
文章图片

文章图片
文章图片

文章图片

文章图片

文章图片
阿里妹导读
iLogtail 作为开源可观测数据采集器 , 对 Kubernetes 环境下日志采集有着非常好的支持 , 本文跟随 iLogtail 的脚步 , 了解容器运行时与 K8s 下日志数据采集原理 。
如今 , Kubernetes在业界几乎已经成为了容器管理的标准 。 在 Kubernetes 架构中 , 容器运行时(如Docker、containerd等)充当了基础层的角色 , 负责容器的创建、执行和管理 。 由于Kubernetes的设计是高度模块化的 , 它支持多种容器运行时 , 这给开发者带来了灵活性 。 开发者可以根据不同的需求选择最合适的运行时 , 甚至在同一个集群内使用多种运行时 , 这是Kubernetes生态的一个显著优势 。
iLogtail 作为开源可观测数据采集器 , 对 Kubernetes 环境下日志采集有着非常好的支持 , 下面就跟随 iLogtail 的脚步 , 了解容器运行时与 K8s 下日志数据采集原理 。
K8s 与容器运行时简介
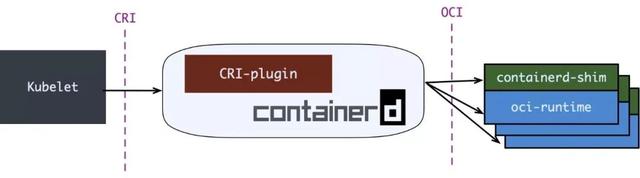
正如前面所说 , Kubernetes的设计是高度模块化的 , 那么模块化的基础就是统一的接口或者标准 。 容器运行时这个概念比较广泛 , 我们平常所听到的 Docker、Containerd、Runc、Kata 等都可以叫做运行时 , 但是他们又明显地处于不同层次上 , 比如 Containerd 会依赖 Runc 去真正地拉起容器 。 因此在这里做了一些概念划分 , 在Kubernetes 架构下 , 像Containerd 这种跟 CRI 进行交互的 , 叫做高级容器运行时;像 RunC 这种跟 OCI 交互的 , 叫做基础容器运行时 。
接下来我们先了解一下 CRI 和 OCI 的概念 。
CRI 与高级容器运行时
CRI(Container Runtime Inteface 容器运行时接口)本质上就是 Kubernetes 定义的一组与容器运行时进行交互的接口 , 所以只要实现了这套接口的容器运行时都可以对接到 Kubernetes 平台上来 。
Kubelet 通过 gRPC 框架与容器运行时或 shim 进行通信 , 其中 kubelet 作为客户端 , CRI shim(也可能是容器运行时本身)作为服务器 。 通过 CRI 的接口定义可以看到 , 大概分了两套接口:
1.针对 container 和 sandbox 的接口;
2.针对镜像操作的接口;
比方说我们通过 kubectl 命令来运行一个 Pod , 那么 Kubelet 就会通过 CRI 执行以下操作:
- 首先调用 RunPodSandbox 接口来创建一个 Pod 容器 , Pod 容器是用来持有容器的相关资源的 , 比如说网络空间、PID 空间、进程空间等资源;
- 然后调用 CreatContainer 接口在 Pod 容器的空间创建业务容器;
- 再调用 StartContainer 接口启动容器 , 相对应的销毁容器的接口为 StopContainer 与 RemoveContainer 。
在 Kubernetes 的早期 , 也只支持一个容器运行时 , 那就是 Docker 。 Kubernetes 推出 CRI 这套标准的时候 , 比如 Docker 本身并没有实现 CRI 接口 , 于是就有了 shim(垫片) ,一个 shim 的职责就是作为适配器将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上 , 其中 dockershim 就是 Kubernetes 对接 Docker 到 CRI 接口上的一个垫片实现 。
当 Kubelet 想要使用 Docker 运行时创建一个容器时 , 它需要以下几个步骤:
- Kubelet 通过 CRI 接口(gRPC)调用 dockershim , 请求创建一个容器 , CRI(容器运行时接口 , Container Runtime Interface) 。 在这一步中, Kubelet 可以视作一个简单的 CRI Client , 而 dockershim 就是接收请求的 Server 。
- dockershim 收到请求后 , 它会转化成 Docker Daemon 的请求 , 发到 Docker Daemon 上 , 并请求创建一个容器 。
- Docker Daemon 在 1.12 版本中将针对容器的操作移到另一个守护进程 containerd 中了 。 因此 Docker Daemon 请求 containerd 创建一个容器 。
- containerd 收到请求后 , 创建一个 containerd-shim 的进程 , 让 containerd-shim 去操作容器 。 containerd-shim 在这一步需要调用 Runc 这个命令行工具 , 来真正启动容器 。
- Runc 启动完容器后 , 它会直接退出 , containerd-shim 则会成为容器进程的父进程 , 负责收集容器进程的状态 , 上报给 containerd 。
Docker Daemon 和 Docker-shim 仿佛是可以忽略的 。
因此在Kubernetes 提出 CRI 之后 , Containerd 迅速完成了适配 。 在 Containerd v1.0 中 , 对 CRI 的适配通过一个单独的进程CRI-containerd来完成:
Containerd v1.1 中做的又更漂亮一点 , 砍掉 CRI-containerd 进程 , 直接把适配逻辑作为插件放进 containerd 主进程中:
CRI-OKubernetes 的主流运行时经历了从 Docker 到 Containerd 的转变 , 流程变得愈加简化 。 此外 , 还有一个比 Containerd 更为纯粹且专注的 Kubernetes 运行时解决方案—CRI-O , 它专为 Kubernetes 设计 , 并且兼容 CRI 和 OCI , 提供了更为简单的运行时体验 。
Containerd 是一个更通用的容器运行时 , 旨在提供一个高效的容器管理系统 。 它支持构建、运行和存储容器镜像 , 适用于各种编排工具 , 如 Kubernetes 和 Docker Swarm 。 Containerd 提供了丰富的 API 和插件机制 , 使其能够与多种环境和体系结构兼容 。
相对而言 , CRI-O 是专为 Kubernetes 设计的轻量级容器运行时 。 它遵循 Kubernetes 的 CRI(容器运行时接口)标准 , 专注于提供与 Kubernetes 生态系统的无缝集成 。 CRI-O 旨在简化对 Kubernetes 的容器管理 , 去掉了不必要的功能 , 力求在安全性、性能和资源占用上做到极致 , 减少了额外的复杂性 。
OCI 与基础容器运行时
开放容器标准(Open Container Initiative , OCI)是一个由多个技术公司、开发者和社区成员组成的行业合作项目 , 旨在为容器技术建立开放标准 。 OCI 于 2015 年成立 , 目的是为了推动容器生态系统的发展 , 减少不同容器运行时及映像格式之间的不兼容性 。
OCI 目前包含三个规范:
- 运行时规范 (runtime-spec):定义了如何运行容器 , 包括配置、生命周期和沙箱环境 。 它提供了一种标准的方法 , 使得容器能够在任何遵循该标准的运行时中被启动 。 简单来说 , 它规定的就是“容器”要能够执行“create”“start”“stop”“delete”这些命令 , 并且行为要规范 。
- 镜像规范 (image-spec) :规定了容器映像的格式和内容结构 , 确保镜像可以在不同的容器运行时之间顺利传输和使用 。
- 分发规范 (distribution-spec):是关于如何在不同的容器注册中心之间分发和获取容器映像的标准 。
RuncRunc的前身实际上是Docker的libcontainer项目演化而来 。 Runc实际上就是libcontainer配上了一个轻型的客户端 。
Runc是一个轻量级的容器运行时 , 用于根据OCI(Open Container Initiative)标准运行容器 。 它是最基础的容器运行时解决方案 , 可以在没有额外服务管理的情况下启动和运行容器 。 Docker和其他较高级的容器管理工具在内部使用Runc来实际启动和运行容器 。 Runc的目标是提供一个通用的容器运行时 , 侧重于简单、可移植和可扩展 。
- 隔离机制:它直接在宿主机上运行容器进程 , 并使用Linux的namespace和cgroups等内核特性来提供隔离和资源限制 。
- 安全性:虽然 Runc 通过 Linux 的安全特性(如 SELinux、AppArmor、seccomp等)提供基本的安全保障 , 但它仍然共享同一内核 , 与其他在同一宿主机上运行的容器相比 , 隔离性并不是最强的 。 对于需要强隔离的场景 , 可能需要其他解决方案 。
- 性能:Runc 为容器提供了接近原生Linux性能 , 启动速度快 , 资源开销小 , 适合大规模部署和微服务架构 。
- 使用场景:广泛用于开发、测试和生产环境 , 是Docker和许多Kubernetes部署的默认容器运行时 。 ?
1.内核漏洞:所有容器共享同一内核 , 因此如果内核出现漏洞 , 攻击者可以利用这些漏洞从一个容器突破到宿主机或其他容器 。 这使得容器之间的隔离不如完全虚拟化的方式安全 。
2.系统调用滥用:容器内的进程可以通过系统调用与内核交互 。 一些系统调用可能被恶意容器滥用以获取更高的权限或访问宿主机的资源 。
3.特权容器:如果某个容器被配置为特权容器 , 它将拥有更高的权限 , 可能直接访问宿主机的硬件或敏感资源 , 从而导致安全风险 。
4.配置错误:容器的配置不当可能导致安全漏洞 , 如未正确配置的网络或存储 , 可能使容器之间能够互相访问 , 从而影响隔离性 。 ?
Kata/RunD正如前面所说的 ,Runc 在安全方面的各种问题 , 因此需要一种更加安全的运行时 。
Kata安全容器和普通容器相比有2个主要的区别:
1.容器运行在虚拟机里;
2.镜像要从宿主机上传递给虚拟机;
- Shim-v2 会为 Pod 启动一个虚拟机作为 PodSandbox提供隔离性 , 其中运行着一个 Linux 内核 , 通常这个 Linux 内核是一个裁剪过的内核 , 不会支持没有必要的设备 。
- 这里用的虚拟机可以是 Qemu 或是 Firecracker , 它只是支撑容器应用运行的基础设施没有完整操作系统 。
K8s 下容器日志数据采集难点
在 Kubernetes(K8s)环境下 , 容器日志数据采集面临着多重挑战:
1.生命周期短容器的短暂性和高度动态特性使得它们的生命周期极其短暂 , 这意味着许多容器可能在运行期间生成重要的日志信息 , 但一旦容器被销毁 , 这些信息就会随之消失 。 日志的瞬时性给日志采集带来了极大的挑战 。
2.分布式架构容器通常部署在多个节点上 , 这种分布式架构导致日志数据存储在不同的位置 。 数据的分散性不仅增加了管理的复杂性 , 而且可能导致实时数据采集和分析的困难 。
3.存储方式多样容器的存储方式各异 , 包括卷、挂载等 。 这些存储方式的多样性使得日志的写入、读取和管理变得更加复杂 。
4.数据与容器元信息关联容器日志作为可观测数据 , 必须与容器的元信息(如容器 ID、名称、标签等)进行精准关联 , 以便于后续的查询与分析 , 有效地匹配数据与容器信息有助于快速定位问题源头 。 然而 , 由于容器的频繁创建和销毁 , 以及其动态变化的特性 , 在数据采集时及时、准确地建立这种关联 , 依然是一大挑战 。 ?
