
文章图片
文章图片
文章图片

文章图片
文章图片
文章图片
机器之心报道
【OpenAI久违发了篇「正经」论文:线性布局实现高效张量计算】编辑:Panda
OpenAI 发论文的频率是越来越低了 。
如果你看到了一份来自 OpenAI 的新 PDF 文件 , 那多半也是新模型的系统卡或相关增补文件或基准测试 , 很少有新的研究论文 。
至于原因嘛 , 让该公司自家的 ChatGPT 来说吧:「截至目前 , OpenAI 在 2025 年在 arXiv 上公开发布的论文数量相对较少 , 可能反映了其对研究成果公开策略的谨慎态度 , 可能出于商业保密或安全考虑 。 」
不过近日 , OpenAI 也确实发布了一份完全由自己人参与的、实打实的研究论文 , 其中提出了一种用于高效张量映射的统一代数框架 Linear Layouts 。 这是一种使用二元线性代数而非比特表示(bit representation)的张量布局的通用代数形式 , 解决了 Triton 等深度学习编译器中长期存在的难题 。
- 论文标题:Linear Layouts: Robust Code Generation of Efficient Tensor Computation Using ?
- 论文地址:https://arxiv.org/pdf/2505.23819.pdf
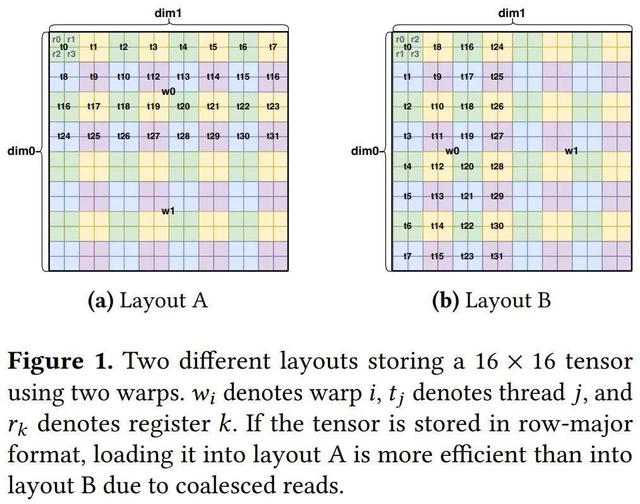
简单来说:张量布局 = 逻辑张量与硬件资源(例如内存、线程、向量单元)之间的映射关系 。 下图给出了两个布局示例 。
对于现代深度学习工作负载而言 , 所需要的张量布局需要满足几个要求:
- 高效(为了性能) 。
- 灵活(以支持多种算子) 。
- 可组合(为了变换和优化) 。
- 需要根据实际需求设计 , 而且往往是硬编码的(需要手动编写规则) 。
- 不可扩展(每一对布局都需要二次组合) 。
- 容易出错 , 尤其是在像 Triton 这样的低层级的后端中 —— 截至目前 , Triton 的 GitHub 库中提交的 12% 的 Bug 与布局有关 。
例如 , 为了实现高效的矩阵乘法 , 英伟达在 Ampere、Hopper 和 Blackwell 等不同代际的 GPU 上采用了不同的使用 Tensor Core 的布局 , 并且每种布局在使用不同数据类型时都有不同的变体 。 AMD 和英特尔等其它 GPU 供应商在利用其类似 Tensor Core 的技术进行加速时 , 也使用了不同的布局 。 因此 , 硬件架构的快速发展和多样化的深度学习模型需要一种新的张量布局建模方法 。
为此 , 需要解决一些技术难题:
- 在将张量映射到硬件资源方面 , 需要一种通用且可组合的表示方法 。
- 布局转换应该用统一的形式来表达 , 甚至需要包含诸如数据交换(data swizzling)等复杂变换 。
- 这种表示必须与低级硬件优化无缝集成 , 以确保高效的数据访问和计算 。
相关背景知识
GPU 架构
在设计上 , 现代 GPU 的目标是通过包含多层硬件资源的分层执行模型来充分利用并行性 。
其关键执行单元包括协作线程阵列 (CTA)、Warp 和线程 。 每个 GPU 线程都可以访问私有寄存器 —— 这些寄存器提供最低延迟的存储空间 , 但容量有限 。 常规指令可以由各个线程独立执行 。 然而 , 某些特殊功能单元必须在更高的粒度级别上执行 。
