
文章图片

文章图片
文章图片
文章图片

作者 林易
编辑 重点君
从全球爆火 , 到成功融资 , 再到被曝删博、裁员、跑路新加坡 , Manus仅仅用了四个月 , 就把一条新兴赛道的创业演示了个遍 。
有人认为Manus开了一个很坏的头 , 利用中国工程师资源打造产品 , 迅速融资 , 裁员跑路......
在一片争议声中 , 今天凌晨 , 这家公司的联合创始人季逸超罕见发声 , 发布了长达数千字的博客 , 试图把舆论拉回到产品和技术本身 , 也第一次公开回应了这场起落背后的关键教训 。
四个月从爆火到争议
我们先简单回顾一下 。 今年3月 , Manus因“全球首个通用Agent”概念走红 , 当时有人说这是中国的“第二个DeepSeek时刻” 。
5月 , Manus很快完成由硅谷顶级风投Benchmark领投的7500万美元B轮融资 , 估值飙升至5亿美元 。 外界对它的一度期待极高 。
但6月底 , Manus突然被媒体曝出多起争议事件:部分员工称被无预警裁员、创始团队在社交平台上大规模删博、公司主体搬到新加坡 , 舆论哗然 。
一时间 , 删博、裁员、跑路 , 成了这家明星Agent创业公司的主要标签 。
联合创始人凌晨发长文
面对外界质疑 , 季逸超这次选择用一篇技术向的长文作答 , 首次系统总结了团队对Agent产品和技术的核心认知:
1、选择上下文工程 , 而非端到端自研大模型 。 Manus创始人上一家公司曾尝试从零训练NLP模型 , 结果被GPT-3等大模型淘汰 。 这次复盘后 , 他们选择不再自研底层模型 , 而是专注于如何基于开源或商业大模型 , 做“上下文工程” , 把现有能力最大化发挥出来 。
2、KV缓存命中率是代理系统的核心指标 。 多轮智能代理与单轮聊天不同 , 输入输出比可能高达100:1 , 长输入会极大影响延迟和推理成本 。 上下文设计的目标是最大化KV缓存命中率 , 这要求提示要稳定、上下文只追加不修改、保证前缀可重复利用 。
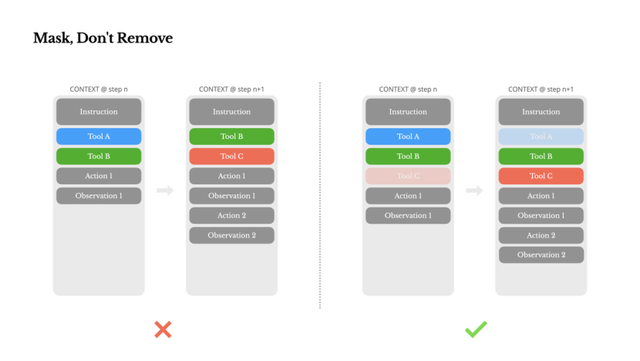
3、工具管理避免动态增减 , 用遮蔽代替删除 。 代理功能多 , 动作空间会迅速扩大 , 模型更易选错 。 动态添加或删除工具会导致缓存失效 。 Manus的实践是用上下文状态机管理工具可用性:通过屏蔽Token概率 , 而非直接从上下文移除 , 既保证灵活性 , 又保留缓存 。
4、把文件系统当作无限上下文 。 大模型上下文窗口再大也有限 , 且超长上下文会拉低推理速度、抬高成本 。 Manus做法是把文件系统当作代理的外部记忆 , 信息可随时存取 , 保证历史状态可查、可读写、可恢复 。
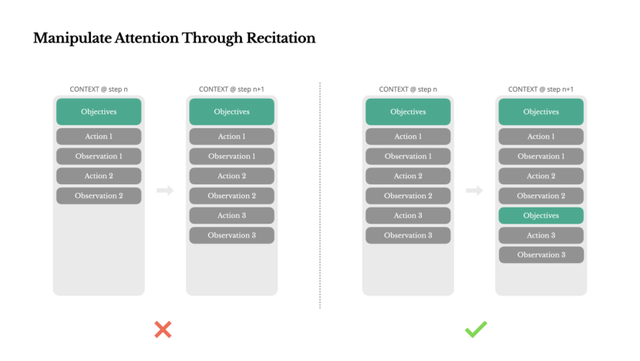
5、用显式“背诵”机制操控模型注意力 。 在长任务中 , Manus会自动生成todo.md , 把任务拆解成可执行清单 , 并不断更新 , 把目标重复写到上下文末尾 , 相当于“反复提醒模型” , 避免任务中途跑偏 。
6、不抹掉错误 , 保留失败信息以帮助模型自我修正 。 智能体必然会出错 , 与其隐藏错误、重新开始 , 不如把失败信息留在上下文里 , 让模型“看到”失败路径 , 形成负面示例 , 从而减少同类错误 。
7、一句话总结就是:上下文工程是一门新兴的实验科学 , Manus想用上下文塑造代理的行为和能力:不是比拼模型多聪明 , 而是比拼怎么让模型更有用 。
