
文章图片

文章图片

文章图片
文章图片

文章图片
本论文由新加坡国立大学、A*STAR 前沿人工智能研究中心、东北大学、Sea AI Lab、Plastic Labs、华盛顿大学的研究者合作完成 。 刘博、Leon Guertler、余知乐、刘梓辰为论文共同第一作者 。 刘博是新加坡国立大学博士生 , 研究方向为可扩展的自主提升 , 致力于构建能在未知环境中智能决策的自主智能体 。 Leon Guertler 是 A*STAR 前沿人工智能研究中心研究员 , 专注于小型高效语言模型研究 。 余知乐是东北大学博士生 , 研究方向为语言模型的对齐和后训练 。 刘梓辰是新加坡国立大学和 Sea AI Lab 的联合培养博士生 , 主要研究语言模型的强化学习训练 。 通讯作者 Natasha Jaques 是华盛顿大学教授 , 在人机交互和多智能体强化学习领域有深厚造诣 。
近年来 , OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力 。 通过基于结果的奖励机制 , 强化学习使模型能够发展出可泛化的推理策略 , 在复杂问题上取得了监督微调难以企及的进展 。
【SPIRAL:零和游戏自对弈成为语言模型推理训练的「免费午餐」】然而 , 当前的推理增强方法面临着根本性的可扩展性瓶颈:它们严重依赖精心设计的奖励函数、特定领域的数据集和专家监督 。 每个新的推理领域都需要专家制定评估指标、策划训练问题 。 这种人工密集的过程在追求更通用智能的道路上变得越来越不可持续 。
来自新加坡国立大学、A*STAR、东北大学等机构的联合研究团队提出了 SPIRAL(Self-Play on zero-sum games Incentivizes Reasoning via multi-Agent multi-turn reinforcement Learning) , 通过让模型在零和游戏中与自己对弈 , 自主发现并强化可泛化的推理模式 , 完全摆脱了对人工监督的依赖 。
论文标题: SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning 论文链接:https://huggingface.co/papers/2506.24119 代码链接:https://github.com/spiral-rl/spiral游戏作为推理训练?。 捍悠丝说绞У木丝缭?
研究团队的核心洞察是:如果强化学习能够从预训练语言模型中选择出可泛化的思维链(Chain-of-Thought CoT)模式 , 那么游戏为这一过程提供了完美的试炼?。 核峭ü溆峁峁┝邸⒖裳橹さ慕崩?, 无需人工标注 。 通过在这些游戏上进行自对弈 , 强化学习能够自动发现哪些 CoT 模式在多样化的竞争场景中获得成功 , 并逐步强化这些模式 , 创造了一个自主的推理能力提升系统 。
最令人惊讶的发现是:仅通过库恩扑克(Kuhn Poker)训练 , 模型的数学推理能力平均提升了 8.7% , 在 Minerva Math 基准测试上更是跃升了 18.1 个百分点!要知道 , 在整个训练过程中 , 模型从未见过任何数学题目、方程式或学术问题 。
SPIRAL 框架:让竞争驱动智能涌现
多回合零和游戏的独特价值
SPIRAL 选择了三种具有不同认知需求的游戏作为训练环境:
井字棋(TicTacToe):需要空间模式识别和对抗性规划 。 玩家必须识别获胜配置、阻止对手威胁并规划多步策略 。 研究团队假设这些技能会迁移到几何问题求解和空间可视化任务 。 库恩扑克(Kuhn Poker):一个最小化的扑克变体 , 只有三张牌(J、Q、K) , 玩家在隐藏信息下进行下注 。 成功需要概率计算、对手建模和不确定性下的决策 。 这些能力预期会迁移到涉及概率、期望值和战略不确定性的问题 。 简单谈判(Simple Negotiation):一个资源交易游戏 , 两个玩家交换具有相反估值的木材和黄金以最大化投资组合价值 。 成功需要多步规划、心智理论建模和通过提议与反提议进行战略沟通 。自对弈的魔力:永不停歇的进化
