文章图片

文章图片

文章图片

文章图片
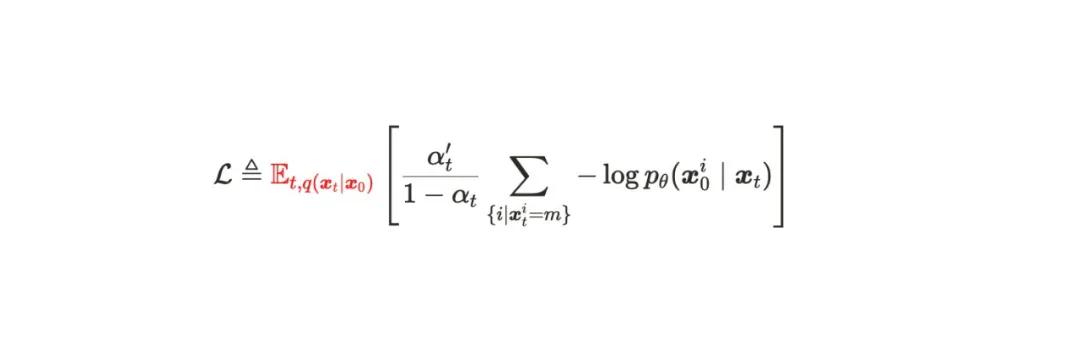
文章图片

文章图片

文章图片
机器之心报道
编辑:杜伟
【token危机解决?扩散模型数据潜力3倍于自回归,重训480次仍攀升】扩散语言模型(DLMs)是超强的数据学习者 。
token 危机终于要不存在了吗?
近日 , 新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步 。
在当前大语言模型(LLM)的持续发展中 , 面临的挑战之一是可用的高质量训练文本数据(tokens)即将枯竭 , 并成为限制模型性能持续提升的关键瓶颈 。 另外 , 新增的高质量数据来源少 , 获取成本高 , 去重后更加稀缺 。 因此 , 当模型规模继续扩大 , 所需数据量按 Scaling Laws 成倍增加时 , 就出现了「优质 token 不够训练」的危机 。
针对这一现象 , 该团队从零开始预训练了扩散语言模型(DLMs)与自回归(AR)模型 , 其中规模最高至 80 亿参数、4800 亿 tokens、480 个 epoch 。
研究有以下三项重要发现:
在 token 数量受限的情况下 , DLMs 优于 AR , 并且具有超过 3 倍的数据潜力; 一个仅用 10 亿 tokens 训练的 10 亿参数 DLM , 在 HellaSwag(常识推理基准) 上可达 56% , 在 MMLU(综合多任务语言理解基准) 上可达 33% , 无任何技巧、无挑选数据; 未出现性能饱和:重复训练次数越多 , 提升越明显 。
此外 , 团队还剖析了并行研究《Diffusion Beats Autoregressive in Data-Constrained Settings》中的严重方法论缺陷 —— 以共同提升开放评审的标准!
Jinjie Ni 在社媒 X 上详细介绍了其团队的研究结论、研究方法 , 接下来我们一一来看 。
结论 1:扩散语言模型(DLMs)是超强的数据学习者 。
如上所述 , 团队从零开始预训练了一系列 DLMs , 规模最高达 80 亿参数、4800 亿 tokens 。 结果提供了有力证据:在普通网页数据上进行重复训练时 , DLMs 在数据受限场景下无论模型规模如何 , 都优于自回归(AR)模型 , 展现出显著更高的潜力且未出现性能饱和 。
总体而言 , DLMs 的最终数据潜力比 AR 模型高出三倍以上 。
结论 2:重复越多 , 收获更多 。
为了研究 DLM 训练中 token 的全部潜力 , 团队进行了额外实验:将同一份 10 亿 token 的数据集重复训练 480 个 epoch , 总训练量达到 4800 亿 tokens 。 结果显示 , 模型在 HellaSwag 上取得约 56% 的准确率 , 在 MMLU 上取得约 33% , 显著优于 AR 的约 41% 和约 29% 。
令人惊讶的是 , 即使在如此极端的重复条件下 , 性能依然未出现饱和 , 这表明 DLMs 能够从固定的 10 亿 token 语料中提取到远超预期的有效信息 。
「在验证集上出现过拟合的模型 , 在下游任务上的表现却持续提升 。 」为什么会这样呢?
团队可视化了多选评测中 , 真实答案与其他选项的平均负对数似然(NLL) , 以及它们之间的差值(△NLL) 。 即使在验证集上出现「过拟合」后 , 真实答案与其他选项的 NLL 差距(△NLL)依然持续扩大 , 这表明尽管验证损失在上升 , 模型的底层判别能力仍在不断提升 。 这一现象在域内数据和域外数据的训练中都同样存在 。
虽然 DLMs 对数据重复具有较强的鲁棒性 , 但在训练足够长的 epoch 后 , 它们同样会发生过拟合 。 更大的唯一数据量可以延缓过拟合的出现 , 而更大的模型规模则会加速过拟合的到来 。
为什么 DLMs 是超强的数据学习者呢?原因有二 。
其一 , 如下图所示 , 网页文本数据并非完全因果结构!虽然用非因果方向建模会导致更高的损失 , 但它仍然是可行的 。 这意味着仅用纯因果方式来建模网页数据是一种浪费!借助扩散目标和双向注意力 , DLMs 能够对数据进行双向建模 , 从网页数据中提取到更多信息 。
