
文章图片
文章图片
本文由半导体产业纵横(ID:ICVIEWS)编译自the next platform
【新旧GPU对决:Blackwell凭啥更能打?】
AWS Blackwell GPU性价比解析 。
本周 , 亚马逊网络服务宣布推出其首款基于Nvidia的“Grace”CG100 CPU和“Blackwell”B200 GPU的UltraServer预配置超级计算机 , 称为GB200 NVL72共享GPU内存配置 。 这些机器被称为U-P6e实例 , 实际上有全机架和半机架配置 , 它们补充了去年12月在re:Invent 2024会议上推出的现有P6-B200实例 。
在P6和P6e实例的情况下 , GPU和NVLink Switch 4 GPU内存共享交换机上的NVLink 5端口用于将GPU组整合到大型共享内存计算复合体中 , 类似于CPU服务器存在了25多年的NUMA集群 。 其他非NUMA共享内存架构比非统一内存访问技术更古老 , 如对称多处理或SMP , 但没有像NUMA在CPU上的扩展 , 在单核处理器时代 , NUMA在共享内存集群中推到了128和256个CPU 。
基于Nvidia NVL72设计的P6e实例 , 我们在这里详细介绍了这些设计 , GPU内存域横跨72个GPU插槽 , Blackwell芯片每个插槽有两个GPU芯片 , 因此内存域实际上是单个机架中的144个设备 。 AWS正在销售具有72或36个Blackwell B200插槽的UltraServers作为内存域 , 估计这是虚拟完成的 , 而不是物理完成的 , 因此可以即时配置实例大小 。 这些机器每两个Blackwell B200 GPU配对一个Grace CPU , 整个shebang是液冷的 , 这也是B200 GPU超频11%的原因之一 , 并为人工智能工作负载提供更多的原始计算性能 。
P6实例使用更标准的HGX-B200服务器节点 , 这些节点没有超频 , 并创建了一个跨越八个套接字的GPU内存域 。 P6实例使用英特尔至强6处理器作为其主机计算引擎 , 每八个Blackwell B200 GPU有两个CPU , 产生的计算复合体密度是GB200 NVL72系统的一半 , 因此仍然可以风冷 。
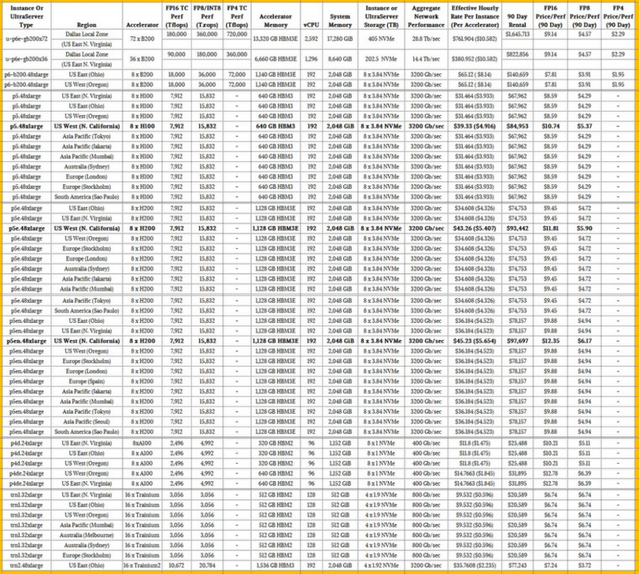
随着这两个Blackwell系统现在在AWS云上可用 , 并且价格信息可用 , 现在是对Blackwell实例进行一些价格/性能分析的最佳时机 , 与前几代“Hopper”H100和H200 GPU以及基于“Ampere”A100和“Volta”V100 GPU的早期实例进行一些价格/性能分析 , 这些实例仍然可以在AWS云上租用 。
我们检查的实例和UltraServer机架规模配置是在AWS所谓的EC2容量块下出售的 , 顾名思义 , 这是预订和购买预配置的UltraClusters的一种方式 , 其大小从一个实例或UltraServer到多达64个实例或机架 , 期限长达六个月 , 最多在您需要容量的八周前 。 这是一个预留实例的时髦版本 , 以更大的块状形式作为单个单元出售 。
只是为了好玩 , 我们采取了EC2容量块配置 , 还找到了按需定价的设置 , 看看这些在成本上如何比较 , 一直到基于Nvidia Volta GPU的P2实例和基于Ampere GPU的P3实例 。
因此 , 未来不假说 , 这是EC2容量块的所有电子表格的母体 , 价格显示在全球可用的地区 , 包括Nvidia GPU实例以及AWS Trainium1和Trainium2实例:
