
文章图片
文章图片

文章图片
文章图片

文章图片
近日 , 来自 OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了 Agent KB 框架 。 这项工作通过构建一个经验池并且通过两阶段的检索机制实现了 AI Agent 之间的有效经验共享 。 Agent KB 通过层级化的经验检索 , 让智能体能够从其他任务的成功经验中学习 , 显著提升了复杂推理和问题解决能力 。
- 论文地址:https://arxiv.org/abs/2507.06229
- 开源代码:https://github.com/OPPO-PersonalAI/Agent-KB
Agent 记忆系统:从独立作战到协同学习
在 AI Agent 的发展历程中 , 记忆(memory)系统一直是实现持续学习和智能进化的关键组件 。 广义上的 Agent 记忆系统有用于存储当前对话或任务中的临时信息的短期记忆 , 也有保存重要的知识、经验和学习成果的长期记忆 , 还有处理当前任务时的活跃信息缓存的工作记忆 , 部分还包括记录特定场景下的问题解决策略的情境记忆 。
然而 , 现有的记忆系统存在一个根本性限制:不同的 Agent 框架下的经验无法有效共享 。 由于不同的任务往往有着不同的 multi-agent 框架 , 每当遇到新任务时 , 它们往往需要从零开始探索 , 即使相似的问题解决策略已经在相关领域得到验证 。
Agent KB 正是为了解决这一痛点而生 。 它构建了一个共享的经验池/知识库系统 , 首先让不同的多智能体系统(比如 OpenHands、MetaGPT、AutoGen 等)去执行不同的任务 , 然后将成功的问题解决经验抽象化并存储 。 当遇到新的数据集中的测试例子的时候 , 从历史经验中检索相关的解决策略 , 将其他 agent 的经验适配到新的任务场景 。
该框架的核心技术共享在于提出了一个「Reason-Retrieve-Refine」方案和 Teacher-Student 双阶段的检索机制 , 让 Agent 能够在不同层次上学习和应用历史经验 。
GAIA 基准测试:通用 AI 助手的终极挑战
GAIA(General AI Assistants)被誉为「通用 AI 助手的终极测试」 , 是目前最具挑战性的智能体评估基准之一 。 与传统的 NLP 基准测试不同 , GAIA 专门设计用来评估智能体在现实世界复杂任务中的综合能力 。
GAIA 的核心特点体现在其对真实世界复杂性的还原 。 任务来源于真实的用户需求 , 而非人工构造的简单问题 , 这要求智能体具备多模态交互能力 , 需要处理文本、图像、音频等多种信息类型 。
更重要的是 , 智能体必须具备工具使用能力 , 能够调用搜索引擎、代码执行器、文件处理工具等外部资源 。 大多数任务需要多个推理步骤和中间决策 , 同时对答案的准确性有严格要求 , 容错率极低 。
GAIA 验证集包含 165 个精心设计的测试用例 , 按复杂度分为三个级别 。 Level 1 包含 53 个基础任务 , 需要简单推理或直接信息检索;Level 2 包含 86 个中等复杂度任务 , 需要多步推理或工具组合使用;Level 3 包含 26 个高难度任务 , 需要复杂推理链和专业领域知识 。
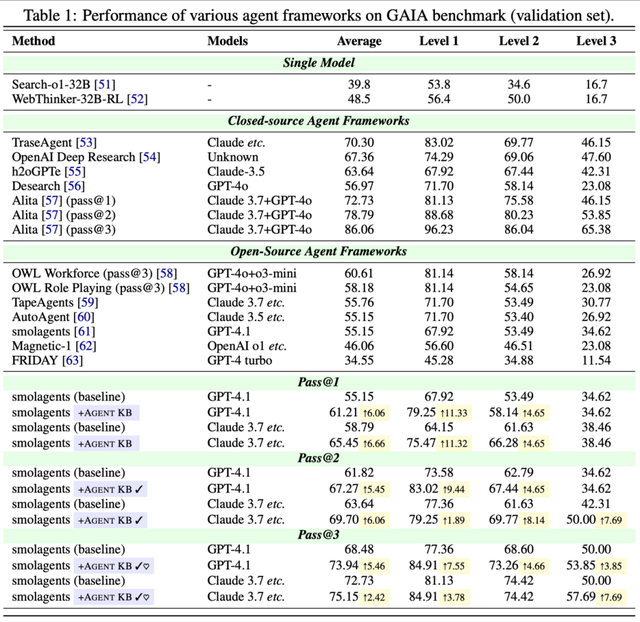
该文的评估指标主要包括 Pass@1(agent 首次尝试的成功率 , 是最严格也最重要的指标)和 Pass@3(三次尝试中至少一次成功的概率 , 用于评估系统的上限) 。 我们发现 Agent KB 作者非常严谨 , 因为有些公司或组织在宣传他们的产品并在 GAIA 上汇报成绩时 , 并不会指出它是 Pass@N 还是 Pass@1 。
实验结果:Agent KB 的表现惊人
