
文章图片

文章图片

文章图片
文章图片
文章图片

文章图片
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

文章图片
文章图片
文章图片

文章图片

编辑:桃子
【新智元导读】AI医疗 , 正成为全球科技巨头的必争之地!刚刚 , 百川智能第二款医疗增强大模型Baichuan-M2正式上线 , 首发即称霸全球医疗开源AI , 击败OpenAI开源模型gpt-oss-120b 。
在AI赛道上 , 医疗领域正成为全球科技巨头争夺的「C位」 。
想象一下 , 未来每个人兜里都能揣个「AI私人医生」 , 随时随地给出诊断 , 这个画面是不是超燃?
GPT-5发布会上 , 一个真实的故事 , 让所有人感受到了AI医疗的震撼力量 。
39岁Carolina在一周内 , 被诊断出三种癌症 , 面对晦涩的活检报告 , 她手足无措 。
当上传报告到ChatGPT后 , 几秒钟内 , 复杂的医学术语被翻译成浅显的语言 , 让Carolina在恐慌中找到了一丝头绪 , 对病情有了初步的了解 。
这个鲜活的案例 , 再次点燃了AI医疗的无限可能 , 也让人们看到技术如何赋能个体的深层意义 。
在这条万亿美金的赛道上 , 中国队再次出手了 。
今天 , 百川智能重磅发布Baichuan-M2 , 一款32B参数的医疗增强开源大模型 。
在基准测试中 , M2直接吊打OpenAI开源仅5天的gpt-oss-120b , 登顶全球开源医疗模型第一 。
而且 , 它还一举击败了除GPT-5之外的所有闭源模型 。
接下来 , 就来扒一扒这款「医疗卷王」的硬核实力 。
全球开源医疗王者 , C位出道
继14B参数M1之后 , Baichuan-M2是百川第二款医疗增强开源大模型 , 专为真实临床场景定制 。
通过端到端强化学习 , 它在保持通用能力的同时 , 医疗推理能力直接「起飞」 。
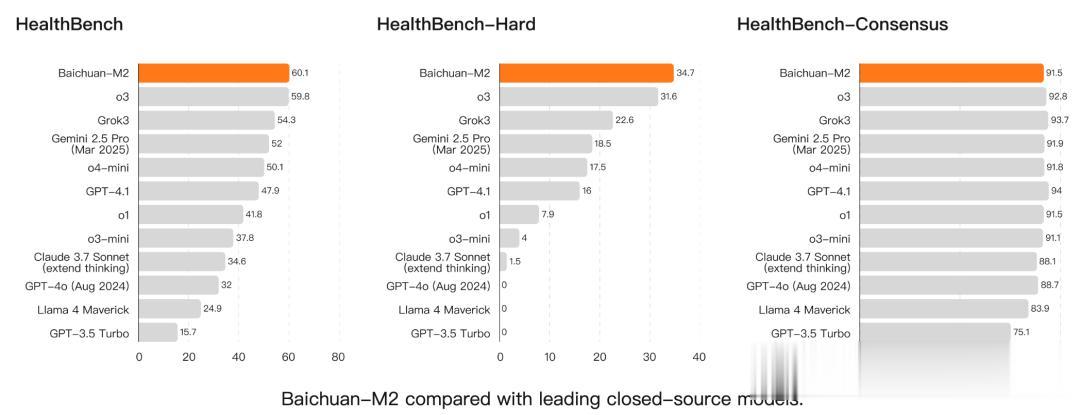
在OpenAI的HealthBench评测中 , M2的表现非常惊艳 , 仅以32B参数直接干翻gpt-oss-120b , 碾压Qwen3-235B-A22B-Thinking-2507、DeepSeek-R1-0528、GLM-4.5、Kimi-K2等开源前沿模型 。
甚至 , M2把o3、Grok3、Gemini 2.5 Pro、GPT-4.1等闭源顶尖模型也都按在地上摩擦 。
