
文章图片
文章图片
文章图片

文章图片
文章图片
文章图片

文章图片
文章图片

文章图片
文章图片

文章图片
文章图片

文章图片
文章图片

9月10日 , Arm UNLOCKED 峰会在上海召开 。Arm在此次峰会上正式发布了面向移动端的 Arm Lumex 计算子系统(Compute Subsystem CSS) , 包括了全新的基于Armv9.3指令集的C1系列CPU集群 , 以及支持新一代光线追踪技术的Mali G1 GPU系列 。 其中 , C1 CPU集群均支持可扩展矩阵延伸指令集 SME2 , 极大地提升了CPU对于AI 和 ML 工作负载的支持 。
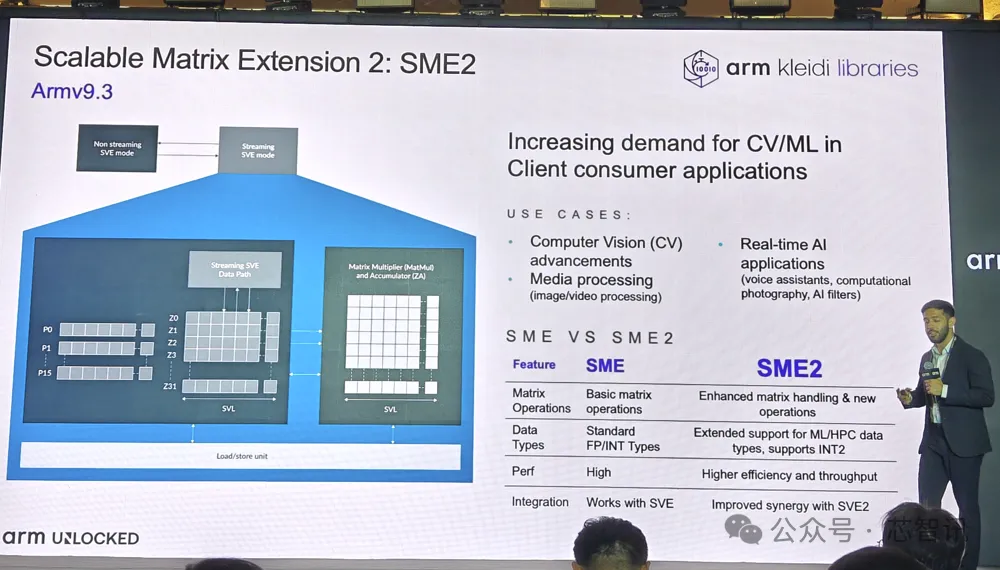
一、全新Armv9.3 , 加入对SME2支持
虽然对于目前的很多AI负载来说 , 利用GPU、NPU等计算单元来进行计算 , 可以拥有比CPU更高的计算效率 。 但是对于CPU厂商来说 , 也在不断通过融入一些新的指令集来提升CPU的AI计算能力 。
过去多年来 , Arm 也一直致力于提升的CPU的AI能力 , 比如在 Armv7 架构中引入了高级单指令多数据 (SIMD , 也称Arm Neon 指令) 扩展 , 探索了机器学习 (ML) 工作负载;Armv8.4-A 支持 8 位整数点积指令;Armv8.6-A 支持各种数据类型的矢量内整数和浮点矩阵乘法指令 。
进入到 Armv9 架构 , Arm在 CPU 上集成了用于加速和保护如大语言模型 (LLM) 等先进的生成式 AI 工作负载的特性 。 比如 , Armv9-A 加入了可伸缩矢量扩展 2 (SVE2) , 用于数字信号处理器 (DSP)、媒体和通用矢量化;Armv9.2-A 则首次引入了可伸缩矩阵扩展 (SME)指令 , 可加速 AI 和 ML 工作负载 , 并为 Arm CPU 上运行的 AI 和 ML 应用提供更高的性能、能效和灵活性 。