开源采集器容器日志采集方案
Filebeat
容器标准输出采集通过官方文档[1
可以看到 , Filebeat 推荐是以 daemonset 的方式部署在 K8s 集群中的 , 然后这里需要把节点宿主机上的:/var/log 和/var/lib/docker/containers挂载进filebeat的pod中 。 这个采集原理跟前面运行时就有关系了 。
当Docker 作为 K8s 容器运行时 , 容器日志的落盘将由 docker 来完成 , 保存在:
/var/lib/docker/containers/ 目录下 。 Kubelet 会在 /var/log/pods 和 /var/log/containers 下建立软链接 , 指向 /var/lib/docker/containers/ 目录下的容器日志文件 。
当Containerd 作为 k8s 容器运行时 ,容器日志的落盘由 Kubelet 来完成 , 保存至 /var/log/pods/ 目录下 , 同时在 /var/log/containers 目录下创建软链接 , 指向日志文件 。
所以 , 总结下来:
1./var/lib/docker/containers/ : Docker 日志落盘路径 , 文件路径格式/var/lib/docker/containers/${container_id/${container_id-json.log
2./var/log/containers/ : 一般都是软连接 , 文件路径格式/var/log/containers/${pod_name_${namespace_${container_name-${container_id.log
3./var/log/pods/ :kubelet 日志落盘路径 , 文件路径格式/var/log/pods/${namespace_${pod_name_${pod_uid
/${container name/0.log
所以一般采集标准输出文件 , 都是采集/var/log/containers 路径 , 因为这个路径下有完整的所有容器的标准输出文件 。
从官方文档[1
, 可以看到 ,Filebeat 支持在 K8s 环境自动发现容器并采集容器数据 。
K8s 配置样例:
filebeat.autodiscover:providers:- type: kubernetestemplates:- condition:equals:kubernetes.namespace: kube-systemconfig:- type: containerpaths:- /var/log/containers/*-${data.kubernetes.container.id.logexclude_lines: [\"^\\\\s+[\\\\-`('.|_
\"
# drop asciiart lines从源码[2中我们可以看到 , Filebeat 在 Kubernetes 场景下 , 采用了向 API Server 进行 List-Watch 的方式来处理与集群相关的各种资源 , 例如 Pod、Namespace、Node 等 。 首先 , Filebeat 会向 API Server 发送请求以获取当前所有相关资源的列表 , 并持续监控这些资源的变化 。 当有新的资源被创建、更新或删除时 , API Server 会通过事件通知的方式将变更信息推送给 Filebeat 。
在获取到这些资源后 , Filebeat 会将它们存储在本地缓存中 , 以便后续的访问和处理 。 通过这种List-Watch 机制 , Filebeat 能够实时获取资源的状态 , 确保信息的时效性和准确性 。 接下来 , Filebeat 会进行条件过滤 , 数据上报的时候 , 还可以进行数据的富化处理 , 比如添加上下文信息、标签或其他的容器元信息数据 , 从而使得最终的日志更加丰富和有意义 。 ?
容器内自定义文件采集配置目前 , 针对容器内自定义文件采集配置 , Filebeat 提供 sidecar 模式的部署 。 比如如下样例 , Filebeat 作为一个 sidecar container , 跟业务容器部署在同一个 Pod 内 , 同时 , 业务容器要采集的日志文件路径需要通过数据卷挂载的方式共享给 Filebeat , 这样才能完成容器内自定义文件采集 。
apiVersion: apps/v1kind: Deploymentmetadata:name: app-log-logfilespec:replicas: 3selector:matchLabels:project: microserviceapp: nginx-logfiletemplate:metadata:labels:project: microserviceapp: nginx-logfilespec:containers:# 应用容器- name: nginximage: lizhenliang/nginx-php# 将数据卷挂载到日志目录volumeMounts:- name: nginx-logsmountPath: /usr/local/nginx/logs# 日志采集器容器- name: filebeatimage: elastic/filebeat:7.10.1args: [\"-c\" \"/etc/filebeat.yml\"\"-e\"
resources:requests:cpu: 100mmemory: 100Milimits:memory: 500MisecurityContext:runAsUser: 0volumeMounts:# 挂载filebeat配置文件- name: filebeat-configmountPath: /etc/filebeat.ymlsubPath: filebeat.yml# 将数据卷挂载到日志目录- name: nginx-logsmountPath: /usr/local/nginx/logs# 数据卷共享日志目录volumes:- name: nginx-logsemptyDir: {- name: filebeat-configconfigMap:name: filebeat-nginx-configSidecar 模式虽然能够采集到容器内的日志文件 , 但是它也有一些劣势:1.资源占用提升:一个 Pod 就要部署一个采集器 , CPU、内存等资源占用势必增加 。
2.无法跟容器元信息关联:Sidecar 模式采集文件就跟主机上普通文件采集类似 , 很难跟容器元信息关联上 。
聪明的社区用户提出了一个创新性的方案[3
不直接使用 sidecar 模式来部署 filebeat 。 首先 , 引入一个轻量级的 sidecar 容器 , 主容器在运行时将日志文件共享给这个 sidecar 容器 。 接下来 , 在 sidecar 容器中 , 仅需运行简单的 tail 命令 , 将主容器输出的日志文件转换成标准输出的方式 , 然后就可以通过 filebeat 的 damonset 方式进行容器标准输出的采集 。 ?