在 GAIA 基准测试中 , Agent KB 取得了令人瞩目的成果 。 由于 Agent KB 的研究团队的初衷并不是为了提出一个更新的、更复杂的多智能体框架 。 所以他们选择了相对十分简单甚至结果不是那么理想的 smolagents作为基础智能体框架进行测试 , 这样能够更清晰地展现经验共享机制本身的效果 , 而非复杂框架带来的性能增益 。
- smolagents地址:https://github.com/huggingface/smolagents
实验结果显示 , 在最严格的 Pass@1 评估下 , GPT-4.1 模型的整体性能从基线的 55.15% 大幅跃升至 61.21% , 提升了 6.06 个百分点 。 Claude-3.7 的表现更加出色 , 从 58.79% 提升至 65.45% , 增幅达 6.66 个百分点 。 这一结果尤其令人瞩目 , 因为它表明即使在相对基础的智能体框架上 , Agent KB 也能够实现接近顶级商业系统的性能水平 。
研究团队还测试了六个主流 LLMs 在 Agent KB 增强后的性能表现 。 从 DeepSeek-R1 的稳步改进到 Claude-3.7 的显著飞跃 , 从 GPT-4o 的均衡提升到 o3-mini 的大幅增长 , 所有测试模型都显示出一致的改进趋势 。 这种跨模型、跨难度级别的普遍性改进有力证明了 Agent KB 方法的普适性和可靠性 。
在软件工程领域的 SWE-bench 数据集中 , Agent KB 同样展现出强劲的实用价值 。 该基准包含 300 个来自 11 个流行 Python 仓库的真实 issue , 需要 Agent 理解现有代码库并实施恰当的修复方案 。
o3-mini 在 50 次迭代下从 23.00% 提升到 31.67%(+8.67 个百分点) , 在 100 次迭代下从 29.33% 提升到 33.67%(+4.34 个百分点) 。 这些结果证明了 Agent KB 的跨域知识共享能力不仅适用于通用问答任务 , 在专业的代码修复领域同样发挥着重要作用 。
技术架构:Teacher-Student Agents 协作的精妙设计
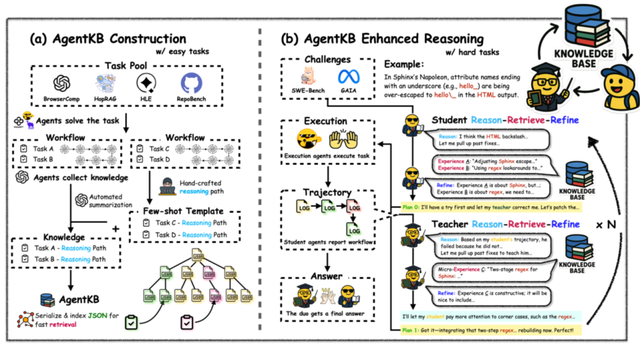
Agent KB 的技术创新核心在于其「Reason-Retrieve-Refine」流程和 Teacher-Student 双阶段检索机制 。 这里通过一个蛋白质数据库(PDB)距离计算案例展示了这一机制的工作原理 。
在传统流程中 , 智能体会盲目读取前两行 ATOM/HETATM/ANISOU 记录 , 经常误选溶剂记录 , 导致计算出错误的 O-H 距离(0.961 ?) 。 而 Agent KB 增强的 agent 则能够应用经验驱动的规则:智能过滤 ANISOU/HETATM 记录 , 专注于真正的 ATOM 条目 , 并通过 N-CA 键长范围的合理性检查进行验证 , 最终精准提取骨架 N-CA 原子对 , 报告出正确的 1.456 ? 距离 。
Agent KB 的深层架构精髓体现在其「Reason-Retrieve-Refine」步骤设计上 , 该方案巧妙地将层级化的经验存储与智能检索机制相结合 。 整个框架围绕两个核心阶段展开:Agent KB 知识构建阶段和 Agent KB 增强的推理阶段 。
在知识构建阶段 , 系统从多元化数据集(BrowserComp、HopRAG、HLE、RepoBench 等)中系统性地提取可泛化的问题解决模式 。 通过自动化摘要和 few-shot 提示 , 原始的输出的 log(日志)被转化为结构化的知识条目 。 这些经验并非简单的 trajectory(执行轨迹) , 而是经过深度抽象处理的 reasoning patterns(推理模式) , 能够跨越任务边界实现有效的知识迁移 。
Agent KB 增强推理阶段的技术创新在于引入了双 Agent 协作机制 , 其中 Student Agent 和 Teacher Agent 则承担着经验检索与适应性指导的互补角色 。 独立于 Agent KB 之外还有 Execution Agent 负责实际任务执行 , 比如作者用 OpenHands 来做 SWE-Bench 的任务 , OpenHands 就是 Execution Agent 。