其二 , DLMs 是「超密集模型」 , 它们在计算上的超高密度(每个任务需要更多的 FLOPs)直接转化为更强的智能 。
相比之下 , AR 模型更优先考虑计算效率 , 而非数据潜力 。 它们的 Transformer 设计(包括教师强制和因果掩码)最大化 GPU 的使用效率 , 但限制了建模能力 。 随着计算成本下降 , 数据可得性反而成为关键瓶颈 —— 这正是团队研究 DLMs 的动力所在 。
扩散目标要求在有效训练中 , 将预训练数据集中的每个数据点在多个掩码比例和组合下进行损坏 , 以便更精确估计期望值 。 这进一步解释了为什么数据重复训练能带来如此显著的收益 。
巧合的是 , 一项同期研究「Diffusion Beats Autoregressive in Data-Constrained Settings」[1
也探讨了类似主题 。 然而 , 团队在细致分析后 , 揭示了其中存在的若干方法论问题 , 可能导致结论存在偏差 。
[1
地址:https://arxiv.org/abs/2507.15857
在 [1
的所有实验中 , 研究者使用了损失函数 (1) , 但未做出明确的理论解释 。 然而 , 这个损失函数与理论基础更扎实、被广泛采用的掩码扩散语言建模损失 (2) 有显著差异 。 从理论上可以证明损失函数 (1) 并不能忠实地表示模型似然 , 这可能会对其结论造成严重影响 。
团队还注意到 , [1
在最新的 arXiv v3 版本中对原始草稿进行了修改 , 增加了一个线性时间依赖的重新加权项 。 但仍假设其所有实验均使用了公式 (1) , 因为论文中图 4 (b) 的损失范围与公式 (1) 的预期表现高度吻合 。 团队期待 [1
的代码库(在本文撰写时仍为空仓库)以及社区对相关实验的复现 。
问题来了:验证集损失是比较 AR 和 DLM 的好指标吗?简短来说:当损失函数的形式本身有问题时 , 当然不是 。 它们并不代表相同的含义;即使损失函数形式正确 , 也依然不是好指标 。
原因包括如下:
AR 测量的是精确的负似然 , 而 DLM 测量的是一个上界; 更低的损失并不意味着更强的能力 , 这一点在上文的讨论中已有体现 。
此外 , [1
报告的 AR 基准测试结果距离最佳水平相差甚远 。 换句话说 , [1
实际上是在拿一个尚未训练到最佳状态的 AR 检查点 , 与一个最佳的扩散模型检查点进行比较 。 这是不公平的 。
此外 , [1
在比较 AR 与扩散模型的过拟合趋势时 , 为 AR 使用了更大的模型规模和更少的唯一训练 token 数量 。 这种设置并不公平 , 因为更大的模型在训练数据多样性不足的情况下 , 本身就更容易更早出现过拟合 。
最后 , [1
中使用的 scaling law 公式假设验证集损失不会下降 , 但这一假设在实际中并不成立 , 因为过拟合会导致验证损失上升 。 这个有缺陷的假设会导致拟合效果不佳 , 并使基于其预测得出的任何结论产生偏差 。
目前 , 团队正在用一种疯狂的设置训练一个大模型 , 并在之后发布完整论文 。
更多细节内容请参考博客和即将发布的论文 。
参考内容:https://x.com/NiJinjie/status/1954177095435014533
博客链接:
https://jinjieni.notion.site/Diffusion-Language-Models-are-Super-Data-Learners-239d8f03a866800ab196e49928c019ac
推荐阅读













- 开源框架教AI在MCP中玩转工具解决任务,实测效果超越GPT!
- Token成本下降,订阅费却飞涨,AI公司怎么了?
- 亿联网络打造全链路安全视频会议解决方案,护航企业高效办公
- 隐藏在浏览器里的“指纹”,正成为新的隐私危机
- 字节发布扩散语言模型,2146tokens/s,比同规模自回归快5.4倍
- 智启新篇:Dynabook智慧办公解决方案,重构未来办公新生态
- 强化学习的两个「大坑」,终于被两篇ICLR论文给解决了
- 突破单token预测局限!南洋理工首次将多token预测引入微调
- 三大运营商终于出手!事关“资费乱象”问题,有望彻底解决了
- 马斯克承诺年底让一半美国人坐上无人出租车,网友:先解决FSD再说