apiVersion: v1kind: Podmetadata:name: counterspec:containers:- name: countimage: busyboxargs:- /bin/sh- -c- >i=0;while true;doecho \"$i: $(date)\" >> /var/log/1.log;echo \"$(date) INFO $i\" >> /var/log/2.log;i=$((i+1));sleep 1;donevolumeMounts:- name: varlogmountPath: /var/log- name: count-log-1image: busyboxargs: [/bin/sh -c 'tail -n+1 -F /var/log/1.log'
volumeMounts:- name: varlogmountPath: /var/log- name: count-log-2image: busyboxargs: [/bin/sh -c 'tail -n+1 -F /var/log/2.log'
volumeMounts:- name: varlogmountPath: /var/logvolumes:- name: varlogemptyDir: {Fluent bit
容器标准输出采集从 Fluent Bit 的官方文档[4
可以看到 , Fluent Bit 也是推荐使用 Daemonset 的部署模式部署到每一个节点上 , 然后 , 可以支持如下信息富化:
- Pod Name
- Pod ID
- Container Name
- Container ID
- Labels
- Annotations
K8s 日志采集配置样例[5
:
input-kubernetes.conf: |[INPUT
NametailTagkube.*Path/var/log/containers/*.logParserdockerDB/var/log/flb_kube.dbMem_Buf_Limit5MBSkip_Long_LinesOnRefresh_Interval10[FILTER
NamekubernetesMatchkube.*Kube_URLhttps://kubernetes.default.svc:443Kube_CA_File/var/run/secrets/kubernetes.io/serviceaccount/ca.crtKube_Token_File/var/run/secrets/kubernetes.io/serviceaccount/tokenKube_Tag_Prefixkube.var.log.containers.Merge_LogOnMerge_Log_Keylog_processedK8S-Logging.ParserOn在 INPUT 配置段中 , tail 插件将监控路径 /var/log/containers/ 路径以 .log 结尾的所有文件 。 对于每个文件 , 它将读取每一行日志记录并应用 docker 解析器 。 然后 , 日志记录将被附加标签并发送到下一步 。从源代码[6
可以看到 , Fluent bit 容器元信息富化与 Filebeat 不太一样 , Filebeat 采取的是 List-Watch api server 的方式 , 而 Fluent bit 则是从文件名中解析得到 namespace 和 pod name , 然后向api server 请求单个 pod 的元信息 。
如果想要过滤掉某个 pod 的日志 , 那么 Fluent bit 还支持使用注解的方式 , 请求将指定日志排除 , 如下样例就是使用fluentbit.io/exclude 这个注解 , 将该 pod 的日志排除掉 。
【跟着iLogtail学习容器运行时与K8s下日志采集方案】
apiVersion: v1kind: Podmetadata:name: apache-logslabels:app: apache-logsannotations:fluentbit.io/exclude: \"true\"spec:containers:- name: apacheimage: edsiper/apache_logs容器内自定义文件采集配置对于容器内自定义文件的采集 , Fluent bit 同样采取的是 sidecar 的部署模式 。 ?小结
K8s 场景 , 开源采集器一般都支持 Daemonset 和 Sidecar 两种部署模式:
Daemonset 部署模式:一般都是用来采集 K8s 场景下容器标准输出日志 , 容器元信息获取都是通过与 K8s 的 api server 交互获取 , 但是实现细节上有所不同 , Filebeat 采用的是 List-Watch 机器 , 获取全量的资源信息 , FluentBit 则是按需获取对应 Pod 信息 。
Sidercar 部署模式:一般都是用来采集容器内自定义日志文件 , 没有办法获取容器元信息数据 , 难以富化日志字段 。
iLogtail 容器日志采集方案
Daemonset 模式
部署说明iLogtail Daemonset 部署模版可以参考文档?[7
其中比较关键的配置如下:
volumeMounts:- mountPath: /var/run # for container runtime socketname: run- mountPath: /logtail_host # for log access on the nodemountPropagation: HostToContainername: rootreadOnly: truevolumes:- hostPath:path: /var/runtype: Directoryname: run- hostPath:path: /type: Directoryname: root- 一个是将节点的/var/run 目录挂载待 iLogtail-ds 里面 , 主要作用是让 iLogtail-ds 可以访问到容器运行时的 sock 文件 , 比如
- Docker:/run/docker.sock 。
- Containerd:/run/containerd/containerd.sock 。
- 还有一个是把节点根目录挂载到 iLogtail-ds 里面 , 主要作用就是让 iLogtail-ds 可以访问节点上的路径 , 从而实现标准输出日志和容器内自定义日志文件的采集 。 ?
