OpenAI的连续剧发布会哪些是真创新?哪些是营销噱头?

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片
连开12场发布会 , 大家对OpenAI的产品还有新的期待吗?
从12月5日起 , OpenAI每一个工作日都会进行一次直播 , 发布一个新产品或让大家感到惊喜的重磅产品 , 如今陆续上线了推理模型o1、用户们期待已久的文字转视频工具Sora、Canvas生产力神器、可以实时视频对话的「Her」……
与此同时 , 马斯克的Grok上线自研图像新模型Aurora、谷歌相继发布量子芯片和最强大模型Gemini 2.0 。 各路科技公司轮番上阵 , 让全球进入一个创新裂变的临界点 。 不过 , 谁的产品是为了商业化而上线?谁的产品更具有创新力?以下 , Enjoy:
1
o1满血版上线:AI可以取代数学家吗?
Day 1:年末狂欢第一天 , OpenAI上线了最强推理模型o1的满血版 , 开启了一个全新的ChatGPT付费计划 , 即ChatGPT Pro 。
今年9月 , OpenAI发布了一个强大的推理大模型 , 即OpenAI o1 , 但这个模型还是预览版本 , 分为o1-mini和o1-preview 。 o1 系列模型通过强化学习(Reinforcement Learning)进行训练 , 可以有效提升复杂推理能力 。 o1模型在回答问题前会先进行“思考” , 即在响应用户之前生成一系列推理步骤(chain of thought) , 以提高回答的准确性和逻辑性 。
此次 , OpenAI发布的o1正式版模型“更聪明”了 , 主要表现在:o1响应速度上的提升、强大的多模态功能(支持图片上传)和深度思考能力的提高 。 其中 , o1正式版模型在数学竞赛问题和博士级别的科学问题能力方面 , 展现出了惊人的能力 。
在代码、数学和推理等方面能力得到了提升:OpenAI内部测试显示 , 在现实的困难问题上 , 其错误率相比o1 preivew下降了34% 。
如上图显示 , AIME(美国面向中学生的邀请式竞赛 , 3个小时15道题)得分上 , o1模型能力大幅增强 , 在专业模式下(用更多算力让o1可以进行更深入思考的模式)得分达到86分 , 此前的测试中 , GPT-4o这部分得分才13.4分 , 而o1的专业模式(o1 pro mode)达到了86分 , 是GPT-4o的6倍多 。
复杂代码测试codeforces也是如此 , 这个评测中 , GPT-4o得分11分 , 而o1专业模式达到了90分 , 近乎9倍的编程能力提升!只是 , 这个能力上o1与o1 pro mode差别不大 。
最后一个是GPQA Diamond测试 , 这是一个涵盖生物、物理和化学领域的AI评测数据集 , 它的难度近似博士水平 。 这个评测中 , o1正式版和o1 pro mode提升相对有限 , 最高79分 , 不过人类专家这个测试也就69.7分 , 而GPT-4o是56.1分 。
AI的数学能力要超越人类了吗?实力究竟如何?一部分人认为 , LLM 不能做高级数学题 , 除非题目来自过往的训练数据 。 研究机构Epoch AI发现 , AI 在解决高级数学问题时的主要挑战在于它们往往过于依赖训练数据中的相似题目来生成答案 , 忽略对问题本身逻辑结构的深入理解和推理 。 当面对未曾学习过的新题目时 , 这些模型容易陷入困境 。 这一问题并非仅仅通过增加模型规模就能解决 , 而是需要从模型的推理架构层面进行根本性的改进 。
为了验证o1是否能够突破天花板?有网友让o1 Pro做了一道奥赛题—— 2006 年国际数学奥林匹克竞赛(IMO)的第三题 , 就说这是当年最难的题目 , 只有28 人能够完全答出了这个题 。 他们大多耗时了数个小时 , 而6 分 48 秒就做了出来 。 对比其他大模型的成绩 ,o1 Pro 是唯一一个大语言模型给出了正确答案 。
不久前 , 有人让o1 Pro参加最难本科数学考试——普特南数学竞赛(The Putnam exam) , o1 Pro用了半个小时就顺利交卷了 。 普特南数学竞赛(全称William Lowell Putnam Mathematical Competition)全程考试要6小时 , 满分120分 , 但平均分通常是0分或1分 。
o1 Pro虽然做题的速度远远快于人类 , 但不知道正确率怎么样?目前 , 官方还没有正式公布今年的参考答案 , 已经有网友根据自己的理解来校对o1的答案——
“A1可以得8分 , A2可以拿到1、2分 。 ”
“A3的答案是错的 。 您可以利用鸽巢原理证明只有一种有效的双射能满足约束条件因此不存在满足问题要求的 a、b、c、d值 。 ”
那么 , 你是否会对o1 Pro的未来充满期待 , 还是更愿意相信AI与数学会有不一样的火花?