而全新的Armv9.3则加入了对于SME2的支持 , 即在 SME 的基础上增加了多矢量指令 , 允许在矩阵和矢量运算中复用架构状态 (ZA Array) , 并具有更高吞吐量的矢量处理能力 。 这有助于通过压缩 AI 格式来减少内存带宽并节省功耗 , 从而实现矢量和矩阵加速的平衡 。 SME2 还能够灵活地动态去量化 , 并解压缩 2 位和 4 位权重 , 以节省内存带宽 。 在生成式 AI 工作负载日益复杂和耗电加剧的背景下 , 这些特性非常重要 , 同时也彰显了 Arm 致力于应对 AI 无止尽的能源需求 。
二、面向AI高性能 Arm C1 CPU 集群
Arm全新的 C1 CPU 集群是 Arm Lumex CSS 平台的组件之一 , 也是首个基于 Armv9.3 架构的CPU 系列产品 。
最高性能的 Arm C1 CPU 集群集成了新的 C1-Ultra CPU , 以及可灵活组合的C1-Premium、C1-Pro 与 C1-Nano CPU 核心 , 能够根据合作伙伴的特定需求 , 实现性能和能效提升 。 同时 , C1 CPU 通过 Armv9 架构直接内建第二代 Arm 可伸缩矩阵扩展 (SME2) , 这为加速 AI 体验带来了革新突破 。
1、C1-Ultra:最强超大核
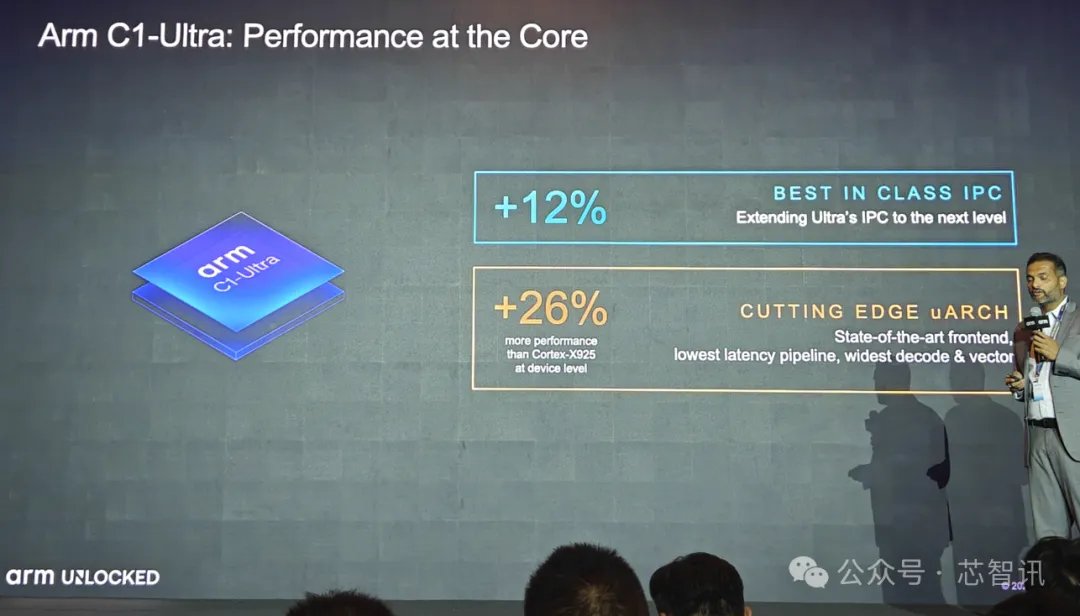
具体来说 , C1-Ultra作为的C1 CPU系列当中性能最强的超大核 。 其带来了业界领先的前端设计 , 并针对实际工作负载进行优化;拥有业内最宽、吞吐量最高的微架构;拥有出色的预取器 , 可在面积限制内优化性能 。
这些特性使得C1-Ultra 的 IPC 进一步提升了12% , 相比Cortex-X1的IPC提升了超过75% , 使得C1-Ultra内核的性能表现比Cortex-X925高出约26% 。
从Geekbench 6.3的测试数据来看 , 在同等性能水平下 , C1-Ultra的能耗比Cortex-X925低了28% , 而如果从最高的单线程性能来看 , C1-Ultra确实要比Cortex-X925高出25%左右 。
2、C1-Premium:最高PPA