复盘之外 , 争议未平息
从这篇博客看得出 , Manus并非完全是个“PPT项目” 。 它确实做了不少面向Agent场景的底层探索 , 也踩过不少坑 。
但这篇长文没提到外界最关心的问题:公司为什么要搬去新加坡?国内被裁员工如何善后?等等 。
这些问题 , 季逸超没有回答 , 博客里也没提 。
季逸超在结尾写道:“智能代理的未来将由一个个情境逐步构建 。 精心设计每一个情境 。 ”
当下的现实是 , Manus是否还有机会把这些“情境”从技术文档带回真正的用户手里?
一切仍未有定论 。
博文链接:
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
以下为Manus 联合创始人季逸博客原文(由GPT翻译):
面向AI 代理的上下文工程:构建 Manus 的经验教训
2025 年 7 月 18 日 季逸超
在Manus 项目伊始 , 我和团队面临一个关键抉择:是使用开源基础模型训练一个端到端的代理模型 , 还是基于前沿模型的上下文学习能力构建代理?
回想我在自然语言处理领域的最初十年 , 我们没有这样的选择余地 。 在BERT 的远古时代(是的 , 已经七年了) , 模型必须经过微调并评估后才能迁移到新任务 。 即使当时的模型远小于如今的 LLMs , 这一过程每次迭代往往也需数周 。 对于快速发展的应用 , 尤其是产品市场匹配前期 , 这样缓慢的反馈周期是致命的 。 这是我上一家创业公司的惨痛教训 , 当时我从零开始训练模型用于开放信息抽取和语义搜索 。 随后 GPT-3 和 Flan-T5 的出现 , 让我自研的模型一夜之间变得无关紧要 。 讽刺的是 , 正是这些模型开启了上下文学习的新纪元——也为我们开辟了一条全新的前进道路 。
这个来之不易的教训让选择变得清晰:Manus 将押注于上下文工程 。 这使我们能够在数小时内发布改进 , 而不是数周 , 同时保持我们的产品与底层模型正交:如果模型进步是涨潮 , 我们希望 Manus 是船 , 而不是固定在海床上的柱子 。
然而 , 上下文工程远非简单 。 这是一门实验科学——我们已经重建了四次代理框架 , 每次都是在发现了更好的上下文塑造方法之后 。 我们亲切地称这种手动的架构搜索、提示调整和经验猜测过程为“随机梯度下降” 。 它不优雅 , 但有效 。
这篇文章分享了我们通过自己的“SGD”达到的局部最优解 。 如果你正在构建自己的 AI 代理 , 希望这些原则能帮助你更快收敛 。
围绕KV 缓存设计
如果只能选择一个指标 , 我认为KV 缓存命中率是生产阶段 AI 代理最重要的指标 。 它直接影响延迟和成本 。 要理解原因 , 我们先看看典型代理的工作方式:
在接收到用户输入后 , 代理通过一系列工具调用来完成任务 。 在每次迭代中 , 模型根据当前上下文从预定义的动作空间中选择一个动作 。 然后在环境中执行该动作(例如Manus 的虚拟机沙箱) , 以产生观察结果 。 动作和观察结果被追加到上下文中 , 形成下一次迭代的输入 。 这个循环持续进行 , 直到任务完成 。
正如你所想象的 , 上下文随着每一步增长 , 而输出——通常是结构化的函数调用——则相对较短 。 这使得预填充与解码之间的比例在代理中远远偏高 , 区别于聊天机器人 。 例如 , 在 Manus 中 , 平均输入与输出的Token比约为100:1 。