那里有很多东西需要接受 。 为了了解价格/性能是如何叠加的 , 我们添加了FP16、FP8或INT8和FP4精度的峰值理论性能 。 为了进行比较 , 我们忽略了FP64和FP32精度 , 充分意识到有时更高的精度计算用于人工智能模型 , 当然也用于HPC模拟 。 这些性能评级适用于密集数学 , 而不是稀疏矩阵 , 这可以使设备的有效数值吞吐量翻倍 。
我们决定 , 90天的租赁代表了训练一个相当大的模型需要什么 , 但没什么疯狂的 。 这种实例成本的规模产生了一个很好的红利 , 其中除数将它切成太浮点运算的性能 。
很多东西都跳出这个怪物表 , 但我们看到的第一个 , 我们用粗体强调的是 , AWS对基于美国西北加州地区提供的Hopper H100和H200 GPU的GPU实例收取25%的溢价 。 在硅谷很难获得电力和数据中心空间 , 这就是为什么你看到美国西部地区的俄勒冈州地区安装了这么多新设备 。 美国东部地区锚定在弗吉尼亚州阿什本周围 , 它仍然首先获得许多好东西 , 包括基于GB200 NVL72设计的UltraServer P6e机架系统 。 正如你所看到的 , 俄亥俄州的美国东部地区也获得了新东西的份额 , 包括Trainium1和Trainium2集群 。
我们认为FP16性能是人工智能加速器的基线 , 然后FP8和FP4精度是模型的重要进一步加速器 , 这些模型可以使用较低分辨率的数据进行训练 , 并且仍然不会牺牲模型的准确性 。
如果你看一下机架式GB200 NVL72系统的FP16性能与HGX-B200系统相比 , 后者的扩展幅度没有那么大 , 机架式机——需要液体冷却 , 安装有点像野兽——与AWS租用的方式相比 , 单位性能仅提高了17% 。 这其实并不是什么溢价 , 考虑到系统的密度以及GB200 NVL72的密度导致的电源和冷却问题 , 这符合您的预期 。
您将看到的另一件事是 , H100和H200设备具有相同的峰值理论性能 , 但AWS安装的H100是较早的 , 只有80 GB的HBM3容量 , 而H200具有141 GB的HBM3容量 。 AWS正在为该内存和附带的更高带宽收取10%的溢价 。 带有80 GB HBM3的H100带宽为3.35 TB/秒 , 而带有141 GB HBM3E的H200提供4.8 TB/秒的带宽 。 对于许多工作负载 , 这种额外的内存容量和带宽几乎可以使人工智能培训的实际性能增加一倍 。 您可能期望AWS对H200实例收取比它更多的溢价 。
EC2容量块仍然可以使用Ampere A100 GPU加速器获得 , 有趣的是 , 按GPU计算 , H200比A100贵3.07倍 , 但它每个GPU的FP16性能高3.17倍 。 当你计算时 , 通过容量块租用具有40GB HBM2内存的A100 90天 , 每兆浮点运算的成本为10.21美元 , 而H100的每兆浮点运算成本为9.88美元 。 只有当你无法获得H100s、H200s或B200s时 , 你才会这样做 。 带有80GB HBM2内存的A100每TBflops售价为12.78美元 。 (所有这些价格都适用于北加州以外的地区 。 )
在FP16精度下 , P6e实例中的全尺寸NVL72机器 , 配有72个Blackwell B200 GPU , 以及带有36个Blackwell B200的半机架 , 每兆浮点运算成本为9.14美元 , 租金为90天 , 这三个月将分别花费165万美元和822856美元 。 具有较小内存域的P6-B200实例在FP16精度下 , 在90天内每兆浮点运算花费7.81美元 , 鉴于这些实例是空气冷却的 , 内存域较小 , 这是有道理的 。 神奇的是 , 液冷GB200 NVL72机器的价格并不高 。
