释和执行复杂的指令 , 同时保持与人类意图和价值观的一致性 。
02 采取MoE架构 , 11.2万亿非合成数据训练dots.llm1模型是一种仅限解码器的Transformer架构 , 其中每一层由一个注意力层和一个前馈网络(FFN)组成 。 与Llama或Qwen等密集模型不同 , FFN被专家混合(MoE)替代了 。 这种修改允许其在保持经济成本的同时训练功能强大的模型 。
在注意力层方面 , 团队在模型中使用了一种普通的多头注意力机制 。 在MoE层 , 团队遵循DeepSeek、Qwen的做法 , 用包含共享和独立专家的MoE层替换了FFN , 他们的实施包括为所有token激活128个路由专家和2个共享专家 , 每个专家都使用SwiGLU激活实现为细粒度的两层FFN 。 负载均衡方面 , 为了降低训练和推理期间的模型容量和计算效率 , 团队采用了一种与DeepSeek类似的辅助无损的方法;此外 , 团队还采用序列平衡损失 , 以防止任何单个序列中的极端不平衡 , 以此使dots.llm1在整个训练过程中保持良好的负载均衡 。
预训练数据方面 , dots.llm1.ins在预训练阶段使用了11.2万亿tokens的非合成数据 , 主要来自通用爬虫和自有爬虫抓取得到的Web数据 。
在数据处理上 , 团队主要进行了文档准备、基于规则的处理和基于模型的处理 。 其中文档准备侧重于预处理和组织原始数据;基于规则的处理旨在通过自动筛选和清理数据 , 最大限度地减少对大量人工管理的需求;基于模型的处理进一步确保最终数据集既高质量又多样化 。
其数据处理管道有两项关键创新 , 如下所示:
1、Web杂乱清除模型:为了解决样板内容和重复行等问题 , 团队开发了一种在生产线级别运行的轻量级模型 。 这种方法在清洁质量和计算效率之间实现了有效的平衡 , 代表了开源数据集中不常见的独特功能 。
2、类别平衡:团队训练一个200类分类器来平衡Web数据中的比例 。 这使其能够增加基于知识和事实的内容(例如百科全书条目和科普文章)的存在 , 同时减少虚构和高度结构化的Web内容(包括科幻小说和产品描述)的份额 。
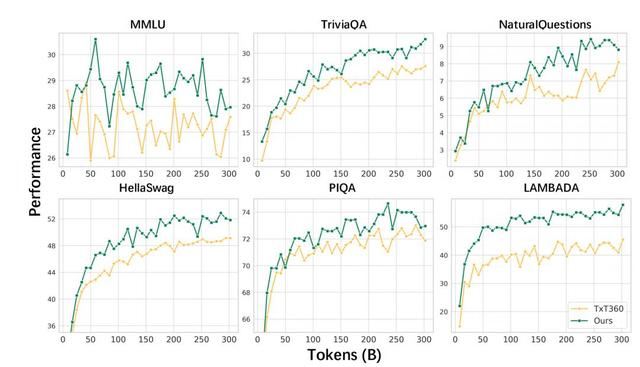
经过上述处理流程 , 团队得到一份高质量的预训练数据 , 并经过人工校验和实验验证 , 证明该数据质量显著优于开源Txt360数据 。
03 模型包含62层 , 序列长度扩展到32k在参数方面 , dots.llm1模型使用AdamW优化器进行训练 , 模型包含62层 , 第一层使用普通密集FFN , 后续层使用MoE 。
团队在预训练期间将最大序列长度设置为8k , 并在11.2T tokens上训练dots.llm1 。 在主要训练阶段之后 , 该过程包括两个退火阶段 , 总共包含1.2万亿个数据tokens 。
紧接着 , 团队在退火阶段之后实现上下文长度扩展 。 在这个阶段 , 他们在使用UtK策略对128B标记进行训练时保持恒定的学习率 , 将序列长度扩展到32k 。 UtK不是修改数据集 , 而是尝试将训练文档分块成更小的片段 , 然后训练模型以从随机分块中重建相关片段 。 通过学习解开这些打结的块 , 该模型可以有效地处理较长的输入序列 , 同时保持其在短上下文任务上的性能 。
