
文章图片
【北大、北邮、华为开源纯卷积DiC:3x3卷积实现SOTA性能比DiT快5倍】
文章图片

文章图片
文章图片
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时 , 一项来自北大、北邮和华为的最新研究却反其道而行之 , 重新审视了深度学习中最基础、最经典的模块——3x3 卷积 。
他们提出的 DiC (Diffusion CNN) , 一个纯卷积的扩散模型 , 不仅在性能上超越了广受欢迎的 Diffusion Transformer (DiT) , 更在推理速度上实现了惊人的提升 。 这项工作证明了 , 经过精心设计 , 简单的卷积网络依然能在生成任务中登峰造极 。
- 论文标题:DiC: Rethinking Conv3x3 Designs in Diffusion Models
- 论文链接:https://arxiv.org/abs/2501.00603
- 项目主页/代码:https://github.com/YuchuanTian/DiC
引言
从 Stable Diffusion 到 Sora , 基于 Transformer 的扩散模型已经成为 AIGC 领域的绝对主流 。 它们强大的可扩展性和卓越的生成效果令人惊叹 , 但也带来了巨大的计算开销和缓慢的推理速度 , 成为实际应用中的一大瓶颈 。
我们真的只能在 Transformer 这条路上走到底吗?
在这篇论文中 , 研究者们给出了一个响亮的否定答案 。 他们大胆地抛弃了复杂的自注意力机制 , 回归到了最纯粹的 3x3 卷积 , 并构建了一个兼具速度与性能的全新扩散模型架构——DiC 。
返璞归真:为什么选择 3x3 卷积
在 AI 硬件和深度学习框架(如 cuDNN)的加持下 , 3x3 卷积是硬件支持最好、优化最彻底的算子之一 。 得益于像 Winograd 这样的高效算法 , 它的计算速度远超其他类型的操作 , 是实现高吞吐量的关键 。
然而 , 3x3 卷积也存在一个致命弱点:感受野受限 。 这使得它在需要全局信息的生成任务中 , 天然弱于拥有全局感受野的 Transformer 。 之前的工作大多认为 , Transformer 中的自注意力机制是大型生成模型 Scaling Law 的关键 。
DiC 的作者们正是要挑战这一「常识」 。
DiC 的基本模块主要由两个 Conv3x3 组成
DiC 的进化之路:从平庸到卓越
研究者们并非简单地堆叠卷积层 。 他们通过一系列精巧的设计 , 一步步将一个平庸的卷积网络打造成了性能怪兽 。 这个过程清晰地展现在了论文的路线图(Roadmap)中:
架构选择:U-Net Hourglass 是关键
研究发现 , 对于纯卷积模型 , 传统的 U-Net 沙漏型架构比 Transformer 中流行的直筒形 Transformer 堆叠架构更有效 。 通过编码器中的下采样和解码器中的上采样 , 模型可以在更高层级用同样的 3x3 卷积核覆盖更广的原始图像区域 , 从而有效弥补了感受野不足的问题 。 在此基础上 , DiC 减少了跳连的频率 , 降低了 U-Net 频繁跳连带来的计算冗余 。
全方位的条件注入
优化为了让模型更精准地响应条件(如类别、文本等) , DiC 进行了一套精密的「三连击」优化 。 首先 , 它采用分阶段嵌入(Stage-Specific Embeddings) , 为 U-Net 不同层级的特征提供专属的、维度匹配的条件嵌入 。 其次 , 通过实验确定了最佳的注入位置 , 让条件信息在卷积块的中间层介入 , 以最高效地调制特征 。 最后 , DiC 引入了条件门控(Conditional Gating)机制* , 通过动态缩放特征图 , 实现了对生成过程更精细的控制 。 这套组合拳确保了条件信息被恰到好处地利用 , 极大地提升了模型的生成质量 。
激活函数替换
将常用的 SiLU 替换为 GELU , 带来了一定的效果提升 。
惊人的实验结果:性能与速度双丰收
超越 DiT , 性能更优
在同等计算量(FLOPs)和参数规模下 , DiC 在各个尺寸上都显著优于 DiT 。 以 XL 尺寸为例 , DiC-XL 的 FID 分数(越低越好)从 DiT-XL/2 的 20 降低到了 13 , IS 分数(越高越好)也大幅提升 , 生成图像的质量和多样性都更胜一筹 。
DiC 生成能力的超越已经足够亮眼 , 而速度的优势则更具颠覆性 。 由于纯卷积架构对硬件的高度友好 , DiC 的推理吞吐量(Throughput)远超同级别的 Transformer 模型 。 例如 , 在相同模型参数量和算力的情况下 , DiC-XL 的吞吐量达到了 313.7 , 是 DiT-XL/2(66.8)的近 5 倍!