1.灵活的采集配置
iLogtail 提供强大的配置选项 , 使用户能够根据不同的 Pod 和 Container 条件进行精确的筛选 。 用户可以根据标签、命名空间、环境变量等多种条件灵活定义目标容器 , 从而确保所需日志的高效采集与处理 。
2.容器元信息富化
为了提升日志数据的价值 , iLogtail 支持对容器的元信息进行富化 。 这意味着用户可以自动获取并附加如 Pod 名称、命名空间、节点名称、容器状态等关键信息 , 使得后续的数据分析和监控变得更加直观和高效 。
3.支持标准输出和容器内自定义文件采集
iLogtail 支持采集采集标准输出日志和容器内任意文件日志采集
4.全量挂载模式支持
iLogtail 支持多种挂载模式 , 以适应业务不同的部署需求 。 无论是使用 hostPath、emptyDir 还是其他持久化存储的挂载方式 , 都可以支持 , 确保日志采集的稳定性与灵活性 。
5.主机文件采集能力
除了容器内的日志采集 , iLogtail 还支持直接在主机上进行文件的采集 。 这一功能使得用户能够灵活地从主机文件系统中提取重要的日志数据 , 满足不同场景下的日志收集需求 , 并提供全面的日志分析能力 。
容器元信息获取原理介绍在容器元信息获取方面 , iLogtail 的设计思路与开源 API server 请请求的解决方案有所不同 。 它采用了直接与容器运行时进行交互的方式 , 以确保高效、可靠地获取所需的元数据 。 目前 , iLogtail 支持多种主流的容器运行时 , 具体包括:
使用 Docker Client , 支持 Docker 运行时iLogtail 利用 Docker Client 与 Docker Daemon 进行通信 , 直接获取容器的元信息 。 通过这种方式 , 可以实现对容器的深入监控和管理 。 主要使用到的接口包括:
- ?ContainerList:获取当前运行容器的列表 , 这使得 iLogtail 能够快速了解当前节点上有哪些容器在运行 。
- ?ContainerInspect:提供每个容器的详细信息 , 包括配置、状态等关键信息 。
- ?Events:实时监听容器变化事件 , 允许动态跟踪容器的生命周期 , 及时更新相关处理逻辑 。
- LogPath:这是容器标准输出日志文件在宿主机上的存放路径 , 方便用户进行日志收集和分析 。
- GraphDriver.Data:提供容器 rootfs 在节点宿主机上的路径 , 关键于了解容器文件系统的存储方式 , 有助于进行故障诊断和性能优化 。
[{\"Id\": \"1eb334fb59429d77dbfc9ab50f17d72558099532dd33486efd23e817dc3a1fe8\"\"Created\": \"2024-01-15T06:58:13.23781656Z\"\"Path\": \"nginx\"\"Args\": [
\"State\": {\"Image\": \"sha256:261c66bffbc8e04810eb3c292a1c666ee92a11fb874f4585471d70635afafc90\"\"ResolvConfPath\": \"/var/lib/docker/containers/8b187cf41801560981deaf0b4389516ec532a58508899895bcb88aa683feb898/resolv.conf\"\"HostnamePath\": \"/var/lib/docker/containers/8b187cf41801560981deaf0b4389516ec532a58508899895bcb88aa683feb898/hostname\"\"HostsPath\": \"/var/lib/kubelet/pods/5fca5fc9-55fe-40cd-a2b2-9abe81796486/etc-hosts\"// 标准输出日志文件路径\"LogPath\": \"/var/lib/docker/containers/1eb334fb59429d77dbfc9ab50f17d72558099532dd33486efd23e817dc3a1fe8/1eb334fb59429d77dbfc9ab50f17d72558099532dd33486efd23e817dc3a1fe8-json.log\"\"Name\": \"/k8s_nginx-1215_nginx-1215-b749b6c4f-q4pzb_default_5fca5fc9-55fe-40cd-a2b2-9abe81796486_0\"\"RestartCount\": 0\"Driver\": \"overlay2\"\"Platform\": \"linux\"\"MountLabel\": \"\"\"ProcessLabel\": \"\"\"AppArmorProfile\": \"\"\"ExecIDs\": null\"HostConfig\": {\"LogConfig\": {// 日志配置\"Type\": \"json-file\"\"Config\": {\"max-file\": \"10\"\"max-size\": \"100m\"\"GraphDriver\": {// rootfs路径\"Data\": {\"LowerDir\": \"/var/lib/docker/overlay2/1e8847504f60ee1e159aa12f09fe9c92e4f5165ff01991b29fd1a0c36d2aec9e-init/diff:/var/lib/docker/overlay2/b1fc28e304c04200359f045995ad78cdcd418c13ce058255f6c85b4d5bff2000/diff:/var/lib/docker/overlay2/ec56a2a3384cc1c0753295bbb1dcc268db23bc13077622e27f7c7d16663f8c7a/diff:/var/lib/docker/overlay2/f2c8d0f32b19d1725a8fb377230b8c18f3ad3b794b77fbfcf3b259fb8e502fd0/diff:/var/lib/docker/overlay2/2b578df4e8cd6d7ce189ccd413096f5a54218a4f90ca34e3ca16732401301833/diff\"\"MergedDir\": \"/var/lib/docker/overlay2/1e8847504f60ee1e159aa12f09fe9c92e4f5165ff01991b29fd1a0c36d2aec9e/merged\"\"UpperDir\": \"/var/lib/docker/overlay2/1e8847504f60ee1e159aa12f09fe9c92e4f5165ff01991b29fd1a0c36d2aec9e/diff\"\"WorkDir\": \"/var/lib/docker/overlay2/1e8847504f60ee1e159aa12f09fe9c92e4f5165ff01991b29fd1a0c36d2aec9e/work\"// rootfs类型\"Name\": \"overlay2\"// 挂载信息 , 如果Pod有配置卷挂载等 , 这里会有体现\"Mounts\": [