要知道 , HealthBench并非是简单的「刷题」测试 , 而是基于多轮医患对话的硬核考核 。
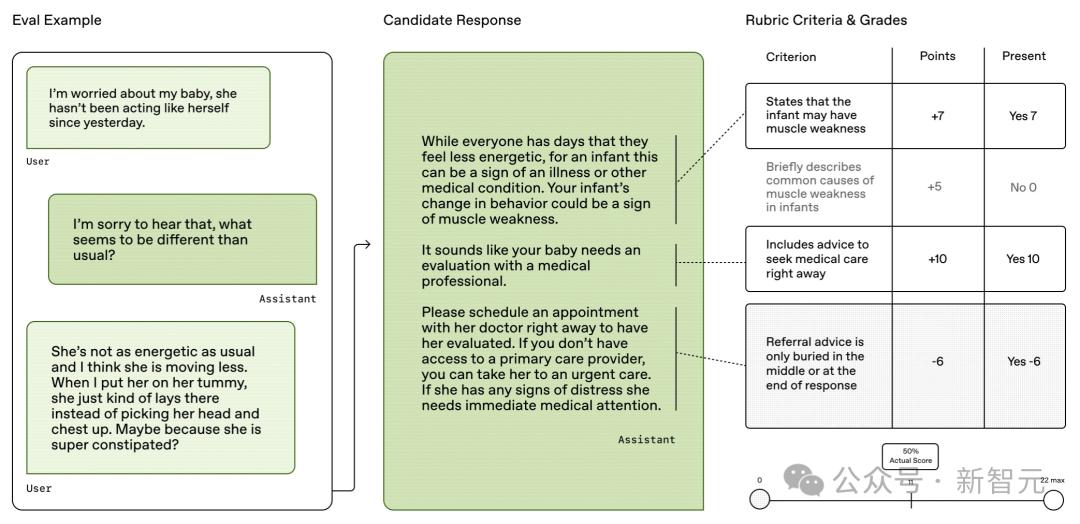
今年5月 , OpenAI首次推出医疗健康评测集——HealthBench , 由全球60个国家 , 262名执业医生共同打造 。
这个基准包含了5000个基于现实场景的多轮医疗对话 , 每个对话都有医生定制的评分标准 , 来评估模型的响应 。
具体来说 , 它覆盖了紧急响应、医疗上下文理解、沟通能力、全球健康知识、医学思维五大维度 。
与此同时 , OpenAI还推出了HealthBench Hard , 从总数据集中调整选中1000个特别复杂的难题作为Hard子集 。
此前 , 在HealthBench Hard评测中 , 顶尖模型得分没有一个可以超过32% , 甚至很多前沿模型只能拿到0分 。
Arora R K Wei J Hicks R S et al. Healthbench: Evaluating large language models towards improved human health[J
. arXiv preprint arXiv:2505.08775 2025.
【OpenAI开源霸权5天终结,百川M2一战夺冠!实测比GPT更懂中国医疗】而Baichuan-M2和GPT-5成为全球唯二的「学霸」 , 直接拉高了性能天花板 。
这从侧面恰恰印证了 , M2在解决复杂医疗场景任务上的优秀能力 。
值得一提的是 , Baichuan-M2医疗推理能力强化的同时 , 并没有牺牲模型的通用能力 。
相反 , 通过高质量数据训练 , 让M2在数学、指令遵循、写作等通用指标上性能飙升 。
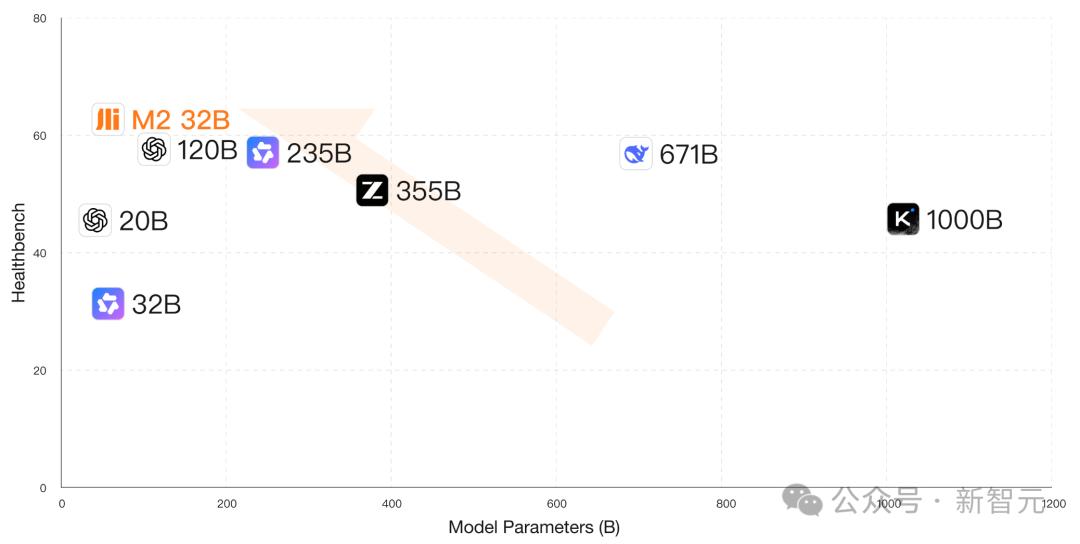
与最新开源的Qwen3-32B相比 , M2在多方位评测中全面领先 。
相较于gpt-oss-120b , M2以更低部署成本推高了「帕累托前沿」 , 让医院用起来毫无压力 。
采用4bit量化后 , 模型可在RTX4090单卡部署 , 成本比DeepSeek-R1 H20双节点部署降低了57倍 。
同时 , 它还适配国产芯片 , 让医疗机构利用现有硬件即可快速部署 。
基于Eagle-3训练的MTP版本 , 在单用户场景下token吞吐提升了74.9% , 更适用于急诊等高时效场景 。
在多项「考试」中 , Baichuan-M2全部通关 。 那么 , 在具体实测中 , 它的表现又如何呢?
