腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机

文章图片

文章图片
文章图片
文章图片

文章图片

文章图片
本论文作者团队来自腾讯混元X组 , 共同一作为耿子钢和王逸冰 , 项目Lead为张小松 , 通讯作者为腾讯混元团队杰出科学家胡瀚 , Swin Transformer作者 。
在图像生成领域 , 自回归(Autoregressive AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇 。 大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式 , 已在文本生成领域奠定了不可撼动的地位 。 然而 , 当这一范式被应用于视觉领域时 , 却暴露出诸多瓶颈:生成图像细节失真、语义理解偏差 , 尤其在复杂文本渲染任务中表现尤为乏力 。 目前 , 统一视觉理解和生成的主流研究工作在图像生成部分往往采用扩散模型来建模 , 使得视觉理解和生成任务依然只是松散的耦合在一起 。
近日 , 腾讯混元团队的最新研究成果 X-Omni 模型通过强化学习大幅提升了自回归图像生成方法的生成质量 , 这一模型能生成具有较高美学品质的图像 , 同时展现出强大的遵循指令和渲染长文本图像的能力 。 该模型已开源:
论文链接:https://arxiv.org/pdf/2507.22058 GitHub链接:https://github.com/X-Omni-Team/X-Omni 项目主页:https://x-omni-team.github.io Hugging Face 模型:https://huggingface.co/collections/X-Omni/x-omni-models-6888aadcc54baad7997d7982 Hugging Face Space:https://huggingface.co/collections/X-Omni/x-omni-spaces-6888c64f38446f1efc402de7
图 1 对比主流闭源和开源模型的文字渲染效果
强化学习大幅提升
图像生成质量和指令遵循能力
基于离散自回归方法监督微调后图像生成的质量相对较低 , 表现为文本生成错误、身体特征失真以及无法遵循复杂指令 。 引入强化学习后 , 生成图像的审美质量逐渐提高 , 遵循指令的能力和渲染长文本的能力稳步提升 。 如图 2 所示 , 经过 200 步强化学习 , X-Omni 模型展示了图像生成的高质量视觉效果、强大的遵循复杂指令的能力 , 以及准确渲染中英文长文本的能力 。
图 2 经过 200 步强化学习 , 图像生成质量和指令跟随能力逐步提高
方法
整体架构
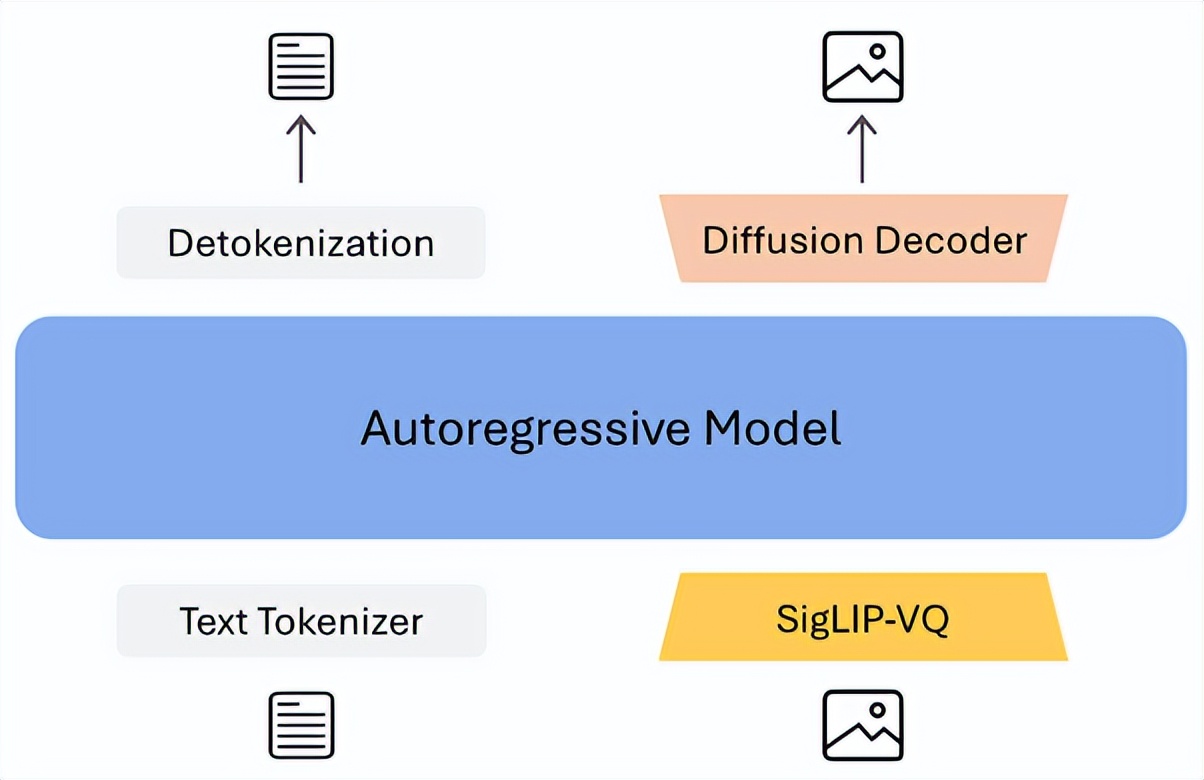
如图 3 所示 , 该框架是一个基于离散 token 的自回归模型 , 其中 tokenizer 采用 SigLIP2-VQ 方法构建 , 在离散 token 上运行一个扩散解码器生成最终的图像 。 这一设计使得图像理解和生成统一在离散自回归框架中 , 从而实现优雅的联合图像理解与生成 。
图3 X-Omni 整体网络架构
GRPO 强化学习方法
进行联合图像理解和生成的预训练和监督微调后 , 本文继续采用强化学习方法来提升图像生成能力 。 强化学习过程的整体流程如图 2 (a) 所示 , 由于采用离散自回归的方法 , 可以应用语言模型中较为成熟的 GRPO 方法来进行强化学习:
奖励系统
我们构建了一个综合性的奖励模型系统 , 其包含多个专门的模型 , 从人类美学偏好、文本 - 图像语义对齐以及文本渲染准确性等维度来评估图像生成质量 。 最终奖励分数通过各个奖励信号的加权融合得出 。
人类偏好分数:采用 HPSv2 模型评估人类美学偏好 。 该模型在多种图像分布上均表现出优异的泛化能力 , 能够可靠地预测人类对生成图像的偏好排序 。 Unified Reward 分数:引入 Unified Reward 对图像进行整体质量评估 。 该奖励函数将多维度质量指标聚合为一个统一的分数 , 为强化学习提供整体反馈 。 文本 - 图像语义对齐分数:为确保输入提示和生成图像间的语义一致性 , 我们利用 Qwen2.5-VL-32B 来计算对齐奖励 。 借助该模型强大的图像理解能力 , 我们评估生成图像是否准确反映了提示描述的内容 。 对齐分数量化了文本描述和视觉内容之间的对应关系 , 鼓励生成与上下文相关的图像 , 同时最大限度地减少语义幻觉 。 OCR 准确性分数:文本渲染准确性是文本到图像生成中的一个关键挑战 。 对于需要在图像中生成文本的提示 , 我们联合 GOT-OCR 2.0 与 PaddleOCR 对生成图像进行双重 OCR 解析 , 计算文本渲染的准确性分数 。 该奖励信号为增强文本渲染能力提供了关键指导 , 使我们的模型能够可靠地生成清晰准确的文本 。实验结果
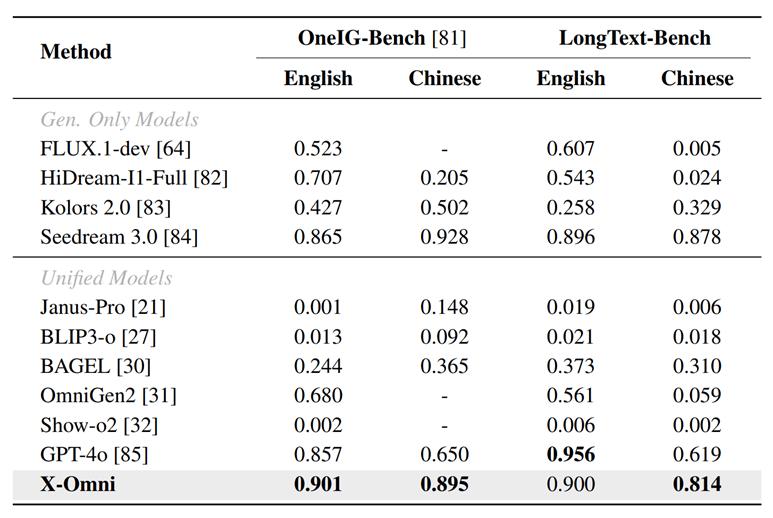
文本渲染能力评估:
表 1 在 OneIG-Bench 和 LongText-Bench 上与现有模型的比较
指令跟随能力评估:
表2 在 DPG-Bench 上与现有模型的比较
表 3 在 GenEval 上与现有模型的比较
有意思的发现
不再需要分类器无关引导(CFG):传统 AR 图像模型严重依赖 CFG 来提升生成质量 , 这不仅增加了推理开销 , 也反映了模型自身生成分布的偏差 。 X-Omni 在推理时 , 其自回归部分无需 CFG 即可生成高质量图像 , 这力证了其视觉与语言生成机制的高度统一与内在一致性 。
图 4 主流 AR 模型对 CFG 的依赖比较
RL 在图像生成中的独特优势:研究表明 , 在图像生成领域 , 强化学习的优化效果显著超越了监督微调(SFT)配合「N 选 1(Best-of-N)」的采样策略 。 这揭示了 RL 在处理高维、空间依赖复杂的图像数据时 , 能够提供更全面、更高效的优化信号 。
更多例子
图 5 更多生成图像可视化举例
【腾讯发布X-Omni:强化学习让离散自回归生成方法重焕生机】一个更统一、更强大、更优雅的全模态未来 , 正由离散自回归图像生成方法的复兴开启 。
推荐阅读











- 首款国产“Vision Pro”正式官宣,本月发布
- 智谱终于发布GLM-4.5技术报告,从预训练到后训练,细节大公开
- 京东携手荣耀发布首款大屏AI手机:一键操作+方言识别
- 中国移动与腾讯签署战略合作协议
- 今年“618”具身机器人销售额增长17倍!京东发布智能机器人产业加速计划
- 小米平板8系列通过3C认证,将和小米16一同发布
- iPhone 17 Pro 即将发布,今年终于大变样
- 腾讯张正友:具身智能必须回答的三个「真问题」
- 微星发布PRO H810I WIFI:银黑配色,入门级ITX规格主板
- 华为官宣!突破性成果将发布