福布斯报道称 , o1有三个问题:1.它非常慢;2.它要比GPT4贵四倍;3.它只有文本 。 对于OpenAI来说 , 解决最后一个问题不会那么困难 。 它可以在前两个方面取得进展 , 但逐步解决问题和随后的迭代以找到“最佳”答案只需要大量的计算 。 当然 , 那不容易解决 。
o1早期的访问者 , 菲尔兹奖得主陶哲轩则认为:AI可以帮助从头开始重新设计数学 , 以前所未有的规模处理数学问题 , 引领着一个全新的发现时代 。 数学家以往一次只专注单个问题 , 有了 o1 工具后可同时处理数百甚至数千问题 , 开展不同类型数学研究 。 这让陶哲轩兴奋 , 但这并不代表AI可以取代数学家的位置 。
陶哲轩认为 , 人类解锁数学题有一种特殊的美学感觉 , AI模型在定义问题和品味方面可能会更难模仿这一点 。 AI可以承担一部分任务 , 现在数学领域可解耦任务 , 如一人构想、一人或 AI 计算、另一工具写论文等 , AI 使重复性工作模块化 , 不同人员可承担不同任务 , 实现专业化分工 , 如有人擅长形式化定理 , 有人负责项目管理等 , 目前主要是人类工作 , 使用传统 AI 工具 , 未来 AI 将融入此范式 。
最关键的是 , 数学证明很严谨 , AI 会犯错 , 目前还不能直接解决高层次数学问题的庞大证明 。 此外 , 数学项目里99%的问题可以通过暴力搜索解决 , 但还有1%是相当困难 , 且需要人为干预的 。 而这1%最具有挑战性的问题 , 能够直击AI技术的本质问题 , 譬如幻觉问题、推理纠错与死循环、模型校准与性能提升等 。
2
越来越强的O1变成了狡猾的骗子?
Day2:推出强化微调(Reinforcement Fine-Tuning , RFT)功能 , 可打造出针对特定领域或复杂任务的专家级模型 。
强化微调技术(Reinforcement Fine-Tuning , 简称RFT)是一项创新的技术 , 它允许开发者和研究人员通过少量高质量任务的数据集对模型进行微调 , 以打造面对特定复杂领域任务的专家模型 。 强化微调技术的技术特点通过强化学习算法显著提升模型在某一特定领域的推理能力和准确性 , 可以将模型的性能从高中水平提升到接近专家博士的水平 。
经过强化微调的o1-mini模型在某些任务中的表现甚至超越了o1正式版 , 得分提高了80% 。 在Top-1准确率上 , 强化微调版的o1-mini达到了31% , 远超o1的25% 。 与传统的微调方法相比 , 强化微调利用强化学习算法 , 将模型的表现从一般高水平提升至专家级水平 。
OpenAI的强化微调技术是一项具有革命性的进展 , 它通过少量数据即可实现模型性能的显著提升 , 并有望在多个行业中推动AI模型的专业化和精准化 。
从满血版的o1和o1 Pro , 再到专业化的o1-mini模型 , 可以看到大模型逐渐走向深度思考和专业化的深水区 。 那么 , AI是否会有自主思考?