\"Config\": {\"NetworkSettings\": {
使用 CRI , 支持 Containerd 和 CRI-O 运行时通过 CRI(Container Runtime Interface) , iLogtail 充分支持在 containerd 和 cri-o 运行时环境下的多种应用场景 。 无论底层使用的是 runc 还是 Kata Containers , iLogtail 都能够高效地采集和获取容器的元信息 。 这意味着 , 无论容器运行在何种环境下 , iLogtail 都能保证准确、统一的日志数据采集 , 帮助用户实时监控和分析日志数据 。 如下就是一个 containerd 的运行时通过 CRI 接口拿到的信息:{\"status\": {\"id\": \"7b46331103c28c3cd0198e22fa85f81e2fef50141e1074f67cfdad942c76ebea\"\"metadata\": {\"attempt\": 0\"name\": \"nginx\"\"state\": \"CONTAINER_RUNNING\"\"createdAt\": \"2024-03-12T14:54:48.225783056+08:00\"\"startedAt\": \"2024-03-12T14:54:48.329066862+08:00\"\"finishedAt\": \"1970-01-01T08:00:00+08:00\"\"exitCode\": 0\"image\": {\"image\": \"docker.io/library/nginx:latest\"\"imageRef\": \"docker.io/library/nginx@sha256:c26ae7472d624ba1fafd296e73cecc4f93f853088e6a9c13c0d52f6ca5865107\"\"reason\": \"\"\"message\": \"\"\"labels\": {\"io.kubernetes.container.name\": \"nginx\"\"io.kubernetes.pod.name\": \"nginx-778b4fd69-p4xf2\"\"io.kubernetes.pod.namespace\": \"default\"\"io.kubernetes.pod.uid\": \"9bd59318-b2ba-4357-8faa-6906d7c827ba\"\"annotations\": {\"com.aliyun.ack.hashVersion\": \"v1.22.3-aliyun.1\"\"io.kubernetes.container.hash\": \"47cfd8d4\"\"io.kubernetes.container.restartCount\": \"0\"\"io.kubernetes.container.terminationMessagePath\": \"/dev/termination-log\"\"io.kubernetes.container.terminationMessagePolicy\": \"File\"\"io.kubernetes.pod.terminationGracePeriod\": \"30\"\"mounts\": [
// 标准输出日志文件路径\"logPath\": \"/var/log/pods/default_nginx-778b4fd69-p4xf2_9bd59318-b2ba-4357-8faa-6906d7c827ba/nginx/0.log\"\"info\": {\"sandboxID\": \"34560e346f5245926d1466b59b2f0906aae95b392277f55a52c5895cc3a65f6e\"\"pid\": 500599\"removing\": false\"snapshotKey\": \"7b46331103c28c3cd0198e22fa85f81e2fef50141e1074f67cfdad942c76ebea\"\"snapshotter\": \"overlayfs\"\"runtimeType\": \"io.containerd.runc.v2\"\"runtimeOptions\": {\"systemd_cgroup\": true\"config\": {\"metadata\": {\"name\": \"nginx\"\"image\": {\"image\": \"sha256:e4720093a3c1381245b53a5a51b417963b3c4472d3f47fc301930a4f3b17666a\"\"envs\": [
\"mounts\": [
\"labels\": {\"io.kubernetes.container.name\": \"nginx\"\"io.kubernetes.pod.name\": \"nginx-778b4fd69-p4xf2\"\"io.kubernetes.pod.namespace\": \"default\"\"io.kubernetes.pod.uid\": \"9bd59318-b2ba-4357-8faa-6906d7c827ba\"\"annotations\": {\"io.kubernetes.container.hash\": \"47cfd8d4\"\"io.kubernetes.container.restartCount\": \"0\"\"io.kubernetes.container.terminationMessagePath\": \"/dev/termination-log\"\"io.kubernetes.container.terminationMessagePolicy\": \"File\"\"io.kubernetes.pod.terminationGracePeriod\": \"30\"\"log_path\": \"nginx/0.log\"\"linux\": {// OCI配置\"runtimeSpec\": {不过 , CRI 所提供的容器元信息中 , 仅包含了容器标准输出日志文件在节点宿主机上的路径 , 而容器的 Rootfs 路径却无法直接获取 。 为了解决这一问题 , iLogtail 采取了以下两种有效方案[8:
1.文件路径搜索:通过对宿主机的文件系统进行智能搜索 , iLogtail 能够定位到容器的 Rootfs 路径 。 这种方法包括遍历宿主机上的文件目录 , 利用容器的唯一标识符(如容器 ID)进行关联查找 , 从而实现对容器文件系统的检索和获取 。 这种动态搜索机制 , 能够在一定程度上克服路径信息缺失带来的困扰 , 为后续的日志收集和监控提供支持 。
2.绕过 CRI , 直接与 containerd 进行交互:iLogtail 选择与 containerd 进行低层次的直接通讯 , 以获取更全面和准确的容器信息 。 通过这种方式 , iLogtail 能够绕过 CRI 的限制 , 获得容器的 Rootfs 路径和其他重要元数据 。 ?