如果你看一下FP8的性能 , 每太浮点运算的所有成本都减半了 , 而Blackwells , 以FP4格式计算的能力将一亿浮点运算的成本再次减半 。 最终结果是 , 如果您更改模型以利用FP4性能 , 您可以租用四分之一的机器以四分之一的成本完成相同的工作 , 或者您可以花费相同的钱来训练一个大四倍的模型 。
现在看看桌子的底部和Trainium 。 在原始FP16吞吐量方面 , 需要两倍于AWS设计的Trainium1人工智能加速器才能击败Nvidia A100约22% 。 使用Trainium2 , FP16的性能提高了3.5倍 , FP8的性能提高了6.8倍 , 而HBM容量提高了3倍 , 但在FP16分辨率下 , 每兆浮点运算的成本仅提高了7.4% 。 增加FP8将FP8精度的太浮点运算的价格降低到仅3.72美元 , 这低于AWS租用的HGX-B200节点作为P6实例的每兆浮点运算3.91美元 , 甚至低于AWS为GB200 NVL72实例收取的每兆浮点运算4.57美元 。 Trainium2不支持FP4 , 这意味着在原始成本方面 , Nvidia对那些可以以FP4分辨率运行且不会失去准确性的人工智能应用程序具有优势 。
现在 , 如果您查看AWS上的按需定价 , Trainium1芯片仍然可用 , 而且它们比按需租用的Blackwell B200实例要贵得多 。 看一看:
本表中显而易见的是 , 基于K40、V100和A100 GPU的古代加速器实例成本非常低 , 因此资本支出非常低 , 这看起来很有吸引力 , 但如果你看一下FP16 ooph的太浮点运算成本 , 这些在经济意义上是可怕的 , 并且与EC2容量块计划下出售的新铁的差距要大得多 。 如果您将这些在FP16模式下运行的古老GPU与在FP4模式下运行的Blackwells进行比较 , 除了在绝对紧急情况下 , 否则考虑使用这种旧的熨斗是彻头彻尾的愚蠢 。
显然 , 如果您需要按需租用实例 , 请租用Blackwells并在FP4模式下运行 。 如果你这样做 , FP16性能的成本会降低9% , 通过精密两档的降档 , 你可以将性能提高4倍 , 将性价比提高4.4倍 。
摩尔定律只有在缩小精度的幌子下才真正存在 , 而不是在缩小晶体管的幌子上 。 FP2有人吗?正如一些人所说 , FP1中没有意义 。
*声明:本文系原作者创作 。 文章内容系其个人观点 , 我方转载仅为分享与讨论 , 不代表我方赞成或认同 , 如有异议 , 请联系后台 。
想要获取半导体产业的前沿洞见、技术速递、趋势解析 , 关注我们!
推荐阅读














- 英伟达慌不慌?华为AI芯片方案,要从ASIC转向GPGPU了
- 华为Mate 80 GPU性能暴涨100% 影像系统再造「折叠光路」
- 小米15对决vivo X200 Pro mini,小屏旗舰谁更香?
- 蓝牙音箱哪个牌子的好?西圣和雷登蓝牙音箱双强对决揭晓!
- 马斯克20万GPU训出史上最聪明AI,Grok 4重返地球之巅,人类博士全线溃败
- 从CPU,到GPU,到Soc,中国已有自主研发的高性能芯片了
- Imagination回应GPU部门被中芯收购:不实消息 纯属虚构
- 口碑又要崩了?小米回应路由器偷偷减配:新旧产品性能一致
- 蓝牙音箱哪个牌子音质最好?10大蓝牙音箱测评巅峰对决,新手必看
- 刚刚,Ilya官宣出任SSI CEO,送走“叛徒”联创,豪言不缺GPU