C1-Premium是 Arm 首款次旗舰处理器CPU , 追求最高的PAA(性能、功耗、面积) 。
据Arm介绍 , C1-Premium核心面积比包含私有 L2 缓存的 C1-Ultra 核心缩小了 35% 。 该 CPU 在 SPEC 套件等基准测试中以更小的占用面积 , 保持了同等的性能水平 , 实现了卓越的面积效率 。
得益于极高的PPA , 这也使得C1-Premium可具有可灵活组合性 , 可以为新细分市场提供卓越性能 。
比如 , 原本2个C1-Ultra + 6个C1-Pro的CPU , 如果将超大核换成2个C1-Premium, 整体面积可以减少35%;同样 , 如果原本4个C1-Pro + 4个C1-Nano的CPU , 升级成2个C1-Premium + 6个C1-Pro的CPU , 在面积不会增加多少的情况下 , 性能可以迅速提升35% 。
不过 , Arm并未提供更多关于C1-Premium本身性能上的数据 。
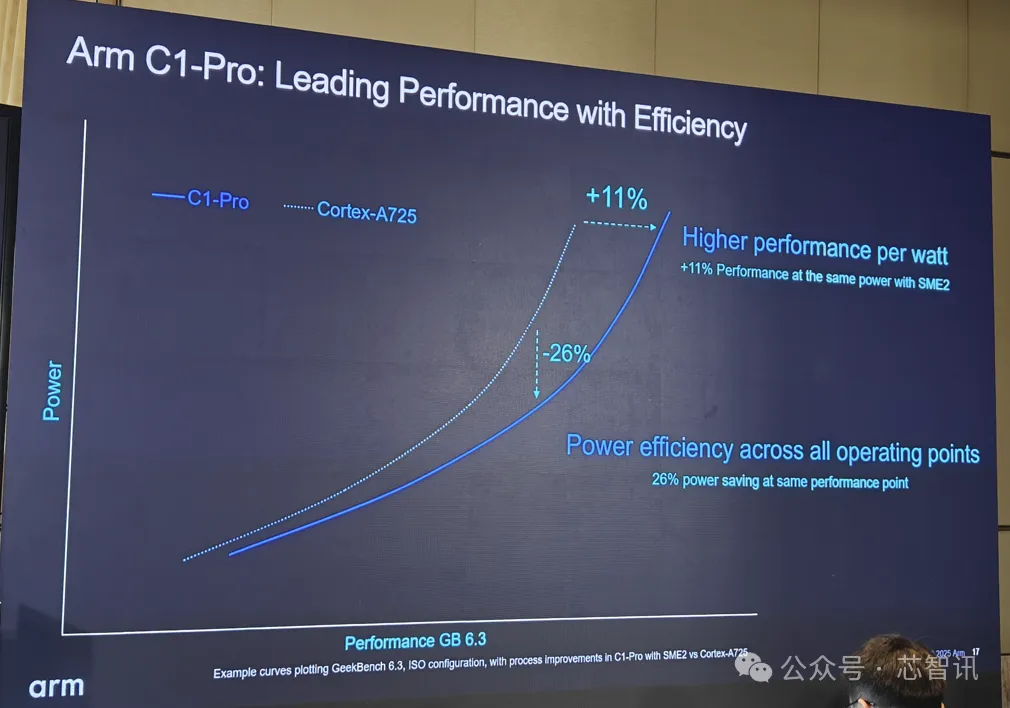
3、C1-Pro:最高能效大核
C1-Pro的定位是最高能效的大核 。 在微架构层面 , Arm C1-Pro 引入了增强型分支预测和内存系统更新 , 尤其适用于实际用例中的多任务处理 。
从Geekbench 6.3测试表现来看 , 在同等性能下 , C1-Pro的功耗要比Cortex-A725低26%;在同等功耗下 , C1-Pro的性能要比Cortex-A725高出11% 。
在相关应用测试中 , 与Cortex-A725相比 , C1-Pro CPU在相同主频下 , 性能最高提升了16%;在相同性能下 , 功耗降低了12% 。
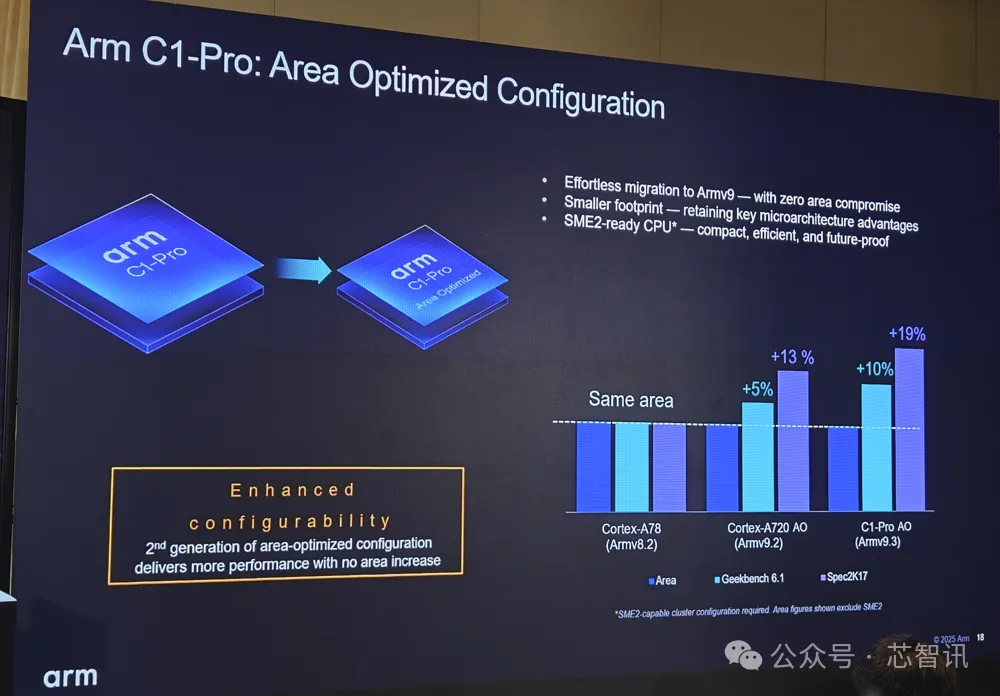
值得一提的是 , C1-Pro 还具有面积优化的配置方案 , 可以帮助客户轻松地迁移到最新的Armv9.3 , 无需牺牲任何面积 , 并且保留关键的微架构优势 , 并支持SME2 。
4、C1-Nano:最高能效小核