例如 , 英伟达的 mma(矩阵乘法累加)指令利用 Tensor Core 的方式是并行执行由各个 Warp 发出的多个乘加运算 。 而 wgmma(Warp 组矩阵乘法累加)等高级变体则是通过在多个 Warp 上同时执行矩阵乘法而对这些功能进行了扩展 。 AMD 也引入了类似的原语 , 例如 mfma(矩阵融合乘加)指令 。
请注意 , 这些指令要求数据分布在线程和 Warp 之间 , 或者以特殊布局驻留在共享内存或特殊内存单元(例如 Blackwell 上的 Tensor Memory)中 , 才能产生正确的结果 。
然而 , 这些布局通常不会为加载 / 存储等其他操作带来最佳性能 , 而且并非总是可以使用特定指令将数据直接从全局内存复制到特殊内存单元 。
因此 , 通常必须对数据进行重新排列 , 以便将用于内存访问的布局转换为计算单元偏好的布局 。
简而言之 , 要实现峰值性能 , 不仅需要利用这些专用单元 , 还需要精心设计张量布局和转换 。
Triton 语言和编译器
Triton 是一种类似于 Python 的用于特定领域的语言 , 其设计目标是提供用于编写高性能深度学习原语的灵活接口 。 Triton 的编译器后端使用了 MLIR , 支持多层次抽象表达 。
究其核心 , Triton 内核遵循单程序多数据 (SPMD) 模型 , 其中计算被划分为多个抽象的 Triton 程序实例 。 这种设计允许开发者主要关注 CTA 级别的并行性即可 。 在 Triton 中 , 「张量」一词指的是从原始 PyTorch 张量中提取的块 , 它们用作 GPU 核的输入和输出 。
在编译过程中 , Triton 的 Python 代码首先被翻译成 Triton 方言 (tt) , 然后进一步翻译成 TritonGPU 方言 (ttg) 。 在此过程中 , 每个张量都与特定的布局相关联 , 以充分利用现代 GPU 上可用的硬件功能单元 。 例如 , 当遇到 dot 类算子(例如 tt.dot 和 tt.dot_scaled)时 , 会采用 mma 布局并使用 Tensor Core 和类似的单元 。
传统布局
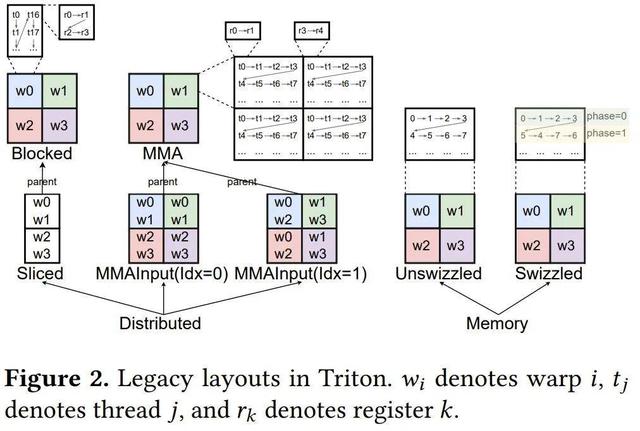
图 2 列出了 Triton 中所有可用的布局 。
在最高层级 , 布局分为分布式(Distributed)布局和内存((Memory)布局 。 前者是指张量元素分布在不同的执行单元中 , 而后者是指张量元素存储在特定的特殊内存中 。
分布式布局又可进一步分为 Blocked、Sliced、MMA 和 MMA Input 布局等类型 , 而内存布局又可进一步分为 Unswizzled 和 Swizzled 布局 。
Blocked 布局通常用于连续的内存访问 。 MMA 和 MMA 输入布局用于矩阵乘法运算(例如 tt.dot)的输出和输入 。 MMA 布局可以根据其映射到的硬件指令进一步分类 , 例如英伟达 GPU 上的 mma 和 wgmma , 或 AMD GPU 上的 mfma 。 Sliced 布局是从其父布局中提取一个维度 , 用作广播或某个归约运算的输出 。
传统 Triton 布局系统要求每个布局定义自己的接口方法 , 例如每个线程的元素数量和连续元素的数量 。 此外 , 必须为每个布局显式实现对张量元素的索引以及布局之间的转换 。 这种方法导致布局构造和转换常出现 bug 。
Linear Layouts(线性布局)