Scaling Law 上的探索
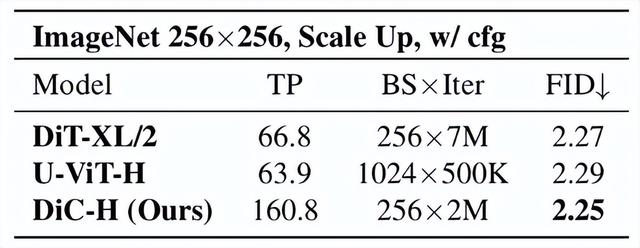
研究者们积极探索 DiC 图像生成能力的上限 , 发现模型收敛速度快 。 当不使用 cfg 时 , 在相同设定下 DiC 的收敛速度是 DiT 的十倍;在使用 cfg 时 , FID 可以达到 2.25 。
DiC 生成效果出众 , 输出图像十分逼真
大图上的探索
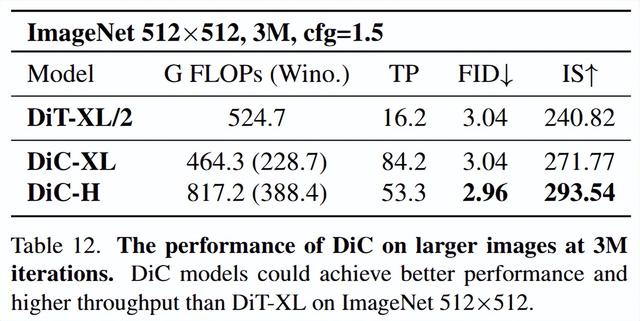
当生成图像尺寸扩大时 , Transformer 的二次方复杂度问题会急剧恶化 。 而 DiC 的线性复杂度使其优势更加突出 。 实验表明 , 在 512x512 分辨率下 , DiC-XL 模型可以用比 DiT-XL/2 更少的计算量 , 远超后者的速度 , 达到更好的生成效果 。
结论与展望
DiC 的出现 , 有力地挑战了「生成模型必须依赖自注意力」的固有观念 。 它向我们展示了 , 通过深入的理解和精巧的架构设计 , 简单、高效的卷积网络依然可以构建强大的生成模型 。 卷积 , 在视觉 AIGC 的广阔天地中仍然大有可为!
论文已被 CVPR2025 接收 , 更多内容 , 请参考原论文 。
推荐阅读












- 3000元价位笔记本:小新14、荣耀X14 Plus、无界14X斗战版哪个好?
- 变现难、市场小,视频播客真的是未来吗?
- 899元 华为路由X1 Pro陶瓷白开售:内置星闪网关、自研凌霄SoC
- 消息称苹果明年上半年将推出7款新品 包括iPhone 17e、iPad Air
- 角色动画的物理革命,PhysRig实现更真实、更自然的动画变形效果
- 13999元起!三星Galaxy Z Fold7正式发布:8.9mm、215g全球最轻
- 苹果将推出全新Vision Pro:搭载M4芯片、升级版神经网络引擎
- 三星Galaxy大小折叠新机发布:大的机身轻薄、小的边框窄到惊艳
- 二季度全球PC市场:联想、苹果成赢家?华为、小米没进前五
- 英特尔开始在代工、汽车和营销部门大规模裁员