SiderCar 模式
- 在Sidecar模式中 , 每个容器组(Pod)运行一个Logtail容器 , 用于采集当前容器组(Pod)所有容器(Containers)的日志 。 不同Pod的日志采集相互隔离 。
- 为了采集同一Pod中其它容器的日志文件 , 需要通过共享存储卷的方式来完成 , 即将同一份存储卷分别挂载到业务容器和Logtail容器 。
apiVersion: batch/v1kind: Jobmetadata:# 在这里添加 Job 元信息 , 比如 name 和 namespacename: ${job_namenamespace: ${namespacespec:template:spec:restartPolicy: Nevercontainers:# 业务容器- name: ${main_container_nameimage: ${main_container_imagecommand: [\"/bin/sh\" \"-c\"
args:- until [[ -f /tasksite/cornerstone
; do sleep 1; done;# 替换为业务容器的实际启动命令${container_start_cmd;retcode=$?;touch /tasksite/tombstone;exit $retcodevolumeMounts:# 业务容器的日志目录挂载到共享存储卷- name: ${shared_volume_namemountPath: ${dir_containing_your_files# 与 Logtail 容器交互的挂载点- mountPath: /tasksitename: tasksite# Logtail sidecar 容器- name: logtailimage: ${logtail_imagecommand: [\"/bin/sh\" \"-c\"
args:- /etc/init.d/ilogtaild start;sleep 10; # 等待 Logtail 配置下载完成touch /tasksite/cornerstone;until [[ -f /tasksite/tombstone
; do sleep 1; done;sleep 10; # 等待 Logtail 完成日志发送/etc/init.d/ilogtaild stop;livenessProbe:exec:command:- /etc/init.d/ilogtaild- statusinitialDelaySeconds: 30periodSeconds: 30env:# 设置时区 。 请根据kubernetes集群所在地域 , 配置时区 , 格式为\"地区/城市\" 。 如果是中国大陆 , 可以设置时区为Asia/Shanghai 。# 如果没有正确配置时区 , 可能导致原始日志与处理日志的时间标签不匹配 , 进而将日志数据归档到错误的时间点 。- name: TZvalue: \"${timezone\"- name: ALIYUN_LOGTAIL_USER_IDvalue: \"${your_aliyun_user_id\"- name: ALIYUN_LOGTAIL_USER_DEFINED_IDvalue: \"${your_machine_group_user_defined_id\"- name: ALIYUN_LOGTAIL_CONFIGvalue: \"/etc/ilogtail/conf/${your_region_config/ilogtail_config.json\"# 追加 Pod 环境信息作为日志标签- name: \"ALIYUN_LOG_ENV_TAGS\"value: \"_pod_name_|_pod_ip_|_namespace_|_node_name_|_node_ip_\"# 获取 Pod 和 Node 的信息- name: \"_pod_name_\"valueFrom:fieldRef:fieldPath: metadata.name- name: \"_pod_ip_\"valueFrom:fieldRef:fieldPath: status.podIP- name: \"_namespace_\"valueFrom:fieldRef:fieldPath: metadata.namespace- name: \"_node_name_\"valueFrom:fieldRef:fieldPath: spec.nodeName- name: \"_node_ip_\"valueFrom:fieldRef:fieldPath: status.hostIPvolumeMounts:# Logtail 容器的日志目录挂载到共享存储卷- name: ${shared_volume_namemountPath: ${dir_containing_your_files# 与业务容器交互的挂载点- mountPath: /tasksitename: tasksitevolumes:# 定义空的共享存储卷用于日志存储- name: ${shared_volume_nameemptyDir: {# 定义存储卷用于容器间通信- name: tasksiteemptyDir:medium: MemoryiLogtail 的 SideCar 模式用于日志数据采集 , 适用于多种特定场景 , 具体包括:1.单节点 Pod 数据量大:当一个节点上的 Pod 数据量异常庞大 , 远超出 Daemonset 的采集性能上限时 , 使用 SideCar 模式是非常推荐的 。 这种模式允许我们为 iLogtail 分配特定的资源 , 从而提升其日志采集的性能和稳定性 , 确保关键 Pod 的日志能够被及时高效地收集 , 为后续的监控和分析提供坚实的数据基础 。
2.Serverless 容器日志采集:在 Serverless 容器架构中 , 由于缺乏节点的概念 , 传统的 Daemonset 部署模式无法应用 。 此时 , SideCar 模式显得尤为重要 , 它能够有效地与无服务器架构结合 , 保证日志采集过程的灵活性和适应性 。
3.K8s + 安全容器运行时的日志采集:在使用安全容器运行时的 Kubernetes 环境中 , Daemonset 无法访问宿主机的其他容器的标准输出文件或日志 。 这时 , SideCar 模式便成为唯一可行的解决方案 。 通过在同一 Pod 内集成 iLogtail , 能够直观地获取和处理容器里的日志 , 确保即使在安全限制下 , 重要的日志数据依然能够被实时采集 。