下面将简单介绍线性布局的定义、一些基本的线性布局算子、创建各种 Triton 布局以作为线性布局实例 , 以及应用于 Triton 的通用布局引擎 。
一个示例
在 GPU 编程中 , 大多数参数都是 2 的幂:一个 Warp 由 32 或 64 个线程组成 , 一个 Warp 组包含 4 个 Warp , 矩阵乘法内联函数(例如 mma 和 wgmma)要求 Tile 尺寸为 16 ×, 其中 ≥ 1 。
此外 , 在 Triton 的编程模型中 , 张量的维度以及与每个张量相关的布局子部分(例如每个线程的寄存器和线程数量)都被限制为 2 的幂 。 在图 1 中 , 布局 A 有一个 16 × 16 的张量 , 其使用了多个 2 × 2 的寄存器、4 × 8 的线程和 2 × 1 的 Warp 。
由于这些量都是 2 的幂 , 因此使用其坐标的比特表示 , 可以直观地可视化布局 A 中元素的分布(如图 1 所示) 。 所有线程的寄存器 0 (_0) 都位于坐标 ( ) , 其中 和 的最后几位(bit)均为 0 。 例如 , 线程 _1 的 _0 位于 (0 2) = (000 010) 。 作为对比 , _1 元素的坐标中 ,的最后一位始终为 0 , 而 的最后一位始终为 1 。 例如 , _9 的 _1 位于 (2 3) = (010 011) 。
此外 , 对于任何偶数线程 _ ,的最后一位与 _0 中 的倒数第二位匹配 ,的倒数第二位与 _0 中 的倒数第三位匹配 。 例如 , _10 = _01010 的 _0 位于 (2 4) = (010 0100) 。 这种系统性对齐持续存在 , 表明二次幂结构足以清晰地决定了每个线程元素的分布 。
综上所述 , 假设一个大小为 8 的向量 表示一个 Warp 中线程的一个元素 , 其中前 2 位表示寄存器 (Reg) , 接下来的 5 位表示线程 (Thr) , 最后一位则表示 Warp (Wrp) , 则可以如此定义布局 :
当需要从逻辑张量的坐标中恢复硬件索引时 , 需要使用求逆运算 。
对线性布局的更详细完备性说明请访问原论文 , 其中涉及到说明分块布局、mma 和 wgmma 的输入和输出布局、线性布局的 slice、每个分布式布局、MMA swizzled 布局、内存布局都是线性布局 。 另外 , OpenAI 也在 Triton 说明了如何实现布局转换以及形状操作 。
不仅如此 , OpenAI 表示 , 线性布局为在语言前端和编译器后端开发算法提供了结构化的基础 。 他们也在论文中给出了一些关键示例 , 这里就不过多展开 。 接下来简单看看新提出的线性布局的实际表现 。
评估
OpenAI 将优化版 Triton(集成了基于线性布局的优化 , 即 Triton-Linear)与未集成这些优化的基准 Triton 进行了比较 。 Triton 和 TritonLinear 之间的主要区别如下:
- Triton 使用传统的数据布局 , 不支持任意分布式布局的实用程序或它们之间的转换 , 因此容易出现 bug 。
- Triton 未采用论文中描述的优化代码生成 。 例如 , 布局转换始终通过共享内存进行 , 对高效硬件原语的使用有限 。
为了比较 Triton 和 Triton-Linear 的性能 , 该团队构建了一些合成微基准来进行测试 , 这方面的结果请访问原论文查看 。 这里仅看看它们在实际基准测试中表现 。