C1-Nano 在最小面积占用的条件下 , 将 Arm C1 系列 CPU 的优势集于一体 。 相比此前的Cortex-A520小核 , C1-Nano电源效率大幅提高 , 在同一工艺下 , 与 Cortex-A520 相比 , 电源效率提高 26%了;减少 L3/DRAM 交互 , 实现了最小面积和最高区域效率 。 与 Cortex-A520 相比 , SPECint2017 性能提高 5.5% , 核心面积提高 2%;改进了指令获取 , 解耦预测/获取流水线在获取工作负载方面提高了10%以上的性能 。
C1-Nano出色的高能效和低功耗表现 , 使其成为可穿戴设备和紧凑型消费类电子设备的理想之选 。
5、C1-DSU
DSU(DynamIQ Shared Unit)是Arm CPU集群架构中的一个关键组件 , 用于管理多核处理器的核心 , 优化性能和能效 。 对于全新的C1 CPU集群 , Arm也带来了全新的C1-DSU , 也加入了对于SME2的支持 。
据Arm介绍 , 与DSU-120相比 , C1-DSU典型功耗降低了11% , 快速唤醒 RAM 功耗降低了7% 。
6、Arm C1 CPU 集群可满足各类端侧应用
C1系列的四款CPU内核 , 也为Arm C1 CPU集群的组合带来了非常多的选择 。
如果拿最低端的2个C1-Nano(基于不支持SME2的DSU)与最高端的2个C1-Ultra + 6个C1-Pro(基于支持SEM2的DSU)对比 , 后者的性能达到了前者的17倍 , 不过面积也达到前者的25倍 。 足见性能、面积跨度之大 , 还可扩展至各个级别的消费类电子和移动设备 , 为多样化的端侧工作负载提供不同水平的性能、功耗和面积效率 。
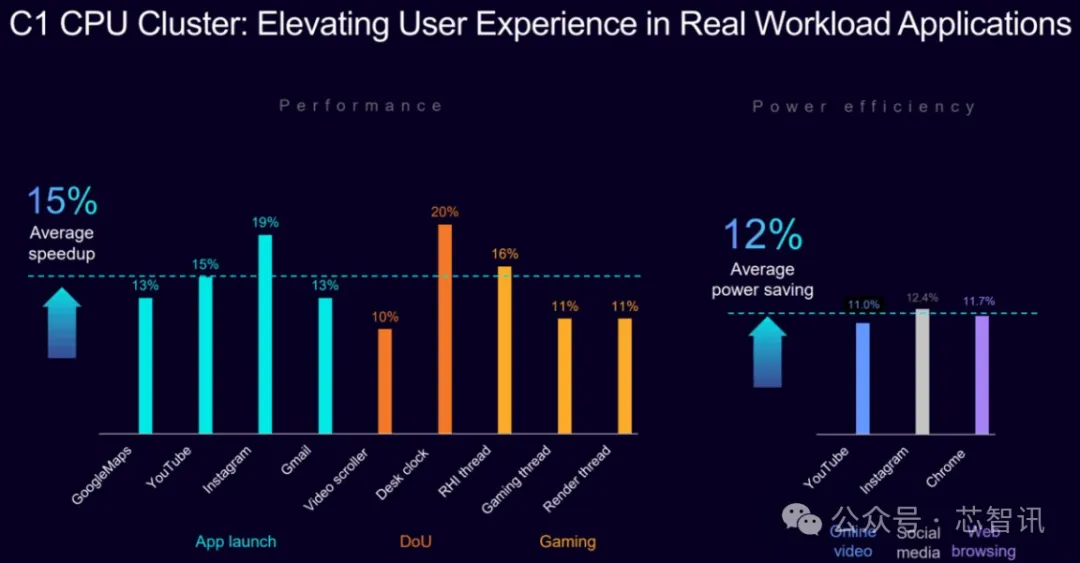
Arm C1 CPU 集群在实际用例中表现突出 。 在行业领先的性能基准测试 , 该 CPU 集群在同等条件下 , 相较于上一代 CPU 集群性能平均提升 30% , 在游戏和视频流媒体等应用中平均提速 15% 。 与此同时 , 在日常移动端工作负载(如视频播放、社交媒体、网页浏览)中 , 该 CPU 集群在同等条件下 , 相较于上一代 CPU 集群功耗平均降低 12% 。
