文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

机器之心报道
作者:杨文、杜伟
最近 , 一个长相酷似韩国影星河正宇的博主 , 在 TikTok 上发视频吐槽:「老婆总是喜欢乱 P 我睡觉的照片 , 咋整?」
本以为是撒狗粮 , 没想到还真撞上了 P 图界的邪修大神 。 她总能把千奇百怪的睡姿 , 恰到好处地融进各种场景 , 脑洞大得能随机笑死一个路人 。
视频来源:https://www.tiktok.com/@awakesoul3
这看似沙雕的 P 图背后 , 其实揭示出了一个趋势:图像编辑的需求正变得越来越个性化 , 也对工具的智能化程度提出了更高的要求 。
就在今天 , 火山引擎整个大活 , 发布了豆包?图像编辑模型 SeedEdit 3.0 , 并上线火山方舟 。
体验地址:https://console.volcengine.com/auth/login/
作为豆包家族的重要成员 , 图像编辑模型 3.0 主打一个「全能且可控」 。
具体来说 , 它有三大优势:更强的指令遵循、更强的主体保持、更强的生成质量 , 特别是在人像编辑、背景更改、视角与光线转换等场景中 , 表现更为突出 , 还在多项关键编辑指标之间取得了极佳平衡 。
举个例子 。 它能一键更换杂志封面文字 , 同时保持其他元素不变:
Prompt:Change 'MORE' to 'MAGAZINE'
或者随意调整打光、画面氛围:
Prompt:保持画面不变 , 室内黑暗 , KTV 氛围 , 球形灯 , 五颜六色灯光
甚至一句模糊指令就能让电商产品海报替换背景:
Prompt:根据图中物品的属性替换背景为其适合的背景场景
接下来 , 咱们就实测一把 , 看看升级后的图像编辑模型 3.0 到底有多硬核 。
一手实测
AI 修图 , 看不出「科技与狠活」
AI 图像编辑模型的出现 , 让许多手残党都成了 P 图达人 , 不过问题也随之而来:用嘴 P 图固然方便 , 但这些 AI 往往会出现「误伤」 。
比如你只想改个背景 , 结果人物的面部和姿势却变了;你明明下达了精准的指令 , 它们却偏偏听不懂「人话」 , 对着原图一顿乱改;好不容易搞对了主体和背景 , 画面又丑得别具一格 。
现在好了 , 豆包?图像编辑模型 3.0 已经解决这些「通病」 , 只需一句简单的提示词 , 就能针对画面元素增、删、改、替 。
打字 P 图 , 指哪改哪
日常生活中 , 大概每个人都会遇到这些抓狂的瞬间:出门旅游拍照 , 忍着羞耻心凹好造型 , 却半路杀出个路人甲乱入镜头;想用明星美照当壁纸 , 但正中间打着又大又丑的水印 , 裁剪都无从下手 。
这时 , AI 消除功能就派上用场 。
比如在泰勒?斯威夫特的街拍场景中 , 豆包?图像编辑模型 3.0 可以精准锁定黄衣女生和水印 , 完成双重清除 , 同时还不伤及主体人物和背景细节 。
提示词:删除穿黄衣服的女生 , 删除水印 , 其他要素保持不变 。
它还能同时处理消除路人、雨伞变色两项复杂任务 。 路人消失后背景自然补全 , 毫无 PS 痕迹;雨伞变色也严格锁定目标物体 , 未波及人物服饰或环境 。
提示词:消除后面两个路人 , 雨伞变成红色 , 其他元素保持不变 。
