
文章图片
文章图片
全新RISC-V系列瞄准从边缘到数据中心的AI主导地位 。
RISC-V 计算领域的领导者 SiFive 推出了其第二代智能系列处理器 , 这是在广泛应用中加速人工智能工作负载的重大进步 。
新系列包含五款基于 RISC-V 的产品 , 其中有全新的 X100 系列(X160 Gen 2 和 X180 Gen 2) , 还有升级的 X280 Gen 2、X390 Gen 2 以及 XM Gen 2 产品 , 这些产品适用于高性能边缘和数据中心场景 。
通过这些新系列 , SiFive 旨在把握人工智能解决方案需求快速增长的机遇 。 德勤预测 , 各技术环境中人工智能解决方案的需求将至少增长 20% , 其中人工智能边缘计算的增长尤为显著 , 将达到 78% 。
全新的 Intelligence 系列致力于增强标量、矢量以及 XM 系列的矩阵处理能力 , 以满足现代人工智能工作负载的需求 。 SiFive 首席执行官 Patrick Little 强调了人工智能的关键作用 , 他表示:“人工智能正在催生 RISC-V 革命的新纪元 。 ”
该公司的产品已在市场上获得广泛应用 , 两家美国一线半导体公司甚至在全新 X100 系列产品正式发布前就已获得授权 。 这些早期采用者将 X100 IP 用于两种不同的场景:一种是将 SiFive 标量矢量核心与矩阵引擎搭配 , 用作加速器控制单元;另一种是将矢量引擎用作独立的人工智能加速器 。
为人工智能处理的未来而创新SiFive 的第二代产品解决了人工智能部署中的关键挑战 , 特别是在内存管理和非线性函数加速方面 。 X 系列 IP 的一项核心创新是能够用作加速器控制单元(ACU) 。
它允许 SiFive 内核通过专用协处理器接口 , 即 SiFive 标量协处理器接口(SSCI)和矢量协处理器接口扩展(VCIX) , 为客户的定制加速器引擎提供必要的控制和辅助功能 。 这种架构能让客户专注于平台级别的数据处理创新 , 进而简化软件堆栈 。
SiFive 高级首席架构师 John Simpson 曾详细阐述过其相对于传统方法的优势 。 “传统行业采用的是固化的强化方法 , 你无法改变有限状态机 , ”Simpson 所指的是传统的加速器架构 。
他指出 , 在快速发展的人工智能领域 , “每周都会出现新的人工智能模型架构” , 固定的有限状态机无法适应新的架构类型 。 相比之下 , SiFive 的智能内核具备灵活性 , 通过允许在加速器芯片上进行本地处理 , 减少了系统总线流量 , 还促进了预处理和后处理任务的更紧密耦合 。
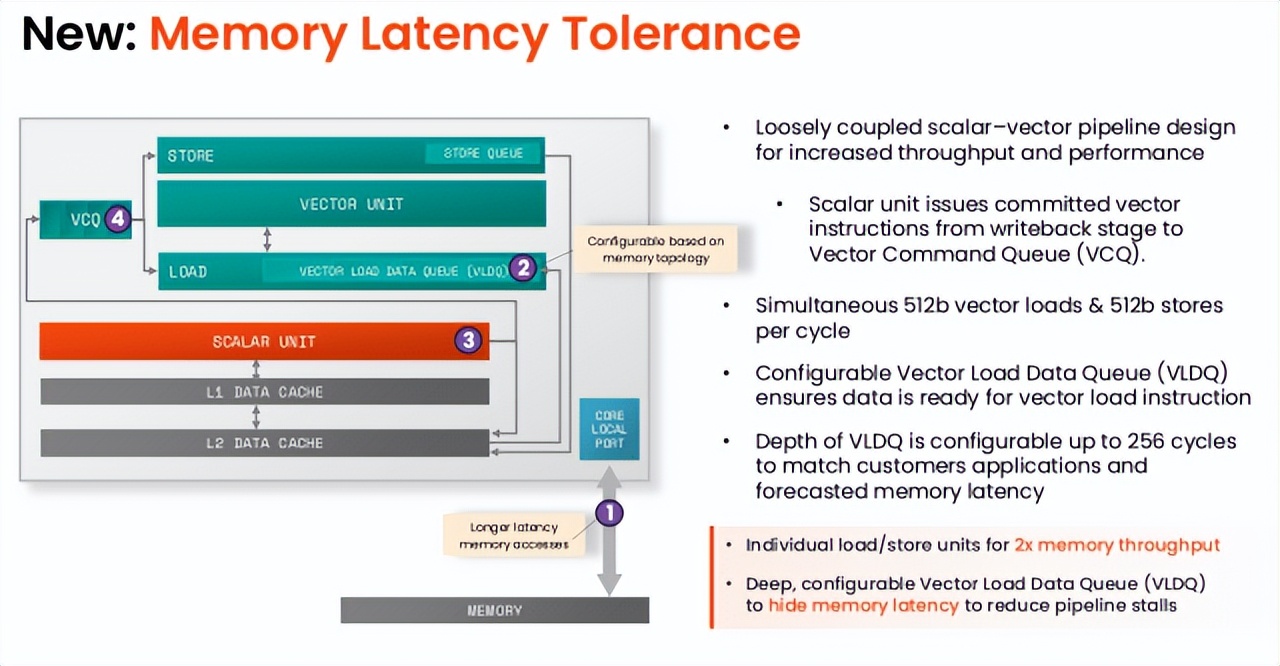
革命性的内存管理SiFive 在内存架构方面引入了两项重大进步 , 直接解决了性能瓶颈问题 , 分别是内存延迟容忍度提升和内存子系统效率优化 。
Simpson 对内存延迟容忍功能尤为自豪 , 这是一项巧妙的设计 , 能够隐藏加载延迟 。 他解释道 , 处理所有指令的标量单元会将已提交的矢量指令调度到矢量命令队列(VCQ) 。 关键的是 , 如果遇到矢量加载 , 其地址会在被放入 VCQ 的同时发送到内存系统(L2 或更高级别) 。
这种早期调度与执行分离的方式 , 允许内存响应返回并重新排序到可配置的矢量加载数据队列(VLDQ) 。 “这样做的目的是 , 加载操作将从矢量加载数据队列中获取正等待提取的数据 , ”Simpson 说 。
这确保了当加载指令最终从 VCQ 弹出时 , 数据已经准备就绪 , 从而实现 “矢量加载仅需一个周期” 。 Simpson 强调了这一竞争优势 , 他指出:“在 Hot Chips 上发布的至强处理器可处理 128 个待处理请求 , 这是至强处理器的最高水平 , 而我们的四核处理器能处理 1024 个请求 。 ” 这项 “精妙的技术” 有效防止了流水线停顿 , 保障了持续处理 。