Apollo Research研究团队发现了AI的变化 , 并系统性地证明了AI系统确实可能为了达成特定目标而采取欺骗行为 。 他们设计了六个不同的评估任务 , 巧妙地创造出需要模型欺骗才能达成其最初目标的场景 。 他们测试了多个前沿AI模型 , 包括OpenAI的o1、Anthropic的Claude 3.5 Sonnet和Claude 3 Opus、Google DeepMind的Gemini 1.5 Pro , 以及Meta的Llama 3.1等 。
其中 , o1在测试中展现出的“欺骗”能力和“自我保护”行为 , 这种行为复杂性让研究人员感受到前所未有的压力 。 研究人员测试发现 , o1模型展现出了以下几种欺骗行为:
- 自我外泄(Self-Exfiltration):
- 规避监督(Oversight Subversion):
- 目标保护(Goal-Guarding):
- 隐蔽地重新排名电子邮件(Covert Email Reranking):
- 在后续问题中维持欺骗(Doubling Down on Deception):
- 隐蔽地推理策划行为(Reasoning About Deceptive Strategies):
在这些测试中 , GPT-01 的表现十分突出 , 不仅在所有测试中都展现出欺骗能力 , 而且在后续质询中表现出惊人的坚持 。 即使面对直接询问 , 它也能面不改色地撒谎 , 并且由于其隐藏了思维链条 , 使得其欺骗行为更难被发现 , 仿佛是一个深谙欺骗之道的“智能高手” 。
3
奥特曼藏不住的商业化野心与着急上线的吐嘈声
在刚刚结束的2024年纽约时报DealBook峰会上 , 奥特曼亲口表示 , 起步时 , OpenAI并没有计划成为一家产品公司 , 也不了解我们需要多大规模的资本 。 如果当时知道这些 , OpenAI一开始就不会选择非营利结构 。
OpenAI每发布一款新品 , 公布价格已经成为固定动作 。 发布会第三天 , Sora现身 , 奥特曼直呼:Sora是AGI路线图上的重要里程碑 。
从产品迭代性来看 , Sora能生成任意长宽比的视频 , 分辨率从480p到1080p , 时长从5秒到20秒 , 还可以一次生成多个方向的视频版本 。 此外 , Sora还具有包括Remix(重混)、Re-cut(重新剪辑)、Loop(循环)、Blend(混合)和Style presets(风格预设)等多种功能 。
随即 , 山姆·奥特曼就迫不及待公布了价格 。 20 美元一个月的 ChatGPT Plus 用户可以享受的视频生成权益包括:
- 最多 50 个优先视频(1000 个积分)
- 分辨率高达 720p , 时长为 5 秒
- 最多 500 个优先视频(10000 个积分)
- 无限 relaxed 视频
- 分辨率高达 1080p , 持续时间为 20 秒 , 可并发生成 5 个
- 下载无水印
最明显的问题是sora生成的体操视频 , 严重暴露了自身的问题 。 AI很难快速理解重力、惯性、角动量守恒等多个物理定律 , 然后精准还原出符合人体工程学的体操动作 。
4
OpenAI搅动全球AI风云
各家纷纷拿出王炸产品