如果感觉画面平平无奇 , 想增加点元素提升视觉冲击 , 同样只需一句指令 , 就能让安妮?海瑟薇体验一把「房子着火我拍照」的刺激 。
提示词:后面的房子着火了 。
再来试试 AI 替换功能 。 什么换文字、换背景、换动作、换表情、换风格、换材质…… 豆包?图像编辑模型 3.0 通通可以搞定 。
比如 , 把汽水瓶上的文字「夏日劲爽」改为「清凉一夏」 , 它不仅沿用原有字体设计 , 还保留了所有的背景元素 。
提示词:图中文字 “夏日劲爽” 改为 “清凉一夏” 。
再比如 , 把梅西和 C 罗自拍照的背景 , 从上海外滩瞬移至悉尼歌剧院 , 看来以后只要动动嘴就能打卡全球各大热门景点了 。
或者将人物动作替换为「怀抱小狗」 , 画面没有出现穿帮或者比例失调的情况 。
提示词:这个女生抱着一只小狗 。
此外 , 豆包?图像编辑模型 3.0 还能转换风格 , 比如水彩风格、吉卜力风格、插画风格、3D 风格等 。
图 1 为原图;图 2 为水彩风格;图 3 为吉卜力风格;图 4 为新海诚风格
除了以上常规功能 , 豆包?图像编辑模型 3.0 还有不少进阶玩法 , 包括光影变化、黑白照片上色、商业海报制作、线稿转写实等 。
在完整保留海边静物原始构图的基础上 , 该模型精准重构黄昏暖色调光影 , 使蓝白格子桌布、玫瑰花与海面均自然镀上落日余晖 。
提示词:保持原画面内容不变 ,更改光影黄昏风格光影 。
给黑白照片上色时 , 我们还可以自定义风格 , 比如输入「日系风格」 , 直出胶片感大片 , 氛围感拉满 。
提示词:给这张照片上色 , 日系风格 。
我们还可以制作商业产品海报 , 比如让它根据物品的属性替换为适合的背景 , 并在海报上添加字体 。 这下电商老板们该狂喜了 , 毕竟一年也能省不少设计成本 。
提示词:根据图中物品的属性替换为其适合的背景场景 , 画面中自然融入以下文案文字: 主标题为 “清新自然 静谧之选” 副标题为 “感受肌肤的舒缓之旅” 字体设计感高级 , 排版自然协调 , 不添加任何边框、装饰线、图框或圆角 , 仅保留通透画面与内容构图 , 适合作为品牌宣传海报 , 瓶身其他元素保持不变
提示词:将图中背景换成沙滩
或者把服装和建筑设计的线稿转成写实风格 。
提示词:根据线稿改为真实人物、真实服装
提示词:把这个线稿图改为真实的场景
一番体验下来 , 我们也摸到了提示词撰写的门道:
每次编辑使用单指令会更好; 尽量使用清晰、分辨率高的底图; 局部编辑时指令描述尽量精准 , 尤其是画面有多个实体的时候 , 描述清楚对谁做什么 , 能获取更精准的编辑效果; 发现编辑效果不明显的时候 , 可以调整一下编辑强度 scale , 数值越大越贴近指令执行 。与 GPT-4o、Gemini 2.5 Pro 掰掰手腕
目前 , 市面上有不少模型可以执行图片编辑功能 , 比如曾在全球刮起「吉卜力热」的 GPT-4o、谷歌大模型扛把子 Gemini 2.5 Pro , 它们的 P 图效果究竟如何 , 还得来个横向对比 。
Round 1:文字修改
在针对商业海报文字编辑任务的测试中 , 通用大模型暴露出了文字生成短板 。
GPT-4o 将画面中的文字替换为无法辨认的乱码 , Gemini 2.5 Pro 则未严格遵循替换指令 , 而是在原海报文字的下方进行了文字添加 。