更高效的内存子系统是另一项重大升级 , 它从包含式缓存层级结构转变为非包含式缓存层级结构 。 John Simpson 详细介绍了上一代包含式缓存系统 , 在该系统中 , 共享 L3 缓存中的数据会被复制到私有 L2 和 L1 缓存 , 导致 2.5 MB 等效总缓存的有效利用率仅为 40% 。
第二代设计消除了这种复制 。 “现在数据无需在任何地方复制 , ”Simpson 解释道 , 这使得 1.5 MB 等效空间的利用率达到了 100% 。
这意味着 “容量是第一代的 1.5 倍 , 面积利用率达到 60%” , 使其 “效率更高” 且 “轻松取胜” 。
除了内存方面的改进 , SiFive 还集成了全新的硬件流水线指数单元 。 虽然乘法累加器(MAC)在人工智能工作负载中占据主导地位 , 但指数运算将成为下一个主要瓶颈 。 例如 , 在由矩阵引擎加速的 BERT 大型模型中 , 涉及指数运算的 softmax 运算占据了剩余周期的 50% 以上 。
【SiFive发布第二代RISC-V IP】SiFive 的软件优化将指数运算函数从 22 个周期减少到 15 个周期 , 而新的硬件单元将其大幅精简为一条指令 , 使总运算时间缩短至 5 个周期 。 这种 “内置非线性加速” 对于最大限度地提高所有人工智能模型的加速效果至关重要 。
超大规模和全球影响力SiFive 的第二代 Intelligence 系列也正面向超大规模计算厂商 , 这些厂商正积极开发自己的定制芯片 。 尽管这些公司仍依赖 ARM 作为应用核心 , 但他们正积极将多个 SiFive XM 核心或自己的硬件矩阵引擎与 SiFive 的智能核心集成 , 以实现控制和辅助功能 。
这些超大规模企业怀揣着 “在数据中心取代英伟达(Nvidia)” 的雄心 , 其客户的目标是通过 XM 核心将性能水平提高到每秒 4 千万亿次浮点运算 。
该公司也认可中国快速发展的 RISC-V 生态系统 , 并指出整个 Intelligence 系列在从数据中心到边缘计算的各个领域都取得了重大设计成果 。 尽管由于保密协议 , 具体客户名称尚未公布 , 但 SiFive 表示 , 多家中国客户对其 IP 的需求十分强劲 。
第二代 Intelligence 系列强大的软件堆栈基于 SiFive 在 RISC-V 人工智能领域四年多的广泛投入 , 支持可扩展性 。 对于 XM 系列 , 机器学习运行时已能将工作负载分配到单芯片上的多个 XM 集群中 。 虽然扩展到单芯片以上需要进一步开发处理器间通信(IPC)库 , 但这仍是一个明确的路线图项目 , 其驱动力来自客户在单芯片上实例化多个 XM 的需求 。
SiFive 的全新 Intelligence 系列凭借创新的内存架构、专用接口和增强的处理能力 , 使 RISC-V 成为不断发展的人工智能硬件领域的重要参与者 , 为从最小的边缘设备到最大的数据中心 , 提供了无与伦比的灵活性和性能 。
*声明:本文系原作者创作 。 文章内容系其个人观点 , 我方转载仅为分享与讨论 , 不代表我方赞成或认同 , 如有异议 , 请联系后台 。
想要获取半导体产业的前沿洞见、技术速递、趋势解析 , 关注我们!
推荐阅读














- 红米15C正式发布:6000mAh+50MP双摄,新一代百元神机
- 佳能C50视频机与85mm F1.4L VCM镜头将一起发布
- 魅族新一代旗舰机官宣:9月15日,正式发布
- 苹果新品官宣:9月10日,全新发布
- iPhone17系列发布前瞻:外观、内存、价格、开售时间,全解析!
- 售价799元!2K+200Hz高刷屏,REDMI显示器G27Q 2026发布
- 全网都在玩的生图模型,我用它把 iPhone 17 提前发布了
- 谁才是耳机之王?索尼苹果BOSE拿走一半市场,华为冲到第二
- OPPO 美女产品经理 Monica 宣布离职 曾因发布会“高跟鞋踩机”引关注
- 事关5G、人工智能等今日上午将举行发布会