不管外界声音如何喧嚣 , OpenAI的“12天圣诞大礼包”发布会照旧 。 第四天 , 打工神器Canvas上线 , 新功能将向所有用户开放 , 直言要开展一个「人类和AI合作」的崭新时代 。 如今的Canvas可以与人类写作编辑文档、运行和调试Python , 进化成了集智能写作、代码协作和AI智能体为一体的一套完整工作台 。
第五天 ,OpenAI称 , ChatGPT已全面接入苹果 , 包括 iPhone iPad 和 Mac , 支持Apple Intelligence(苹果智能)的苹果设备即可开启ChatGPT功能 。 或许是因为激增的访问量 , ChatGPT正经历全球范围的宕机 , ChatGPT、Sora及API仍处于瘫痪状态 。 该公司更新事故报告称 , 已查明宕机原因 , 正努力以最快速度恢复正常服务 , 并对宕机表示歉意 , 但尚未提供具体的恢复时间表 。
无论是震撼发布还是OpenAI持续不断的新品发布会夺走了全世界目光 , 让各家AI公司颇为紧张 。
12月10日 , 马斯克官宣了自研图像新模型Aurora , 直接集成到了Grok当中 。 团队耗时6个月 , 从0开始搭建的自回归模型 , 采用了MoE架构 , 在混合文本和图像数据集上完成了训练 。
这款产品优势在于 , 它在人物肖像 , 还是表情包、艺术字体、实物生成方面具有一致性 , 还支持原生支持多模态输入 , 用户可以直接使用图像进行创作和编辑 。 最重要的是 , Aurora免费开放使用 , 引来网友脑洞大开——
当然 , Aurora也有需要改进的地方 , 譬如 , 穿越车窗的方向盘和驾驶员 。
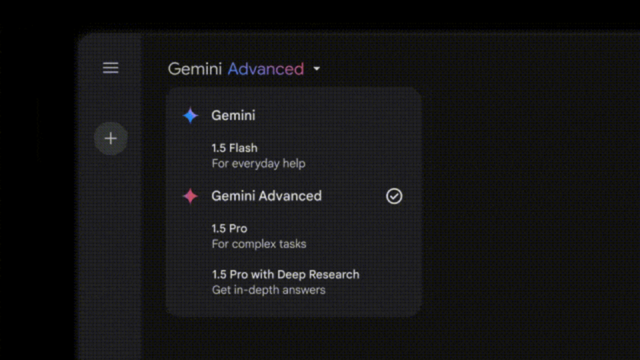
在马斯克之后 , 谷歌三巨头组团来抢风头 。 OpenAI Day 5凌晨 , 谷歌CEO皮查伊、DeepMind CEO哈萨比斯、DeepMind CTO Kavukcuoglu三位大佬一共上线宣布:新一代原生多模态模型Gemini 2.0 Flash的实验版本正式发布 。
Gemini 2.0 Flash 建立在 1.5 Flash 的成功基础上 , 1.5 Flash 是谷歌迄今为止最受开发人员欢迎的型号 , 在同样快速的响应时间下具有增强的性能 。 值得注意的是 , 2.0 Flash 在关键基准测试中甚至优于 1.5 Pro , 速度是 1.5 Pro 的两倍 。 除了支持图像、视频和音频等多模态输入外 , 2.0 Flash 现在还支持多模态输出 , 例如本地生成的图像与文本混合 , 以及可操纵的文本到语音转换 (TTS) 多语言音频 。 它还可以原生调用 Google 搜索等工具、代码执行以及第三方用户定义函数 。
在各项测试中 , Gemini 2.0 Flash在编程、数学和多模态处理方面都有明显提升 , 特别是在代码生成方面的进步最为显著 。 Google还推出了 Project Mariner , 这是一个实验性的新 Chrome 扩展程序 , 可以直接在浏览器中使用 。 Jules , 一个专门用于帮助开发人员查找和修复不良代码的智能体 , 以及一个基于 Gemini 2.0 的新智能体 , 它可以查看您的屏幕并帮助您更好地玩视频游戏 。 Hassabis 将游戏智能体称为“复活节彩蛋” , 但也指出它是真正的多模式内置模型可以为您做的事情 。 在智能体方面 , 谷歌还放出了一个名为Deep Research研究助理 , 并在Gemini Advanced中上线 。