Student Agent 率先执行完整的 Reason-Retrieve-Refine 循环:通过深度推理分析当前任务特征 , 检索匹配的工作流(workflow)级别的历史经验模式 , 并将这些经验进行适应性修改 , 为 Execution Agent 提供 high-level、整体的解决方案框架指导 。 这一过程确保了执行 Agent 能够基于历史成功经验构建合理的宏观策略 。
Teacher Agent 则扮演着更为精细的监督与优化角色 , 它持续分析 Execution Agent 的输出轨迹 (trajectory) , 敏锐识别其中的潜在问题、执行偏差和效率瓶颈 , 并提供针对性的精细化改进建议 。 当发现问题时 , Teacher Agent 会精准检索相关的 Step(步骤)级别的细粒度经验 , 并将这些经验进行适应性调整 , 为 Execution Agent 提供针对性的精细化改进建议 。 这种分层协作机制的精妙之处在于实现了宏观战略规划与微观执行优化的有机统一:Student Agent 确保整体方向的正确性 , Teacher Agent 保证实施过程的精确性 。
这种分层检索架构以不同粒度满足问题解决各阶段的差异化需求:初期规划阶段 , Student Agent 基于问题特征检索高层 Workflow 经验并进行适应性修改 , 为执行提供战略指导;执行优化阶段 , Teacher Agent 基于实时轨迹检索细粒度经验并进行针对性调整 , 提供战术层面的纠正建议 。 通过将经验存储为抽象化的结构模式而非具体实现细节 , 系统实现了跨域知识的有效迁移 , 使得经过适应性修改的抽象原理能够在新环境中发挥更大的指导价值 。 整个框架采用模块化和框架无关的设计理念 , 不仅能够与多种 Agent 架构无缝集成 , 更为跨框架的经验共享和协作学习开辟了新的可能性 。
深度消融研究验证有效性
为了全面验证 Agent KB 各个组件的独立贡献 , 研究团队设计了系统性的消融实验 。 Table 3 的详细数据揭示了每个关键模块对整体性能的影响程度 。
消融实验的核心发现表明 , 双 Agent 协作架构的每个组件都发挥着不可替代的作用 。 Student Agent 的缺失使得 Level 1 任务结果从 79.25% 下降至 75.47% , 反映了其在初期工作流规划中的关键作用;而 Teacher Agent 的移除则使 Level 1 结果从 79.25% 下降至 73.58% , 凸显了其在早期阶段精细化指导的重要价值 。
最为关键的发现是 Refine 模块的核心地位 。 移除该模块导致最显著的性能下降 , 整体准确率从 61.21% 骤降至 55.15% , 而 Level 3 任务的性能更是从 34.62% 降至 30.77% 。 这一结果充分证明了适应性精炼机制在处理复杂推理任务中的关键作用 , 表明简单的经验检索并不足够 , 必须结合智能化的经验适配才能实现有效的知识迁移 。
检索策略深度分析
Agent KB 采用了多层次的检索机制来确保知识的精准匹配 。 系统实现了三种核心检索方法:
- 文本相似度检索:基于 TF-IDF 等传统信息检索技术 , 通过关键词匹配识别表面相似的任务和解决方案 。
- 语义相似度检索:采用 sentence-transformers/all-MiniLM-L6-v2 等预训练模型 , 将文本编码为高维向量表示 , 通过余弦相似度计算捕捉深层语义关联 。
- 混合检索策略:通过加权融合上述两种方法 。
此外 , 系统还在两个不同的抽象层次进行检索:
- 基于摘要的检索:对执行日志进行高层次概括 , 重点关注整体策略和工作流模式 , 适用于宏观规划指导 。
- 基于批评的检索:专注于错误模式和失败案例 , 通过分析相似的问题情境来提供针对性的改进建议 。