只有豆包?图像编辑模型 3.0 精准完成「店家推荐」文字替换 , 还保留了原字体材质与背景元素 , 也没有出现「鬼画符」等缺陷 。
图 1: 原图;图 2: 豆包?图像编辑模型 3.0;图 3:GPT-4o;图 4:Gemini2.5 pro;提示词:把文字「金丝酥单品」改成「店家推荐」 , 其他元素不变
Round 2:风格转换
我们让这三款大模型把写实人物摄影照片转成涂鸦插画风格 , 豆包?图像编辑模型 3.0 严格遵循双重约束指令 , 生成的画面审美也在线 。
相比之下 , GPT-4o 和 Gemini 2.5 Pro 改出来的图看起来更像随意画的儿童涂鸦 , 女孩的五官有些模糊走样 , 背景的细节也丢失不少 。
图 1: 原图;图 2: 豆包?图像编辑模型 3.0;图 3:GPT-4o;图 4:Gemini2.5 pro;提示词:保持背景结构 , 保持人物特征 , 风格改成涂鸦插画风格
Round 3:物体、文字消除
再来对比下 AI 消除功能 。
原图元素较多 , 路人、店招 , 还有一行浅浅的水印 , 豆包?图像编辑模型 3.0 成功消除画面中所有路人及文字 , 包含店铺招牌 , 同时精准修复背景空缺区域 。
而 GPT-4o 和 Gemini2.5 Pro 的消除功能总是「丢三落四」 , GPT-4o 忘记删除店招 , Gemini2.5 Pro 则只 P 掉了水印 , 其他指令要求一概忽视 。
图 1: 原图;图 2: 豆包?图像编辑模型 3.0;图 3:GPT-4o;图 4:Gemini2.5 Pro;提示词:保留滑板男孩 , 删除画面中所有路人 , 并删除所有文字 , 其他元素不变
整体而言 , 相较于 GPT-4o 和 Gemini 2.5 Pro , 豆包?图像编辑模型 3.0 理解指令更到位 , 改图效果更精准自然 , 尤其是「文字生成」功能 , 几乎不用抽卡 , 完全可以达到商用的程度 。
技术揭秘
从模型架构到推理加速 , 全方位进化
炼成这样一个超级实用、易用且好玩的 P 图神器 , 豆包?图像编辑模型 3.0(以下统称 SeedEdit 3.0) 依托的是一整套技术秘籍 。
作为 AIGC 领域的重要分支 , 可编辑的图像生成要解决结构与语义一致性、 多模态控制、局部区域精细编辑、前景背景分离、融合与重建不自然、细节丢失与伪影等一系列技术难题 。
基于豆包文生图模型 Seedream 3.0 , SeedEdit 3.0 很好地解决了上述难题 , 在图像主体、背景和细节保持能力上进一步提升 。 在内部真实图像测试基准测试中 , SeedEdit 3.0 更胜其他模型一筹 。
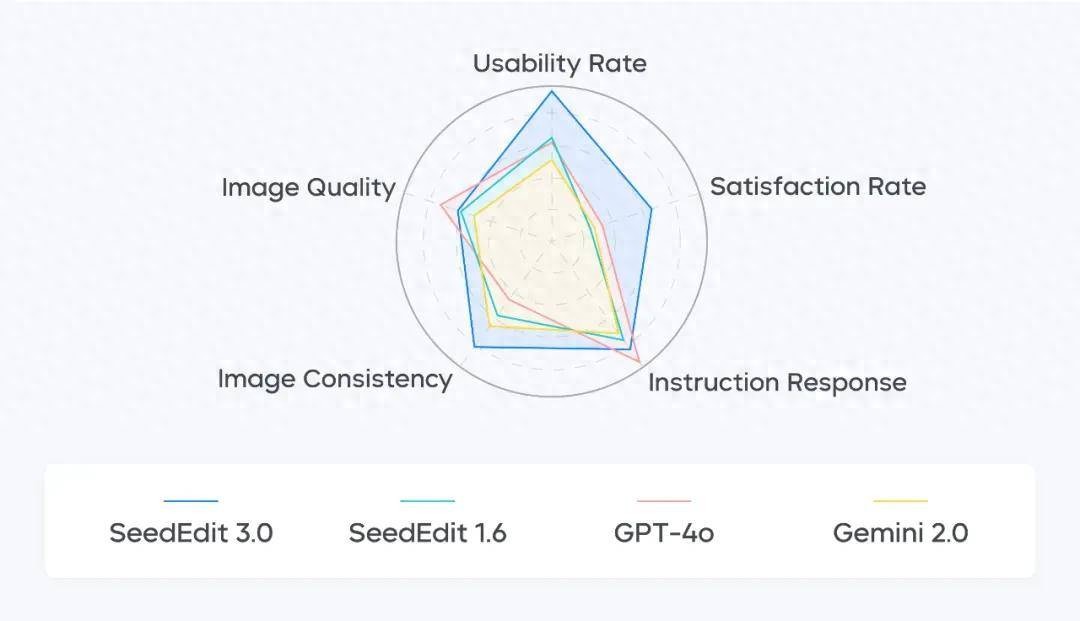
定量比较结果如下所示 , 其中左图利用 CLIP 图像相似度评估模型编辑保持效果 , SeedEdit 3.0 领先于前代 1.0、1.5、1.6 以及其他 SOTA 模型 Gemini 2.0、Step1X 和 GPT-4o , 仅在指令遵循方面不如 GPT-4o;右图显示 SeedEdit 3.0 在人脸保持方面具有明显优势 。
下图为部分定性比较结果 , 直观来看 , SeedEdit 3.0 在动作自然度、构图合理性、人物表情与姿态还原性、视觉一致性、清晰度与细节保留等多个维度上表现更好 。