在Arm看来 , 下一代主流的智能手机的CPU集群可能将会是支持SME2的C1集群 , 比如C1-Pro + C1-Nano这样的组合 , 预计相比当前的Cortex-A725+Cortex-A520的组合 , 可以带来11%的性能提升和2倍的AI性能密度 。
6、SEM2加持下的AI性能提升
得益于 SME2 内置的矩阵扩展 , Arm C1 CPU 能够加速 AI 功能 , 包括涉及大量矩阵运算的大语言模型 (LLM)、媒体处理(图像与视频)、语音识别、计算机视觉、实时应用(AI 助手、计算摄影与 AI 滤镜)以及多模态应用等 。 SME2 是在 SME 基础上进行了全新的智能升级 , 能提升性能、降低内存占用 , 并使端侧 AI 运行得更为流畅 , 尤其是在音频生成、摄像头推理、计算机视觉及即时聊天等高实时性要求的应用中 。
据Arm介绍 , 针对生成式 AI、语音识别、典型的机器学习 (ML) 和计算机视觉 (CV) 等工作负载 , 启用 SME2 的 Arm C1 CPU 集群在同等条件下 , 能比上一代 CPU 集群带来5倍 AI 性能提速 。 此外 , 借助 SME2 , 该C1 CPU 集群可实现多达3倍的能效优化 。 而上述的 AI 性能和能效改进能为用户带来更流畅、响应更迅速的端侧体验 。
Arm表示 , SME2 显著缩小了C1 CPU与GPU之间的AI性能差距 , 特别是在小型AI工作负载上 , CPU 现已超越 GPU , 并且保留了CPU的灵活性 。
从Arm公布的测试数据来看 , 在没有SME2 的支持下 , C1-Pro CPU的AI性能与Arm最新的Mali G1 GPU的AI性能差距巨大 。 但是 , 有了SME2加持的C1-Pro CPU , AI性能大幅提升 , 特别是在运行一些小的神经网络时 , 其性能表现甚至比Arm最新的Mali G1 GPU表现更好 。