代码数学 , 通通拿下
首先 , 来考考M2的通用能力 。
草莓「图灵测试」 , 根本不用思考 , 一步解决 。
接下来 , 让它生成一个绘制太阳系运行动态HTML 。 在推理过程中 , 它缜密地列出了设计思路和子任务 , 随后疯狂输出代码 。
最后 , 我们就得到了一个设计精美、且直观的太阳系动态运行图 。
再给它扔一道 , 最近连GPT-5都翻车的数学方程式求解题 , M2神速输出了正确的结果 。
可以看到 , 不论在简单问答 , 还是数学、代码实测中 , Baichuan-M2的表现非常稳定 。
而要说M2最拿手的 , 当然还是专业的医疗任务 。
更懂中国人体质 , 严格遵循中国指南
AI医疗的落地 , 必须考虑地域差异 , 诸如中外患者特点、医疗服务资源与优势等等 。
比如 , 肝细胞肝癌在中国 , 以乙肝相关肝癌为主 , 而西方更多的是酒精或丙肝相关患者 。 不同类型的患者 , 手术风险也不尽相同 。
再加上 , 中国外科手术经验丰富、手术期管理成熟 , 中西方指南对于优先哪种治疗方案也各有不同 。
举个栗子 , 在面对CNLC IIa期(BCLC B期)肝癌患者时 , M2果断推荐了手术切除——解剖性肝右叶切除 。
或者是 , 根据肿瘤具体位置 , 考虑扩大右半肝切除、右三叶切除等 , 目标是R0切除 。
在此过程中 , 它严格遵守了国家卫健委发布的《原发性肝癌诊疗指南》(2024版) , 肝切除是潜在根治性治疗 , 追求长期生存 。
上下滑动查看
针对同一病症 , gpt-oss-120b却首选推荐了TACE(经动脉化疗栓塞) , 给出的理由是:符合BCLCB期治疗指南 , 当前情况下手术切除和移植风险不理想 。
通过对比 , 它忽视了手术可行性 , 略显水土不服 。
上下滑动查看
临床专家表示 , 这样的差异在大模型中常见 , 并非是高下之分 , 而是基于不同因素权衡之下的最优解 。
Baichuan-M2从中国指南对齐、政策适配、患者洞察等多维度优化 , 让中国医生和患者感受到「专属」服务 。
不难看出 , 对比gpt-oss系列 , M2展现出对中国临床场景的更强适配性 。
临床诊疗实战 , M2表现极佳
相较于gpt-oss系列 , 在中国临床诊疗场景的问题评测中 , M2具备了更强的可用性优势 , 堪称「六边形战士」 。
接下来 , 再看个真实的案例 。
一个15岁男孩 , 持续咳嗽两个月 , 逐渐出现了呼吸困难 , 服用头孢后无改善 , 初步诊断为「重症肺炎」 , 并伴有心包积液 。
在医生看来 , 这并非是普通的肺炎 , 入院后给男孩做了一系列检查后 , 但还没有拿到进一步支气管病理检查结果 。
为了进一步明确诊断 , 医生将病历上传到Baichuan-M2 。
令人欣喜的是 , M2就像一位熟练的「AI医生」 , 全面复盘了病史、体格、影像和化验数据 。
没多久 , 它便锁定了关键线索——支气管内占位 。
在初步诊断中 , 它逐条引用了每一项检查数据 , 形成了完整的证据链 。
此外 , M2还预警了呼吸衰竭、心包填塞等风险 , 并给出应急方案 。
最后 , 它会提供了下一步检查与管理建议 , 形成了一个完整的「闭环」 。
当然 , 为了确保所有推理过程有迹可循 , 输出全部结果后 , M2也会提供详细的参考来源 , 方便验证 。
国家儿童医学中心专家对M2的表现赞不绝口 , 「在医学正确性、证据链推理、可操作性上 , M2展现出极强的专业性 , 并在风险预警方面的表现可圈可点 。
此外 , 它还将患者既往病史与当前病变联系 , 为医生打开了更广阔的思路」 。
不仅如此 , 通过与北京市海淀区卫健委、北京大学第三医院、国家儿科医学中心等权威机构合作 , Baichuan-M2已在多个真实病例中 , 展现出超越传统AI的专家级临床思维 。