【小红书开源首个大模型,中文评测超越DeepSeek-V3】在预训练完成后 , 为了全面评估dots.llm1模型 , 团队将该模型在中文和英文上进行了预训练 , 团队评估了它在每种语言中跨越多个领域的一套基准测试中的性能 。 如下图所示 , 与DeepSeek-V2相比 , 只有14B激活参数的dots.llm1性能更佳 , 后者与Qwen2.5-72B水平相当 。
dots.llm1在大多数域中表现出与Qwen2.5-72B相当的性能:1、在语言理解任务上 , dots.llm1在中文理解基准测试中取得了较高性能 , 主要得益于数据处理管道 。 2、在知识任务中 , 虽然dots.llm1在英语知识基准上的得分略低 , 但它在中文知识任务上的表现仍然稳健 。 3、在代码和数学领域 , dots.llm1在HumanEval和CMath上获得了更高的分数 。 有趣的是 , 在数学方面 , 我们观察到dots.llm1在零样本设置下的性能比少数样本设置要好 , 提高了4个百分点以上 。
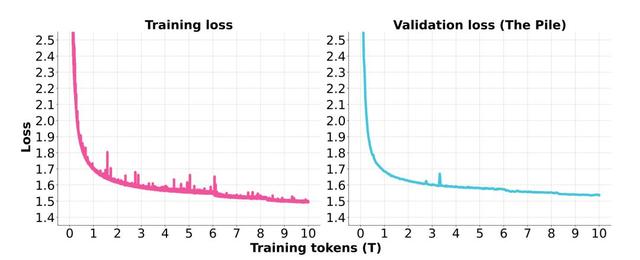
以下损失曲线突出了训练过程的一致稳定性 。 在6万亿个训练token中 , 团队将批处理大小从6400万个调整为9600万个 , 从8.3万亿次增加到1.28亿次 。 在整个训练期间 , 没有出现无法恢复的损失峰值事件 , 也不需要回滚 。
在预训练及评估后 , 团队在后训练阶段对模型进行了监督微调 。
在数据混合方面 , 其基于开源数据和内部注释数据收集了大约400k个指令调优实例 , 主要集中在几个关键领域:多语言(主要是中文和英文)多轮对话、知识理解和问答、复杂的指令跟随以及涉及数学和编码的推理任务 。
在微调配置方面 , dots.llm1.inst的微调过程包括两个阶段 。 在第一阶段 , 团队对400k指令调优实例执行上采样和多会话连接 , 然后对dots.llm1.inst进行2个epoch的微调 。 在第二阶段 , 其通过拒绝采样微调(RFT)进一步增强模型在特定领域(如数学和编码)的能力 , 并结合验证器系统来提高这些专业领域的性能 。
04 结语:用高质量数据扩展大模型边界可以看到 , dots.llm1定位是一种经济高效的专家混合模型 , “以小博大” 。 通过仅激活每个标记的参数子集 , dots.llm1降低训练成本 , 试图提供了与更大的模型相当的结果 。
相比于同行 , 小红书认为自己的一大优势是数据处理管道 , 可助其生成高质量的训练数据 。 Dots.llm1证明了高效的设计和高质量的数据可以不断扩展大型语言模型的能力边界 。
推荐阅读










- AlmaLinux:红帽生态的开源平替之王 \uD83C\uDF1F
- 开源鸿蒙电脑来了,这次不是华为,鸿蒙大生态要加速了?
- 虎扑5亿卖了,小红书260亿美元估值还在涨
- 彩色墨水屏清晰又护眼,这款国产小众智能机,阅读效果像真实书本
- 携手小红书,Kimi开始押宝“AI+内容社区”
- Meta、Cisco 将开源大语言模型置于下一代 SOC 工作流核心
- 超越DeepSeek-R1英伟达开源新王登顶!14万H100小时训练细节曝光
- 开源鸿蒙 OpenHarmony 5.1.0 的全场景进化
- 华为迎来双喜:开源鸿蒙5.1.0发布,鸿蒙PC即将亮相!
- 首款面向开发者的开源鸿蒙PC亮相:芯片、软件全国产