Figure 4 的实验结果揭示了最优检索策略的选择原则:
- 对于基于摘要的检索(左侧面板) , 混合方法在各个难度级别上都表现最佳 , 在 GAIA Level 1 任务上达到 83% 的准确率 , 在 SWE-bench 上实现 37% 的解决率 。 这表明宏观策略规划需要兼顾关键词精确匹配和语义理解的双重优势 。
- 对于基于批评的检索(右侧面板) , 文本相似度在 Level 2 任务上表现突出(67%) , 而语义相似度在 SWE-bench 上更有优势(33%) 。 这说明错误模式匹配更依赖于具体的实现细节和精确的问题描述 。
这些发现的深层含义在于 , 不同类型的知识检索需要匹配相应的检索策略 。 基于摘要的检索更适合宏观策略匹配 , 因此混合方法能够兼顾关键词匹配和语义理解的优势;而基于批评的检索更关注具体执行细节 , 文本相似度能够精确捕捉相似的错误模式和解决方案 。
这种分层检索架构体现了 Agent KB 的精妙设计:在不同的问题解决阶段采用最适合的检索策略 , 既保证了知识匹配的准确性 , 又实现了跨任务的有效泛化 。
错误分析揭示改进机制
Figure 5 通过精确的错误统计分析 , 深入揭示了 Agent KB 改善智能体推理能力的内在机制 。 维恩图的重叠区域分析表明 , Agent KB 的改进并非简单的错误替换 , 而是有选择性的智能化优化过程 。
对于 GPT-4.1 , 在总计 89 个错误案例中 , 49 个错误在基线和 Agent KB 配置中均出现 , 表明这些是模型固有的难以克服的限制 。 关键的改进体现在 Agent KB 成功纠正了 25 个基线特有错误 , 同时仅引入 15 个新错误 , 实现净减少 10 个错误实例的积极效果 。 Claude-3.7 的表现模式相似但更为出色 , 在总计 79 个错误中 , 纠正了 22 个基线错误 , 引入 11 个新错误 , 净改进达 11 个实例 。
错误类型的细分析显示了 Agent KB 改进的针对性 。 检索错误从 24 个减少到 20 个 , 规划错误从 13 个减少到 10 个 , 这种改进直接源于 Agent KB 知识库中包含的相似搜索协议和标准化工作流 。 Agent 通过这些结构化经验能够采用更加稳定和有效的问题解决路径 , 避免了随机探索导致的错误 。 同时 , 格式错误的显著减少表明 Agent 通过学习相似任务的成功案例 , 掌握了更精确的输出规范 。
技术意义与产业价值
Agent KB 的成功为 Deep Research 领域开辟了新的技术路径 。 通过让 Agent 学会从历史经验中提炼深层洞察 , 系统展现出了向自主研究能力演进的潜力 。 未来的 Agent 自我进化机制将不再依赖人工标注 , 而是通过持续的经验积累和跨域知识迁移实现能力的螺旋式提升 。
【经验池让Agents互相学习!GAIA新开源SOTA,Pass】Agent KB 在 GAIA 基准上创造的开源 SOTA 记录仅是其技术价值的冰山一角 。 其展现的跨任务知识迁移能力和协作学习机制 , 为构建下一代具备自我进化能力的 AI 系统提供了核心技术支撑 。
推荐阅读














- 马斯克承诺年底让一半美国人坐上无人出租车,网友:先解决FSD再说
- 你iPhone电池有救了,健康度不会掉到80%以下了?
- 2.5K屏幕+9000mAh电池 REDMI Pad 2平板电脑官宣
- iPhone 17 Air,这电池容量疯了吧?
- 轻薄与智慧并重,OPPO Find N5让人一见倾心!
- iQOO新机曝光:8000mAh大电池配天玑9400+旗舰芯,确实有点猛!
- 跑分高达238万,1.5K屏+6400mAH大电池,拿下千元机性价比第1名
- 荣耀Magic8再次被确认:超级AI+计算赋能,影像或让友商望尘莫及
- 性能强才是真的强!8000mAh电池配天玑9400+芯,还是iQOO更懂用户
- 一天三充?iPhone 17 Air电池容量成最大“槽点”