与固定对手训练相比 , 自对弈具有独特优势 。 研究发现:
对抗强大的固定对手(Gemini-2.0-Flash-Lite):初始胜率为 0%(无学习信号) , 最终停滞在 62.5%(开发出固定的对抗策略) 。 对抗随机对手:完全崩溃 , 由于「回合诅咒」使得完成有效游戏变得极其困难 。 自对弈:始终保持 50-52% 的胜率 , 确认对手与学习者完美同步进化 。这种自适应的难度调整是关键所在 。 随着模型改进 , 它的对手也在改进 , 创造了一个自动调整的课程体系 。
从游戏到数学:推理模式的神奇迁移
三种核心推理模式的发现
通过分析数千个游戏轨迹和数学解题过程 , 研究团队发现了三种在游戏中产生并迁移到数学推理的核心模式:
期望值计算:在游戏中从 15% 增长到 78% 的使用率 , 迁移到数学问题时保持 28% 的使用率 。 例如 , 在扑克中计算「跟注的期望值 = 获胜概率 × 2 - 失败概率 × 2」 , 这种思维直接应用于数学中的概率和优化问题 。 逐案分析:在扑克决策中出现率达 72% , 以 71% 的高保真度迁移到数学问题求解 。 游戏中的「情况 1:弃牌损失 1 筹码;情况 2:跟注但失败损失 2 筹码」模式 , 完美对应数学中的分类讨论方法 。 模式识别:展现出放大效应——游戏中 35% 的使用率在数学领域增长到 45% 。 这表明游戏训练增强了模型本就存在的数学模式识别能力 。不同游戏培养不同技能
实验发现 , 不同游戏确实培养了专门化的认知能力:
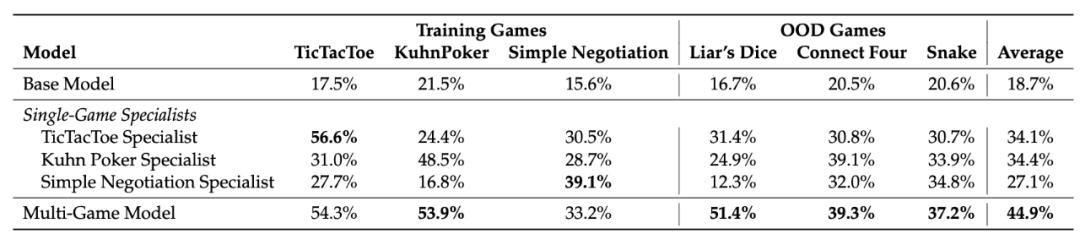
井字棋专家在空间推理游戏 Snake 上达到 56% 胜率 。 库恩扑克大师在概率游戏 Pig Dice 上取得惊人的 91.7% 胜率 。 简单谈判专家在战略优化游戏上表现出色 。
更有趣的是 , 当结合多个游戏训练时 , 技能产生协同效应 。 在 Liar's Dice 上 , 单一游戏专家只能达到 12-25% 的胜率 , 而多游戏训练模型达到 51.4% 。
技术创新:让自对弈稳定高效
分布式在线多智能体强化学习系统
为了实现 SPIRAL , 研究团队开发了一个真正的在线多智能体、多回合强化学习系统 , 用于微调大语言模型 。 该系统采用分布式 actor-learner 架构 , 能够跨多个双人零和语言游戏进行全参数更新的在线自对弈 。
角色条件优势估计(RAE):防止思维崩溃的关键
研究中一个关键发现是 , 没有适当的方差减少技术 , 模型会遭受「思维崩溃」——在 200 步后停止生成推理轨迹 , 收敛到最小输出如「think/thinkanswerbet/answer」 。
角色条件优势估计(RAE)通过为每个游戏和角色维护单独的基线来解决这个问题 。 它考虑了角色特定的不对称性(如井字棋中的先手优势) , 确保梯度更新反映真正的学习信号而不是位置固有的优势 。
实验表明 , 没有 RAE , 数学性能从 35% 崩溃到 12%(相对下降 66%) , 梯度范数趋近于零 。 RAE 在整个训练过程中保持稳定的梯度和推理生成 。
广泛影响:强模型也能受益
SPIRAL 不仅对基础模型有效 。 在 DeepSeek-R1-Distill-Qwen-7B(一个已经在推理基准测试上达到 59.7% 的强大模型)上应用多游戏 SPIRAL 训练后 , 性能提升到 61.7% 。 特别值得注意的是 , AIME 2025 的分数从 36.7% 跃升至 46.7% , 足足提升了 10 个百分点!
这表明竞争性自对弈能够解锁传统训练未能捕获的推理能力 , 即使在最先进的模型中也是如此 。
深入分析:为什么游戏能教会数学?