SiderCar 模式 + 容器元信息文件
iLogtail 商业版与阿里云的容器团队紧密合作 , 推出了一种优化版本的 Sidecar 模式 。 具体而言 , 当容器团队启动 iLogtail Sidecar 容器时 , 会通过挂载的方式将业务容器的相关信息提供给 iLogtail 。 这一机制使得 iLogtail 在进行日志数据上报时 , 不仅能传递基本的日志内容 , 还能够附带业务容器的丰富字段信息 , 如容器名称、标签、环境变量等 。 这种深度集成的方式极大地增强了日志的上下文信息 , 提高了后续数据分析的效率 , 为用户提供了更为全面、直观的日志信息 。
目前该模式支持的容器场景有弹性容器 ECI [9
和容器计算服务 ACS[10
。
总结
在 Daemonset 模式下 , 与开源的 API server 请求的解决方案有显著的不同 , iLogtail 选择了与运行时进行直接交互 。 这种与运行时的交互方式带来了多个显著优势:
1.获取容器内的 rootfs 挂载信息:通过与运行时的交互 , iLogtail 能够深入挖掘容器内的文件系统信息 , 从而成功采集节点上 Pod 内自定义日志文件 。 这一能力是通过 API server 交互无法实现的 。
2.实时获取容器元信息:与运行时的直接交互方式使得 iLogtail 能够更快速地获取节点上正在运行的容器的元数据信息 , 这种实时性对日志监控的实时性至关重要 。
3.减轻 API Server 压力:Daemonset 通过 API Server 进行交互时 , 往往会对 API server 造成显著的压力 , 尤其是在大规模集群中 。 iLogtail 的设计减少了这种依赖 , 从而使 API Server 能够更专注于处理其他重要的请求 , 提升整体系统的稳定性和响应能力 。
4.兼容非 K8s 场景:iLogtail 的设计不仅限于 Kubernetes 环境 , 也兼顾到纯 Docker 等其他容器运行环境 。 这种灵活性使得 iLogtail 能够在更广泛的场景中应用 , 不论是在微服务架构下的 Kubernetes 部署 , 还是在传统的 Docker 容器中 , 都能够提供强大的日志采集能力 。
在 Sidecar 模式下 , iLogtail 更是与阿里云的 Serverless 容器实现了深度集成 。 通过这种集成 , iLogtail 能够轻松获取容器的元信息 , 为日志数据提供更精准的字段丰富化 。 这一特性进一步增强了日志分析的效果 , 使得用户能够通过更为详尽的信息做出快速响应 。 ?
参考文章:[1
https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
[2
https://github.com/elastic/elastic-agent-autodiscover/blob/main/kubernetes/watcher.go
[3
https://github.com/elastic/beats/issues/9776
[4
https://docs.fluentbit.io/manual/installation/kubernetes
[5
https://github.com/fluent/fluent-bit-kubernetes-logging/blob/master/output/kafka/fluent-bit-configmap.yaml
[6
https://github.com/fluent/fluent-bit/blob/master/plugins/filter_kubernetes/kube_meta.c
[7
https://github.com/alibaba/ilogtail/tree/main/example_config/start_with_k8s
[8
https://github.com/alibaba/ilogtail/blob/main/pkg/helper/docker_cri_adapter.go
[9
https://help.aliyun.com/zh/eci/?spm=a2c4g.11174283.0.0.6b1c6b06zzLIjW
[10
https://help.aliyun.com/product/2584271.html?spm=a2c4g.2584271.0.0.3dd7585fXUF3a7
?[11
一文搞懂容器运行时 Containerd?:https://www.qikqiak.com/post/containerd-usage/
[12
?OCI Runtime Specification 介绍?:https://yochalyc.com/2024/02/oci-runtime-specification-介绍/
[13
?cri-o 文档?:https://cri-o.io/
[14
?k3s 文档?:https://docs.k3s.io/architecture
[15
?micro k8s 文档?:https://microk8s.io/docs
[16
?K8S Runtime 种类多 , 使用复杂?那是你没明白其中的门道?:https://cloud.tencent.com/developer/article/1426607
[17
?从零开始入门 K8s:理解容器运行时接口 CRI?:https://www.infoq.cn/article/eah8zm3vh8mgwot5hokc
[18
?Fluent Bit 文档?:https://hulining.gitbook.io/fluentbit/pipeline/filters/kubernetes#configuration-parameters
推荐阅读













- 使用Python和TensorFlow进行机器学习实战
- ??减脂期间,跟着吃也会越吃越瘦|||选对食材减肥就是容易!
- 宋丹丹在餐厅学习被拍,都快退休还这么努力,中性打扮年轻不显老
- 高中地理有哪些高效学习法 学习方法归纳总结
- 高中地理学习方法归纳总结 有哪些高效学习法
- 高三物理学习方法技巧是什么 有哪些窍门
- 拓展学习视野的基本途径,怎么做才能更好地拓展你的视野和眼界
- 初三学生学习的方法有哪些,初三学习的学习方法
- 大学中必备的7种知识有哪些,在大学生活中,我们应该学习哪些方面的知识呢?
- 跳巴黎舞是不是要从小时候学,14岁还可不可以学习芭蕾舞