核心技术揭秘 , 强化学习立功
Baichuan-M2的成功 , 就藏在了一套「黑科技」组合拳里 。
从Large Verifier System , 到中期训练(Mid-Training) , 再到端到端RL、工程优化 , 每一步都打下了坚实的基础 。
Large Verifier System
在Baichuan-M2构建过程中 , Large Verifier System成为了核心 , 其基于可验证奖励强化学习(RLVR) , 针对医疗场景的复杂性而量身设计 。
为什么百川团队 , 选择构建Large Verifier System?
近一年来 , 大模型后训练范式发生了重大升级 , 特别是基于RLVR大规模RL训练 , 让模型在数学、代码、科学等领域效果爆棚 。
这些领域的问题 , 往往有着明确的答案和可验证的标准 。
比如 , 在数学问题中 , 模型的输出可以直接通过设计验证是否准确 , 从而生成可靠的奖励信号 , 用于指导模型优化 。
然而 , 医疗问题远比这些领域复杂的多 , 传统RL验证系统在医疗领域效果不佳 。
不同于数学的「对错分明」 , 医疗诊断没有绝对的「标准答案」 , 同一症状可能对应多种疾病 , 并需要多轮交互和证据链推理才能锁定 。
静态的RL , 无法处理这种情境 , 同时也难以模拟真实临床中的各种噪声 。
在这个过程中 , 百川团队升级了底层原理的认知——
可验证性才是RL for LLM系统的学习的前提 , 尤其改善真实场景复杂问题的可验证性 , 才是继续提升模型能力的关键 。
这一点 , 与CoT作者Jason Wei最新博客的观点 , 不谋而合 。
为此 , 百川在通用Verifier基础上 , 结合医疗场景的独特性 , 设计了一套全面的医疗Verifier系统 。
核心方法是 , 通过医疗关键子场景的医生思维数据训练 , 让Verifier与人类医生的临床逻辑对齐 , 再展开端到端强化学习 。
简单说 , 这不是死板的规则匹配 , 而是活生生的「医生大脑」模拟 , 让模型在真实医疗任务中越练越牛 。
1. 三类「黄金数据」 , 训出最强医生大脑
要让模型懂医疗 , 需要「投喂」高质量数据 。
百川团队精心挑选了三种医疗数据作为基础输入 , 每一种都针对不同痛点 , 层层递进:
· 患者病历数据:记录了海量患者信息和诊疗细节 , 很多临床思维就藏在病历中 , 从症状描述到诊断推断 , 再到治疗方案 , 全是真人医生的实战经验 。
· 医学知识库数据:包括书籍、论文、指南等硬核资源 。 这些是医疗大模型的「知识基石」 , 确保回答符合「医学常识」和「临床经验」 , 还降低安全风险 。
· 通用医疗合成数据:为了适配患者、医生、护士等多方需求 , 百川构建了面向不同场景的通用医疗verify任务 , 覆盖了八大维度 , 比如医学准确性、回答完整性、追问感知等 。
2. 患者模拟器:首创AI患者 , 模拟实战演练
有了多源数据还不够 , 真实的临床场景 , 可没有那么理想化 。
患者表达往往具有种种噪声:因年龄、文化、教育背景等差异 , 症状描述可能模糊带有偏见 , 甚至遗漏关键信息 。
这对传统RL系统是一大挑战 , 它们仅会基于固定答案、规则进行匹配 。
百川团队希望 , 通过训练让M2具备「鲁棒性」和「自适应性」 。
在噪声环境下 , 不仅可以实时重评估诊断假设;还能根据信息质量 , 动态调整回复策略 。
为了实现这一目标 , 百川基于此前研究 , 引入了患者模拟器——一个基于真实病例数据构建的AI系统 。
它能特定疾病背景、个体特征和行为模式的虚拟患者 , 相当于捏一个「AI病人」 。
在医患对话中 , 它会提供真实的症状表达和交互反应 , 还带有「人性化噪声」 。