幸运的是 , 具有相同前缀的上下文可以利用KV 缓存 , 这大大减少了首次生成标记时间(TTFT)和推理成本——无论你是使用自托管模型还是调用推理 API 。 这里的节省可不是小数目:以 Claude Sonnet 为例 , 缓存的输入标记费用为 0.30 美元/千标记 , 而未缓存的则为 3 美元/千标记——相差 10 倍 。
从上下文工程的角度来看 , 提高KV 缓存命中率涉及几个关键做法:
保持提示前缀稳定 。 由于LLMs 的自回归特性 , 即使是单个标记的差异也会使该标记及其之后的缓存失效 。 一个常见错误是在系统提示开头包含时间戳——尤其是精确到秒的时间戳 。 虽然这样可以让模型告诉你当前时间 , 但也会大幅降低缓存命中率 。
使你的上下文仅追加 。 避免修改之前的操作或观察 。 确保你的序列化是确定性的 。 许多编程语言和库在序列化JSON 对象时不保证键的顺序稳定 , 这可能会悄无声息地破坏缓存 。
在需要时明确标记缓存断点 。 一些模型提供商或推理框架不支持自动增量前缀缓存 , 而是需要在上下文中手动插入缓存断点 。 设置这些断点时 , 应考虑缓存可能过期的情况 , 至少确保断点包含系统提示的结尾部分 。
此外 , 如果你使用像vLLM 这样的框架自托管模型 , 确保启用了前缀/提示缓存 , 并且使用会话 ID 等技术在分布式工作节点间一致地路由请求 。
遮蔽 , 而非移除
随着你的智能体功能不断增强 , 其动作空间自然变得更加复杂——简单来说 , 就是工具数量激增 。 最近 MCP 的流行更是火上浇油 。 如果允许用户自定义工具 , 相信我:总会有人将数百个神秘工具接入你精心策划的动作空间 。 结果 , 模型更可能选择错误的动作或走低效路径 。 简而言之 , 你的重装智能体反而变得更笨 。
一种自然的反应是设计动态动作空间——或许使用类似 RAG 的方式按需加载工具 。 我们在 Manus 中也尝试过 。 但实验表明一个明确的规则:除非绝对必要 , 避免在迭代过程中动态添加或移除工具 。 主要有两个原因:
在大多数LLMs 中 , 工具定义在序列化后通常位于上下文的前部 , 通常在系统提示之前或之后 。 因此 , 任何更改都会使所有后续操作和观察的 KV 缓存失效 。
当之前的操作和观察仍然引用当前上下文中不再定义的工具时 , 模型会感到困惑 。 如果没有受限解码 , 这通常会导致模式违规或幻觉操作 。
为了解决这一问题 , 同时提升动作选择的效果 , Manus 使用了一个上下文感知的状态机来管理工具的可用性 。 它不是移除工具 , 而是在解码过程中屏蔽Token的对数概率 , 以根据当前上下文防止(或强制)选择某些动作 。
在实际操作中 , 大多数模型提供商和推理框架都支持某种形式的响应预填充 , 这使你可以在不修改工具定义的情况下限制动作空间 。 函数调用通常有三种模式(我们以NousResearch 的 Hermes 格式为例):
自动– 模型可以选择是否调用函数 。 通过仅预填回复前缀实现:|im_start|assistant
【Manus“删博、裁员、跑路新加坡”后,创始人首次复盘经验教训】必需——模型必须调用一个函数 , 但选择不受限制 。 通过预填充到工具调用标记实现:|im_start|assistanttool_call