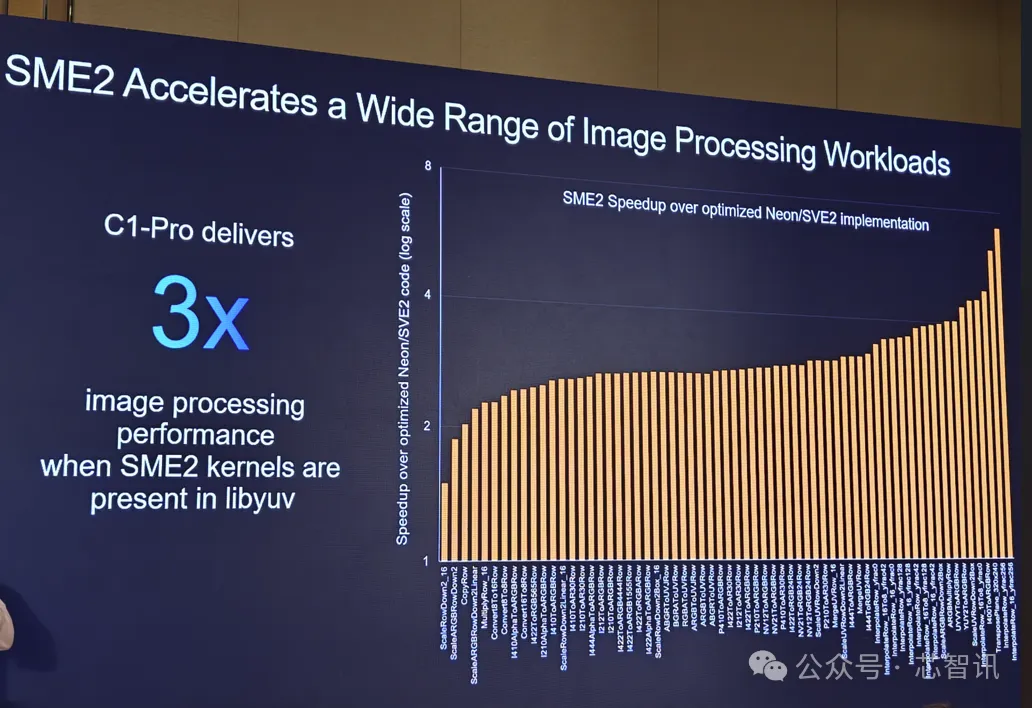
SME2 还可加速各种图像处理工作负载 , 比如在libyuv中 , 支持SME2的C1-Pro的图像处理表现提升到了原来的3倍 。
对于 Arm 合作伙伴和开发者生态系统而言 , 相较于未启用 SME2 特性的硬件 , 这些提升能显著加速不同工作负载和用例中的 AI 性能 , 包括:
在 Whisper Base 上处理语音工作负载时 , 延迟降低 4.7 倍;在 Google Gemma 3 模型上进行聊天交互 , AI 性能增长 4.7 倍;在 Stability AI Stable Audio 模型上生成音频 , 速度提升 2.8 倍 。
三、Mali G1-Ultra 重新定义游戏与 AI 体验
手机的游戏性能一直以来都是厂商和用户极为关心的一大关键能力 。 根据最新的 Newzoo 报告 , 手游玩家占据了高达 83% 的全球游戏玩家人口 , 其手游总时长达到 3900 亿小时 。
Arm作为移动计算平台的霸主 , 其也一直致力于利用自身的GPU来提升手机游戏体验 。 数据显示 , 截至目前 , 搭载 Arm GPU 的芯片出货量已逾 120 亿颗 。
此次 , Arm全新推出的Mali G1-Ultra是专为新一代手游和 AI 体验打造的GPU , 基于 Arm 第五代 GPU 架构 。 引入多项核心级改进 , 旨在移动设备上实现高端沉浸式游戏体验 。
与上一代的Immortalis-G925 GPU相比 , Mali G1-Ultra还带来了新一代 Arm 光线追踪单元 RTUv2 , 使得光线追踪性能达到了前一代的两倍;借助 IRD、tiler 改进、IDVS/计算调度 , 2倍快速访问统一内存 , 使得Mali G1-Ultra在主流图形基准测试中 , 性能表现提升了20%;通过优化计算和新的 MMUL.FP16 指令 , 使得AI性能也提升了20%;每帧生成的功耗也降低了9% 。