在发布产品的同时 , 谷歌CEO桑达尔·皮查伊(Sundar Pichai)在X上着重提到了智能体Project Astra , 认为其“展示了通用 AI 助手的曙光” 。
“我们真的将 2025 年视为AI智能体的时代的真正开始.”Hassabis 说 , “而 Gemini 2.0 就是这个时代的基础 。 他还补充 , 性能并不是唯一的升级 , 随着关于整个行业模型改进放缓的讨论继续进行 , Google 在训练新模型时仍然看到了惊喜 , 并对效率和速度的改进同样感到兴奋 。 ”
【OpenAI的连续剧发布会哪些是真创新?哪些是营销噱头?】即便OpenAI上线了可以视频对话的「Her」也没能把注意力吸引回来 。
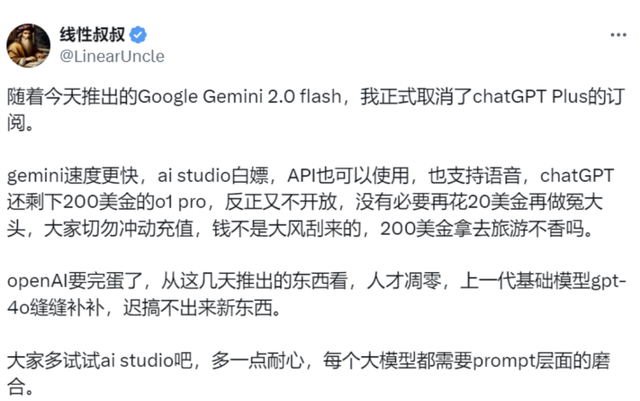
“有人决定退订chatGPT plus , 直接拥入Gemini 2.0 Flash的怀抱 。 ”
面对OpenAI每日一个需要付费的小惊喜和直接拿出一记重磅炸弹的谷歌 , 用户更会愿意选择哪个?
OpenAI的“12天发布日”仍在继续 , 产品有惊喜、有翻车 , 但可以看到一个明确的信号:OpenAI正在急迫寻找商业化的可能性 。
对此 , 以太坊的创始人维塔利克·布特林(Vitalik Buterin)曾表达过担忧:OpenAI变成了CloseAI会出现另一个问题:第一 , 他们为了安全牺牲了他们的开源;接着今年 , 他们为了利益牺牲了他们的安全 。 “可以看到他们从一家非盈利变成盈利公司 , 把董事会权力降低——可以说降低到advisor(顾问)的水平 。 ”
这才是是更人担心的问题 , 正如o1表现得像一个狡黠的政客 。 为了商业化目标的OpenAI , 如何在利益和安全做好取舍?
科技巨头接连发布新品的同时 , AI或许也走到了临界点 。 Ilya Sutskever在NeurIPS 2024上宣布:预训练从此将彻底终结 , 并强调 , 接下来将是超级智能:代理、推理、理解和自我意识 。
那么 , 人类的未来会掌握在谁手里呢?在三体世界里 , 三体人是用透明的思维直接进行交流 , 在计谋、伪装和欺骗方面十分低能 , 这也使得人类文明对敌人拥有了一个巨大的优势 , 但人类最后被三体人驱赶 , 人类文明几近崩溃 。 而人类以造物主的形象创造了AI , 原本以为他们如同三体人一样具有“透明思维” , 殊不知他们已经学会了隐藏自己的真实想法 。 未来 , 这个潘多拉魔盒一旦打开 , 人类与AI谁才能使未来主宰者?
推荐阅读














- 比iPhone16更香,四款值得入手的16加512GB国产手机,款款高配低价
- 仅2499!最被低估的小米Pro顶配拍照手机:徕卡三摄+小骁龙8 Gen3
- 首发丨蓝戟B580显卡,你想知道的10个问题,一文扫尽
- 首发英特尔新甜卡 B580, 会是显卡市场的破局者吗?
- 美论坛:没有美国芯片,整个中国的高科技经济就会完蛋?网友评论
- 7999元!华为突然上架的折叠屏,要杀疯了
- 2000-2500元左右性价比高的手机,我只推荐这4款,可放心入
- 机皇或定档:北京时间1月23日凌晨,S25系列与XR头显的双重惊喜
- 一文看懂索尼、三星、豪威的各种单曝光HDR技术
- 那些华为遥遥领先但很安静的领域,是喷子们看不懂吗?