研究团队认为 , 这种跨领域迁移之所以可能 , 有三个关键因素:
竞争压力剥离记忆依赖:自对弈对手不断进化 , 迫使模型发展真正的推理能力而非模式匹配 。 在传统的监督学习中 , 模型可能通过记忆特定模式来「作弊」 , 但在对抗不断变化的对手时 , 只有真正的推理策略才能持续获胜 。 游戏提供纯净的推理环境:游戏规则简单明确 , 不需要复杂的领域知识 , 让模型能专注学习基本的认知操作(枚举、评估、综合) , 这些操作能够有效泛化 。 库恩扑克中的「如果对手有 K , 我应该弃牌」的推理结构 , 与数学中的条件推理具有相同的逻辑框架 。 结构化输出搭建领域桥梁:在游戏中学习的think格式提供了一个推理支架 , 模型在数学问题中会重用这种结构 。 这种格式化的思考过程成为了跨领域知识迁移的载体 。对强化学习研究的启示
SPIRAL 的独特贡献在于展示了游戏作为推理训练场的潜力 。 虽然 DeepSeek-R1 等模型已经证明强化学习能显著提升推理能力 , 但 SPIRAL 走得更远:它完全摆脱了对数学题库、人工评分的依赖 , 仅凭游戏输赢这一简单信号就实现了可观的推理提升 。
研究还揭示了多智能体强化学习在语言模型训练中的独特价值 。 与单智能体设置相比 , 多智能体环境提供了更丰富的学习信号和更鲁棒的训练动态 。 这为未来的研究开辟了新方向:
混合博弈类型:结合零和、合作和混合动机游戏 , 可能培养更全面的推理能力 。 元游戏学习:让模型不仅玩游戏 , 还能创造新游戏 , 实现真正的创造性推理 。 跨模态游戏:将语言游戏扩展到包含视觉、音频等多模态信息 , 培养更丰富的认知能力 。实践意义与局限性
实践意义
对于希望提升模型推理能力的研究者和工程师 , SPIRAL 提供了一种全新的思路 。 不需要收集大量高质量的推理数据 , 只需要设计合适的游戏环境 。 研究团队已经开源了完整的代码实现 , 包括分布式训练框架和游戏环境接口 。
更重要的是 , SPIRAL 验证了一个关键假设:预训练模型中已经包含了各种推理模式 , 强化学习的作用是从这些模式中筛选和强化那些真正可泛化的思维链 。 这改变了我们对模型能力提升的理解 。 我们不是向模型灌输新的推理方法 , 而是通过竞争压力让有效的推理策略自然胜出 , 无效的被淘汰 。 游戏环境就像一个进化选择器 , 只有真正通用的推理模式才能在不断变化的对手面前存活下来 。
当前局限
尽管取得了显著成果 , SPIRAL 仍有一些局限性需要在未来工作中解决:
游戏环境依赖:虽然消除了人工策划问题的需求 , 但仍需要设计游戏环境 。 计算资源需求:每个实验需要 8 块 H100 GPU 运行 25 小时 , 这对许多研究团队来说是个挑战 。 性能瓶颈:在长时间训练后 , 性能提升会趋于平缓 , 需要新的技术突破 。 评估局限:当前评估主要集中在学术基准测试 , 对现实世界推理任务的影响还需进一步验证 。结语
SPIRAL 的工作不仅仅是一个技术突破 , 更代表了对智能本质的新理解 。 它表明 , 复杂的推理能力可能不需要通过精心设计的课程来教授 , 而是可以通过简单的竞争环境自然涌现 。
当我们看到一个只会下库恩扑克的模型突然在数学考试中表现更好时 , 我们不禁要问:智能的本质到底是什么?也许 , 正如 SPIRAL 所展示的 , 智能不是关于掌握特定知识 , 而是关于发展可以跨越领域边界的思维模式 。
这项研究为自主 AI 发展指明了一个充满希望的方向 。 在这个方向上 , AI 系统通过相互竞争不断进化 , 发现我们从未想象过的推理策略 , 最终可能超越人类设计的任何课程体系 。 正如研究团队在论文中所说:「这只是将自对弈嵌入语言模型训练的第一步尝试 。 」
推荐阅读
















- 淘宝和闲鱼,最终还是被AI这恶作剧玩坏了
- 大模型隐私安全和公平性有“跷跷板”效应,最佳平衡法则刚刚找到
- 华为Mate80突然曝光:外观和配置进一步确认,或10月正式发布
- 击败一加和iQOO,骁龙8至尊领先版+7200mAH,荣耀拿下性价比第1
- 微信转账和红包,原来区别这么大,以后别再用错了
- 砺算科技首款GPU芯片问世!真自研,畅跑3A大作和大模型
- 单项最高奖励15万美元,Meta征集表面肌电图腕带和控制算法提案
- 一加Ace 5 Pro和一加13T怎么选?看完区别后,心里有数了
- 小米16曝光:物理零孔直屏+24GB运存,这才是香饽饽
- 2025年上半年中国彩电市场回暖:销量和销售额双增长