
文章图片
文章图片
文章图片

金磊 发自 凹非寺
量子位 | 公众号 QbitAI
超大规模MoE模型(如DeepSeek) , 到底该怎么推理才能做到又快又稳 。
现在 , 这个问题似乎已经有了标准答案——
华为一个新项目 , 直接把推理超大规模MoE背后的架构、技术和代码 , 统统给开源了!
这个新开源项目名叫Omni-Infer , 整体来看 , 它对于企业用户来说是非常利好的 。
例如它可以给企业提供PD分离部署方案 , 针对QPM进行系统级优化 , 还会分享大规模商用过程中硬件使用的“方法论” 。
而且对于开发者和开源社区 , 华为这“一呼”也是起到了“百应”的效果 。
北京智源研究院副院长兼总工程师林咏华表示:
北京智源研究院一直以来致力于人工智能开源生态建设 , 很高兴看到Omni-infer项目开源 , 智源团队打造的面向多芯片的FlagScale框架也在第一时间接入了Omni-infer , 期待后续有更多生态合作 。
GitHub地址:https://github.com/FlagOpen/FlagScale/pull/630
上海人工智能实验室系统平台中心负责人王辉认为:
DeeLlink致力于打造最开放兼容的人工智能计算体系 , 十分期待能与Omni-infer项目携手 , 繁荣自主软硬件协同开源社区、拓展生态版图 。
以及OpenI启智社区运营中心主任余跃也给出了响应:
OpenI启智社区坚持创新为本 , 面向未来与Omni-Infer项目一起打造基于算力网的开源共创协作生态 。
据了解 , 华为Omni-Infer社区的定位是 “加速套件+最佳实践” , 未来提供开箱即用能力 , 支持昇腾推理集群快速部署 。
而对于这次Omni-Infer的开源 , 其实是华为兑现了一个月前在发布重磅技术报告之际所做出的承诺 。
那么接下来 , 我们就来一同深入了解一下华为的Omni-Infer 。
一个框架和一个套件从整体来看 , Omni-Infer可以拆成两大块来看:一个是推理框架 , 一个是推理加速套件 。
从框架角度来看 , Omni-Infer能和业界主流的开源大模型推理框架(如vLLM)完美兼容 , 就像不同品牌的零件可以组装在同一台机器上 。
并且据了解 , 它的功能还将不断扩展 , 会持续为昇腾硬件平台上的大模型推理提供更强大的支持(例如SGLang等主流开源LLM推理框架) 。
值得一提的是 , Omni-Infer是与vLLM/SGLang等等这些主流大模型推理开源框架是解耦的 , 独立安装 。
这就意味着用户只需维护vLLM等的主版本即可 , 大大降低了软件版本维护的成本 。
至于Omni-Infer的加速套件 , 若是用较为形象的比喻 , 它的“打开方式”是这样的:
企业级的 “调度员”:它有一套智能的调度系统 , 就像交通警察指挥车辆一样 , 能合理安排任务(xPyD调度) 。 而且支持大规模分布式部署 , 就像多个交通岗亭协同工作 , 不管任务量多大 , 都能保证最低的延迟 , 让响应更及时 。 精准的 “负载平衡器”:对于不同长度的任务序列 , 它在预填充和解码这两个关键阶段都做了优化 。 比如 , 就像快递分拣中心针对不同大小的包裹采用不同的分拣策略 , 让整个处理过程的吞吐量达到最大 , 同时还能保持低延迟 。 MoE模型的 “专属搭档”:它对混合专家(MoE)模型特别友好 , 支持EP144/EP288等多种配置 。 可以想象成一个大型的 “专家团队” , 每个专家负责不同的任务 , 它能让这些专家高效协作 。 智能的 “资源分配者”:具备分层非均匀冗余和近实时动态专家放置功能 。 就像在一个大型工厂里 , 根据实时的生产需求 , 动态调整各个生产线的工人分配 , 让资源得到最充分的利用 。 注意力机制的 “强化器”:专门为LLM、MLLM和MoE等模型优化了注意力机制 。 这就好比给模型的 “注意力” 装上了 “放大镜” , 让它在处理信息时更聚焦、更高效 , 提升了模型的性能和可扩展性 。 如何“食用”?在聊完Omni-Infer的特点之后 , 我们继续来看下该如何去体验 。
首先对于它的使用环境是有一定的要求:
硬件:目前仅支持CloudMatrix384推理卡 操作系统:Linux Python:=3.9= 3.11其次在安装方式上 , 目前仅支持通过Docker镜像方式进行安装:
dockerpull swr.cn-southwest-2.myhuaweicloud.com/omni-ai/omniinfer:202506272026 【华为又开源了个大的:超大规模MoE推理秘籍】这个镜像已预先集成所需的CANN及Torch-NPU依赖包 , 同时内置可直接运行的Omni-Infer与vLLM工具包 , 开箱即可使用 。
可以使用下面这个命令检查是否可用:
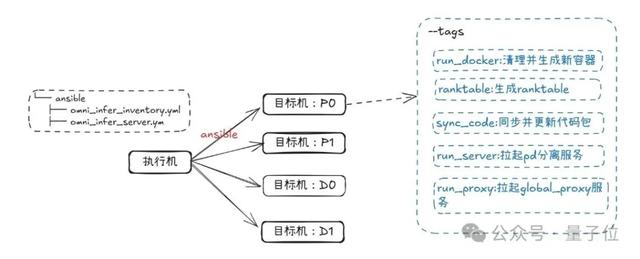
piplist | grep omni_infer以PD分离自动化部署(4机2P1D)为例 , 它的部署框架如下所示:
再接下来 , 只需文档教程 , 仅少量代码和步骤 , 即可完成安装和部署:
整体来看 , 此次华为面向超大规模MoE开源的项目 , 是做到了简单几步就可以让AI推理这事变得又快又稳 。
极致开源Omni-Infer除了将此前《华为昇腾服务器 DeepSeek V3/R1 推理部署最佳实践》技术报告中的关键技术开源出来之外 , 也同步进行了更加专业的开源社区建设 。
首先 , 在独立的社区仓库中 , 将社区治理、社区会议、社区活动、生态合作、代码规范、设计文档等社区信息全部开放出来 , 让开发者能够最直接深入的参与到社区发展中 。
其次 , 参照业界主流大型开源社区的最佳实践 , 采用开放的社区治理机制 , 通过项目管理委员会(Project Management Committee)和特别兴趣小组(Special Interest Group)两级机制 , 提供公正透明的讨论与决策机制 。
再次 , 针对业界同类开源项目大多存在的“一头热”的“被动适配”生态合作模式问题 , Omni-Infer社区则采取了“主动适配”的社区构筑路径 , 尤其是主动拥抱国内正在逐步成长的人工智能开源项目 , 让生态真正实现多方共赢 。
作为长期与业界几大主流开源基金会(Linux基金会、OpenInfra基金会、Apache基金会等)保持紧密合作关系的社区团队 , Omni-infer刚开源的首个活动就将参与OpenInfra基金会在苏州的Meetup , 感兴趣的同学可以到现场交流 , 也顺路可参加有特色的全球性开源社区的生日活动 。
最后 , 所有相关的地址放下面了 , 感兴趣的小伙伴可自取哦~
技术报告及可分析代码包:https://gitcode.com/ascend-tribe/ascend-inference-cluster
源代码开发协作:https://gitee.com/omniai/omniinfer
社区治理、运作等内容:https://gitee.com/omniai/community
【其他托管平台】
Github:https://github.com/omni-ai-npu/omni-infer
OpenI启智社区:https://git.openi.org.cn/omni-ai/omni-infer
GitLink确实平台:https://gitlink.org.cn/omni-ai/omniinfer
— 完 —
量子位 QbitAI · 头条号
关注我们 , 第一时间获知前沿科技动态
推荐阅读











- 2025年最耐用的4款千元机,机身耐摔又防水,最低仅1019元
- 手机声音小,是这个开关没打开,打开后,声音清晰又洪亮
- 华为流程体系拆解系列:L1-L6分层拆解逻辑
- 华为入选《时代周刊》全球100影响力企业:自主研发支撑品牌韧性
- 华为Pura80 Ultra变身专业摄像机!铁头3299元摄影套装都有啥?
- 华为官方合作出品!Pura80Ultra喜提摄影套装,价格有点小贵
- 华为小折叠杀入5K档:Pocket 2优享版性能仅缩水5%?
- 华为放弃高利润!顶级拍照手机突降3650元,16G+512G+双卫星通信
- 华为Pura XT浮出水面:新专利+新形态,国产友商面临挑战
- 华为宣布重要决定:正式开源!