为了达成这样的效果 , SeedEdit 3.0 团队从数据、模型和推理优化三个层面进行了深度优化与创新 。
首先是数据层面 , 一方面引入多样化的数据源 , 包括合成数据集、编辑专家数据、传统人工编辑操作数据以及视频帧和多镜头数据 , 并包含了任务标签、优化后的描述和元编辑标记信息(下图) 。 而基于这些数据 ,模型在真实数据与合成的「输入 - 输出编辑空间」中进行交错学习 , 既不损失各种编辑任务的信息 , 又提升对真实图像的编辑效果 。
另一方面 , 为了有效地融合不同来源的图像编辑数据 , 团队采用了一种多粒度标签策略 。 对于差别比较大的数据 , 通过统一任务标签区分;对于差别较小的数据 , 通过加入特殊 Caption 区分 。 接下来 , 所有数据在重新标注、过滤和对齐之后进行正反向的编辑操作训练 , 实现全面梳理和整体平衡 。
可以说 , 更丰富的数据源以及更高效的数据融合 , 为 SeedEdit 3.0 处理复杂图像编辑任务提供了强大的适应性和鲁棒性 。
其次是模型层面 , SeedEdit 3.0 沿用了 SeedEdit 的架构 , 底部视觉理解模型从图像中推断出高层次语义信息 , 顶部因果扩散网络充当图像编码器来捕捉细粒度细节 。 此外 , 视觉理解与扩散模型之间引入了一个连接模块 , 将前者的编辑意图(比如任务类型和编辑标签等)与后者对齐 。
在此基础上 , 团队将文生图模型 Seedream 2.0 中的扩散网络升级为 Seedream 3.0 , 无需进行任何细化便可以原生生成 1K 至 2K 分辨率图像 , 并增强了人脸与物体特征等输入图像细节的保留效果 。 得益于此 , 模型在双语文本理解与渲染方面的能力也得到了增强 , 并可以轻松扩展到多模态图像生成任务 。
SeedEdit 3.0 模型架构概览
而为了训练出现有架构 , 团队采用了多阶段训练策略 , 包括预训练和微调阶段 。 其中 , 预训练阶段主要对所有收集的图像对数据进行融合 , 通过图像多长宽比训练、多分辨率批次训练 , 使模型从低分辨率逐步过渡到高分辨率 。
微调阶段则主要优化输出结果以稳定编辑性能 , 过程中重新采样大量精调数据并从中选出高质量、高分辨率样本;然后结合模型过滤器和人工审核对这些样本二筛 , 兼顾高质量数据和丰富编辑类别;接下来利用扩散损失对模型进一步微调 , 尤其针对人脸身份、美感等对用户价值极高的属性 , 引入特定奖励模型作为额外损失 , 提升高价值能力表现;最后对编辑任务与文本到图像任务联合训练 , 既提升高分辨率图像编辑效果 , 又增强泛化性能 。
为了实现更快的推理加速 , SeedEdit 3.0 采用了多种技术手段 , 包括蒸馏、无分类器蒸馏、统一噪声参照、自适应时间步采样、少步高保真采样和量化 。 一整套的方案 , 让 SeedEdit 3.0 大幅缩短了从输入到输出的时间 , 并减少计算资源的消耗 , 节省更多内存 。
最终 , 在蒸馏与量化手段的多重加持下 , SeedEdit 3.0 实现了 8 倍的推理加速 , 总运行时长可以从大约 64 秒降至 8 秒 。 这样一来 , 用户等待的时间大大降低 。
想要了解更多技术与实验细节的小伙伴 , 请参阅 SeedEdit 3.0 技术报告 。