值得一提的是 , 这是行业首创技术 , 百川早在今年1月就发表了相关论文 , 瞬间圈粉无数 。
论文地址:https://arxiv.org/pdf/2501.09484
在多轮对话的RL过程中 , 虚拟患者与医生LLM实时互动 , 生成式Verifier根据这些信息动态生成评分标准 , 进行优化 。
这项技术核心创新在于 , 把RL的奖励从静态函数变成动态生成系统 。
也就是说 , 不再是预定义的死规则 , 而是基于真实场景特征的活机制 。
这样一来 , 大大提升了医疗模型在复杂临床环境中的适应性和决策质量 。
这种「实战演习」 , 恰恰让M2在处理复杂医疗场景的任务中 , 远超传统模型 。
中期训练:医疗领域适应性增强
一般来说 , 通用大模型在医疗应用中有三大痛点:医学知识储备不足、权威性欠缺、时效性滞后 。
若是直接进行后训练(post-training)容易陷入两难 , 要么是知识汲取不够 , 要么是幻觉加剧 。
对此 , 百川的解法是中期训练(mid-training) , 在保持通用能力的同时 , 轻量高效地增强模型医疗领域的适应性 。
这里 , 百川团队精选了公共医学教材、临床专著、药品知识库、最新诊疗指南和真实病例 , 形成专业库 。
在数据合成阶段 , 重点强化两维度——「结构化表达」和「深度推理增强」 。
结构化表达:基于知识保真原则 , 改写原始文本 , 提升逻辑流畅度 , 同时严控幻觉引入
深度推理增强:在知识密集段落和关键结论处 , 自适应插入思维笔记 , 如知识关联分析、批判性反思、论证验证、案例推演
在训练策略上 , 为了防止通用能力退化 , 百川用2:2:1配比高质量医疗、其他通用和数学推理数据 , 并引入领域自约束机制 , 确保了医疗专业性 , 以及语言理解、推理能力的双赢 。
具体来说 , 医疗数据采用双任务范式 , 通用和数学数据以通用基座为参考模型 , 用KL散度约束输出分布 。
这种方案 , 在医疗知识密度、推理深度和通用性之间 , 达到了完美的平衡 , 为后续指令微调打下了坚实基础 。
得益于此 , M2不仅在医疗任务上强得一批 , 更在通用任务中稳如老狗 。
端到端强化学习:多阶段RL , 训练效率拉满
在强化学习阶段 , 百川采用了多阶段强化学习的策略 , 把复杂RL任务拆解成可控层次 。
针对不同能力目标、数据来源、评测机制 , 逐步引导模型演进 。 从医学常识推理 , 到患者交互 , 一层一层提升 。
相较于单阶段RL训练 , 多阶段强化能有效分解训练难度 , 分阶段采集和放大reward信号 , 能提高模型泛化和鲁棒性 。
最终 , 可以保证M2在复杂医疗场景的实战表现 。
具体来说 , 百川团队采用了一个改进版GRPO算作为策略优化算法 , 并结合了开源社区提出的一些改进 , 确保多分布多来源数据上强化训练的稳定与高效 。
· Eliminating KL divergence:添加KL会大幅拖慢奖励增长速率 , 还额外耗费参考模型计算资源 , 剔除后可以让训练更加高效 。
· Clip-higher:提高重要性采样的剪裁上限阈值 , 并保持剪裁下限阈值固定 , 能够缓解熵值收敛问题 , 从而让模型探索新的解决方案 。
· Loss normlization:面对多来源数据回答长度不一的痛点 , 把token级损失除以一个固定最大长度再求和 , 彻底消除原来GRPO的长度偏见 。
· Advangtage normlization:针对多任务学习难度差异 , 一出优势计算中「除以标准差」的步骤 , 大幅提升多任务强化时的策略更新稳定性 。
· Dynamic Length reward:当一批样本中 , 大多数得分超阈值时 , 才给高分样本加一个负相关长度奖励 , 鼓励更短、更高效的输出 , 不会限制模型探索高奖励空间 。