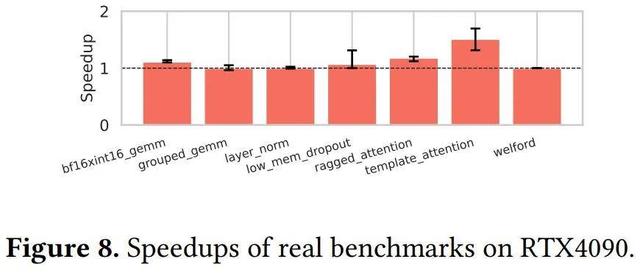
在三个不同的平台上 , OpenAI 运行了 TritonBench 中的 18 个基准测试 。 图 7、图 8 和图 9 中展示了 Triton-Linear 在三个平台上的性能提升 。
由于每个基准测试包含多个输入 , 总计 420 个案例 , 因此他们使用了误差线(error bars)来表示每个基准测试的最小和最大加速 。
需要注意的是 , 由于硬件限制 , 并非所有基准测试都适用于每个平台 。 例如 , 某些基准测试需要仅在 GH200 上才有的大型共享内存 , 而一些核使用的张量描述符依赖于 TMA 引擎 , 而 RTX4090 和 MI250 上均不支持 TMA 引擎 。
可以看到 , 在 GH200 上 , 他们实现了 0.92 倍到 1.57 倍不等的加速 , 所有基准测试的平均加速均超过 1.0 倍 。 加速最显著的基准测试是 int4_gemm、ops_gemm 和 streamk_gemm 。
可以观察到 , 高效的硬件原语(例如 ldmatrix 和 stmatrix)在这些核中被广泛用于布局转换以及共享内存的加载和存储操作 。 值得注意的是 , layer_norm 实现了从 0.99 倍到 1.57 倍的加速 —— 在不同形状之间表现出了显著差异 。 对于某些输入形状 , Triton-Linear 能够检测「等效」布局之间的转换 , 从而将转换过程降低为 no-op(无操作) 。 这种优化在旧版布局系统中无法实现 , 因为它无法直接比较不同类型的布局(例如 , Blocked 布局和 Sliced 布局) 。
在 RTX4090 上 , 新方法实现了 1.00 倍到 1.51 倍的加速 。 由于 mma (RTX4090) 和 wgmma (GH200) 指令之间的差异 , 他们在 template_attention 上实现了更高的加速 。 在本例中 , tt.dot 运算的左操作数在循环外部定义 , 会重复从同一地址加载数据 , 因此 ldmatrix 和常规共享内存指令均可实现高吞吐量 。 虽然右操作数在每次迭代中都会更新 , 但 wgmma 会直接在共享内存中访问它 , 只有在 RTX4090 上 , 经过优化后 , 它才会被降级到 ldmatrix 中 。 因此 , 在 GH200 上实现的加速相对较低 。 在 MI250 上 , 新方法实现了 0.98 倍到 1.18 倍的加速 。
总体而言 , 由于缺乏 ldmatrix 等高效的硬件原语 , Triton-Linear 在 AMD GPU 上实现的加速低于在英伟达 GPU 的 。
对于 OpenAI Open 的这个研究 , 你有什么看法呢
推荐阅读












- 即将发布的5款新机,每一款都很有看点!你最期待哪一款?
- 最新发现!每参数3.6比特,语言模型最多能记住这么多
- 多模态扩散模型开始爆发,这次是高速可控还能学习推理的LaViDa
- 英特尔证实数代处理器正在研发:覆盖不同领域
- 发布2025年度隐私保护广告,苹果重申领先地位
- 国产Top5厂商开始发力:四摄设计+外挂镜头,手机影像迎来新时代!
- 三星电子计划下月引入AI编程助手 以提高软件开发效率
- 任正非发声:芯片的问题没必要担心
- 谷歌CEO皮查伊:AI才发展到AJI阶段,实现AGI还需20年以上
- AMD 25.6.1正式版显卡驱动发布:FSR 4游戏爆发式增长14款