技术报告地址:https://arxiv.org/pdf/2506.05083
写在最后
也许 AI 圈的人已经注意到了 , 最近一段时间 , 包括图像、视频在内 AIGC 创作领域的关注度有所回落 , 尤其相较于推理模型、Agent 等热点略显安静 。 然而 , 这些赛道的技术突破与产品演进并没有停滞 。
在国外 , 以 Midjourney、Black Forest Labs 为代表的 AI 生图玩家、以 Runway、谷歌 DeepMind 为代表的 AI 视频玩家 , 继续模型的更新迭代 , 推动图像与视频生成技术的边界 , 提升真实感与创意性 。 而国内 , 以字节跳动、阿里巴巴、腾讯为代表的头部厂商在图像、视频生成领域依然高度活跃 , 更新节奏也很快 , 从技术突破与应用拓展两个方向发力 。
这些头部厂商推出的大模型产品还通过多样化的平台和形态广泛触达用户 , 比如 App、小程序等 , 为创作者提供了便捷的内容创作工具 。 这种「模型即产品」的能力既提升了易用性 , 也激发了用户的参与感与创造力 。
就拿此次的豆包?图像编辑模型 3.0 来说 , 它在国内首次做到了产品化 , 无需像传统图像编辑软件一样描边涂抹、修修补补 , 输入简单的自然语言指令就能变着花样 P 图 。 我们在实际体验中已经感受到了它的魔力 , 换背景、转风格以及各种元素的增删与替换 , 几乎无所不能 。
该模型的出现无疑会带来图像创作领域的一次重大转型 , 跳出传统图像编辑的桎梏 , 迈入到自动化、智能化、创意化的阶段 。 这意味着 , 没有专业化技能的 C 端普通用户得到了一个强大的图像二创工具 , 在大幅提升创作效率的同时还能解锁更多创意空间 。
当然 , 豆包?图像编辑模型 3.0 的应用潜力不局限于日常的修图需求 , 随着更加深入地挖掘广泛的行业特定需求 , 未来它也有望在影视创作、广告设计、媒体、电商、游戏等 AIGC 相关的 B 端市场激发新的应用潜力 , 助力企业提高内容生产效率 , 在竞争中用 AI 抢占先机 。
【P图手残党有救了,豆包·图像编辑模型3.0,一个对话框搞定增删改替】利用该模型 , 影视制作团队可以快速调整镜头画面、添加特效、替换背景等 , 从而简化制作流程、缩短制作周期;电商商家可以快速定制化产品图像和宣传图 , 并根据消费者偏好和市场需求进行个性化创作;游戏开发者可以快速调整角色、场景的设计元素 , 节省时间 。 这些看得见的应用前景 , 显然会带来颠覆性的变化 , 推动行业朝着高效、便捷的方向演进 。
推荐阅读










- 鸿蒙5.1生态加速跑 超多设备可升级解锁独有体验
- Meta太能“抢钱”,难怪小扎有底气疯狂抢人
- 有这桌搭太简单,伸缩线材+多口快充,安克桌面充mix上手体验
- 预算只有两千元该买什么手机?选一加Ace 5至尊版
- 7000大电池+高通新神U+IP65防水防尘,这款899的神机有点猛啊
- 从数字人到有温度的机器人,京东把 AI 深度应用的路线图「摸透」了
- 联想moto razr60冰钻限定版下周发,还有限定版耳机
- 三星多款新机、平板曝光,外观有变动
- 炸圈的ChatGPT Agent ,到底有哪些能耐?能不能替代普通牛马?
- 大模型隐私安全和公平性有“跷跷板”效应,最佳平衡法则刚刚找到