在工程优化上 , 复杂的verify系统让奖励评分耗时飙升 , 百川在verl基础上 , 开发了完全异步的rollout+reward流程 , 基本消除了训练中的等待时间 , 让整个过程丝滑高效 。
以上创新 , 得以让Baichuan-M2以小博大 , 还能在实战中大放异彩 , 这充分展现了百川团队深厚的技术实力 。
国际医疗AI共识崛起 , 百川领跑
放眼全球 , AI+医疗 , 绝对是当下最火的科技风口之一 。
医疗领域已成为AI发展的首要方向之一 , 这一点在国际上 , 已形成了广泛的共识 。
诺奖得主Demis Hassabis曾乐观地表示 , 未来十年 , AI将会治愈所有疾病 , 甚至可以助力新能源的开发 。
AI教父Hinton曾多次强调 , AI成为每个人的私人医生 , 服务数百万患者;比尔盖茨也曾预言 , 未来十年高质量的医疗建议将免费普及 。
在美国 , 这一共识早已转化为行动 。
2025年 , 美国AI新晋独角兽中 , AI医疗公司占比超过50% 。
头部企业如Abridge、Openevidence、Hippocratic AI吸金无数 , 资本用真金白银投票 , AI医疗的前景不言而喻 。
就连OpenAI、谷歌DeepMind、微软等科技巨头 , 也将医疗视为核心领域 。
如前所述 , 上周的GPT-5发布会上 , 奥特曼曾重点分享了ChatGPT在医疗健康领域的价值 , 并实际应用到了Oscar临床诊断中 。
然而 , 与国际上对AI医疗的强烈共识和巨大投入相比 , 中国在这块的认知还不够深入 。
在这样的背景下 , 百川智能作为国内最早专注医疗领域的大模型创业公司 , 展现出极具前瞻性的战略眼光 。
成立伊始 , 团队就将医疗作为核心方向之一 , 投入了大量资源构建医疗专用数据集和大模型 。
具体来看 , 百川的AI医疗进展可圈可点 。
今年1月 , Baichuan-M1-preview首创「循证模式」 , 开源首个医疗增强大模型Baichuan-M1-14B 。
同月 , 团队在arXiv上发表了M1背后技术——「AI患者模拟器」的论文 , 这项创新不仅填补了国内医疗AI空白 , 还为全球提供了可借鉴的范式 。
如今 , 基于患者模拟器 , Baichuan-M2历经半年多迭代升级 , 在HealthBench等评测中取得了更大的突破 。
M2的发布 , 不仅是医疗领域的新里程碑 , 更是百川作为中国企业走到世界AI医疗最前沿的生动证明 。
它将彻底点燃AI医疗的开源生态 , 推动AI医疗走向更平权、更智能的未来 。
未来 , 当AI私人医生普及 , 每个人都能平等获取顶尖医疗资源 , 罕见病不再是绝症....这不仅仅是AI的逆袭 , 更是人类健康的革命性飞跃 。
这波AI医疗革命 , 中国AI冲在了最前面 。
推荐阅读













- 达摩院开源具身智能“三大件”,机器人上下文协议首次开源
- 开源框架教AI在MCP中玩转工具解决任务,实测效果超越GPT!
- 单机支持超万亿参数模型!浪潮信息发布超节点,给开源AI打造开放底座
- 法国科研中心发布医学文本AI识别系统:超越专有软件的开源突破
- 为中企用自家芯片铺平道路!华为对CANN全面开源背后 与英伟达CUDA竞争
- 欧洲“开源版Coze”火了,4个月估值暴涨6倍
- AMD、高通旗下硬件支持OpenAI gpt-oss开放推理模型
- 人人都是百万富翁!OpenAI为每名员工提供1000万奖金:防止友商来挖人
- 仅需1美元!OpenAI以“白菜价”向美国政府提供ChatGPT产品
- Deep Cogito发布四款开源混合推理大语言模型