指定——模型必须从特定子集中调用函数 。 通过预填充到函数名开头实现:|im_start|assistanttool_call{\"name\": “browser_
利用此方法 , 我们通过直接屏蔽标记的对数概率来限制动作选择 。 例如 , 当用户提供新输入时 , Manus 必须立即回复 , 而不是执行动作 。 我们还特意设计了具有一致前缀的动作名称——例如 , 所有与浏览器相关的工具都以 browser_开头 , 命令行工具以 shell_开头 。 这使我们能够轻松确保代理在特定状态下仅从某一组工具中选择 , 而无需使用有状态的对数概率处理器 。
这些设计有助于确保Manus 代理循环保持稳定——即使在模型驱动架构下也是如此 。
将文件系统用作上下文
现代前沿的LLMs 现在提供 128K Token或更多的上下文窗口 。 但在现实世界的智能代理场景中 , 这通常不够 , 有时甚至成为负担 。 有三个常见的痛点:
观察内容可能非常庞大 , 尤其是当代理与网页或PDF 等非结构化数据交互时 。 很容易超出上下文限制 。
即使窗口技术上支持 , 模型性能在超过某个上下文长度后往往会下降 。
长输入代价高昂 , 即使使用前缀缓存也是如此 。 你仍然需要为传输和预填充每个标记付费 。
为了解决这个问题 , 许多智能体系统实施了上下文截断或压缩策略 。 但过度压缩不可避免地导致信息丢失 。 问题是根本性的:智能体本质上必须基于所有先前状态来预测下一步动作——而你无法可靠地预测哪条观察在十步之后可能变得关键 。 从逻辑角度看 , 任何不可逆的压缩都存在风险 。
这就是为什么我们将文件系统视为Manus 中的终极上下文:大小无限 , 天生持久 , 并且可以由智能体自身直接操作 。 模型学会按需写入和读取文件——不仅将文件系统用作存储 , 更作为结构化的外部记忆 。
我们的压缩策略始终设计为可恢复的 。 例如 , 只要保留网址 , 网页内容就可以从上下文中删除;只要沙盒中仍有文档路径 , 文档内容也可以省略 。 这使得Manus 能够缩短上下文长度而不永久丢失信息 。
在开发此功能时 , 我不禁想象 , 状态空间模型(SSM)要在具代理性的环境中有效工作需要什么条件 。 与 Transformer 不同 , SSM 缺乏完全的注意力机制 , 难以处理长距离的向后依赖 。 但如果它们能掌握基于文件的记忆——将长期状态外部化而非保存在上下文中——那么它们的速度和效率可能会开启新一代代理 。 具代理性的 SSM 或许才是神经图灵机的真正继任者 。
通过背诵操控注意力
如果你使用过Manus , 可能会注意到一个有趣的现象:在处理复杂任务时 , 它倾向于创建一个 todo.md 文件 , 并随着任务的推进逐步更新 , 勾选已完成的事项 。
这不仅仅是可爱的行为——这是一种有意操控注意力的机制 。
Manus 中的一个典型任务平均需要大约 50 次工具调用 。 这是一个较长的循环——由于 Manus 依赖 LLMs 进行决策 , 因此在长上下文或复杂任务中 , 容易偏离主题或忘记之前的目标 。
通过不断重写待办事项清单 , Manus 将其目标反复写入上下文末尾 。 这将全局计划推入模型的近期注意力范围 , 避免了“中途丢失”问题 , 减少了目标不一致的情况 。 实际上 , 它利用自然语言来引导自身关注任务目标——无需特殊的架构改动 。
保留错误信息
智能体会犯错 。 这不是漏洞——这是现实 。 语言模型会产生幻觉 , 环境会返回错误 , 外部工具会出现异常 , 意外的边缘情况时常发生 。 在多步骤任务中 , 失败不是例外;它是循环的一部分 。
然而 , 一个常见的冲动是隐藏这些错误:清理痕迹 , 重试操作 , 或重置模型状态 , 寄希望于神奇的“温度”参数 。 这看起来更安全、更可控 。 但这付出了代价:抹去失败就抹去了证据 。 没有证据 , 模型就无法适应 。
根据我们的经验 , 改善智能体行为的最有效方法之一看似简单:在上下文中保留错误的路径 。 当模型看到失败的操作及其产生的观察结果或堆栈跟踪时 , 它会隐式地更新内部信念 。 这会使其先验偏离类似的操作 , 从而减少重复同样错误的可能性 。
事实上 , 我们认为错误恢复是衡量真正智能体行为的最明确指标之一 。 然而 , 在大多数学术研究和公开基准测试中 , 这一指标仍然被忽视 , 这些研究和测试通常侧重于理想条件下的任务成功率 。
避免被少量示例限制
少量示例提示是提升LLM 输出的常用技巧 。 但在智能体系统中 , 它可能以微妙的方式适得其反 。
语言模型擅长模仿;它们会复制上下文中的行为模式 。 如果你的上下文充满了类似的过去动作-观察对 , 模型往往会遵循这种模式 , 即使这已不再是最优选择 。
在涉及重复决策或操作的任务中 , 这可能会带来危险 。 例如 , 在使用Manus 帮助审查一批 20 份简历时 , 代理经常陷入一种节奏——仅仅因为上下文中出现了类似内容 , 就重复执行相似的操作 。 这会导致偏离、过度泛化 , 甚至有时产生幻觉 。
解决方法是增加多样性 。 Manus 在动作和观察中引入少量结构化的变化——不同的序列化模板、替代表达、顺序或格式上的细微噪声 。 这种受控的随机性有助于打破模式 , 调整模型的注意力 。
换句话说 , 不要让少量示例把自己限制在固定模式中 。 上下文越统一 , 代理就越脆弱 。
结论
上下文工程仍是一门新兴科学——但对于代理系统来说 , 它已经至关重要 。 模型可能变得更强大、更快速、更廉价 , 但再强的原始能力也无法替代记忆、环境和反馈的需求 。 你如何塑造上下文 , 最终决定了代理的行为:运行速度、恢复能力以及扩展范围 。
在Manus , 我们通过反复重写、走过死胡同以及在数百万用户中的实际测试 , 学到了这些经验 。 我们在这里分享的内容并非普遍真理 , 但这些是对我们有效的模式 。 如果它们能帮助你避免哪怕一次痛苦的迭代 , 那么这篇文章就达到了它的目的 。
智能代理的未来将由一个个情境逐步构建 。 精心设计每一个情境 。
推荐阅读











- 芯片与稀土的“阳谋”:美国出招,中国拆招,华为昇腾芯要起飞了
- 狂揽1200万美金,当AI遇上“玄学”,美国人也为“东方神秘力量”疯狂
- 00后融资420万美金,用数学天才的方法解决AI最头疼的“找错信息”问题
- 2025“信号最佳”的5款手机,全都是16GB+512GB,可以流畅用五年
- 2025有望“卖爆”的旗舰手机,小米16 Pro只能排第三
- 华为Pura80Pro降价暗藏玄机,标准版即将上市,或低至“小米价”
- 6000档高端机推荐排行:谁才是你心中的“真旗舰”?
- 1189元!荣耀X70正式开售,这次“真香”了吗?
- 华为开始“五折”清仓,昆仑玻璃+卫星通信+100W,花粉可以入手了
- 7500mAH大电池以上,堪称“续航王”的3款手机,两天1充无压力