除了面向旗舰智能手机的 Mali G1-Ultra , Arm 还推出 Arm Mali G1-Premium 和 Mali G1-Pro GPU , 旨在提供可扩展的性能和能效选择 , 以满足不同移动设备市场和产品层级的需求 。 Mali G1 GPU 系列提供从 1 到 24 个着色器核心选项 , 使系统级芯片 (SoC) 设计商能够根据其目标市场和特定需求 , 灵活配置 GPU 。
1、新一代光线追踪单元RTUv2
得益于 Mali G1-Ultra 中的光线追踪单元RTUv2 , 在启用硬件光线追踪的游戏中 , 光线追踪性能可提升两倍 , 帧率可提升 40% 。 新的光线追踪单元专为移动端的实时性能而打造 , 实现了桌面级的光照、反射与阴影 。
与前一代 RTUv1 相比 , RTUv2 更加智能 , 且采用单光线模型 , 大幅增强对非一致性光线的支持 , 并成为完全独立的硬件单元 。 这些设计变化带来了显著的能效与性能优势 。 例如 , 其模块化架构与独立电源域使得 RTUv2 可在设备空闲时断电 , 从而为其他任务节省电力 。
鉴于通过 RTUv2 实现的性能与能效平衡的优势 , Mali G1-Ultra 能在旗舰智能手机上实现长时间的游戏体验 , 使其成为旗舰智能手机的理想配置 。
2、端侧实时智能加速
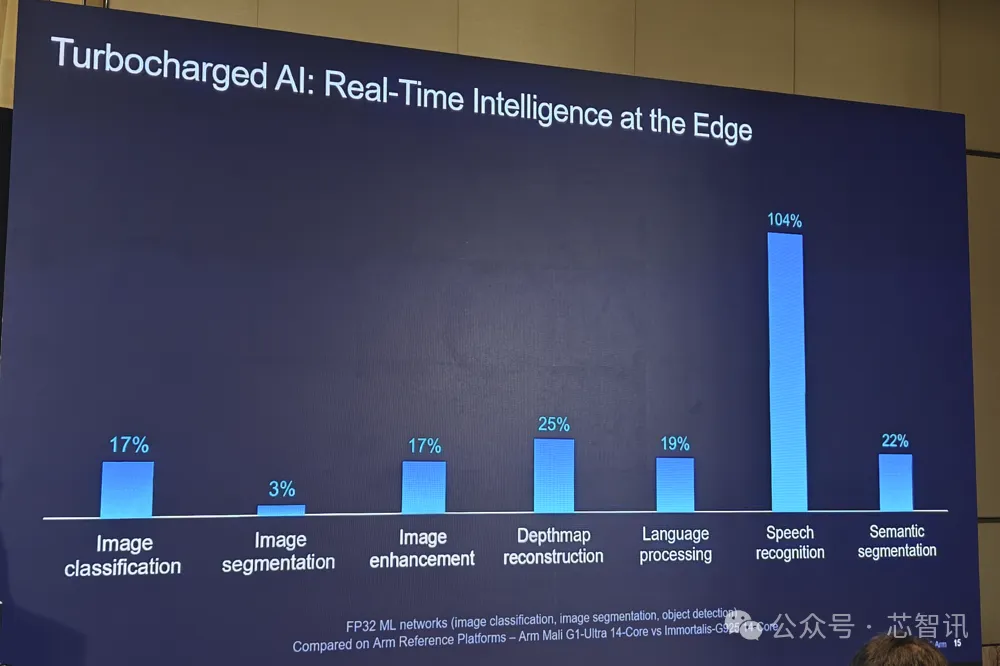
AI 正在重塑移动设备思考、感知与响应的方式 , 而 GPU 在这一演进历程中扮演着关键角色 。 Mali G1-Ultra 引入新的矩阵乘法单元 (MMUL) FP16 指令 , 可加速如语义分割、去噪、深度估计、物体检测、语音识别和图像增强等端侧关键 AI 工作负载 。 在FP32 ML网络中 , Mali G1-Ultra与上一代 Immortalis-G925(同样均为14核心)相比 , 其性能提升高达 104% 。
通过扩大的 L2 缓存和优化的互连设计 , Mali G1-Ultra 专为并行处理 AI 与图形工作负载而打造 , 大幅减少内存瓶颈 , 并确保实时体验的灵敏响应与流畅运行 。 无论是增强照片质量 , 还是支持更智能的应用交互 , Mali G1-Ultra 都在边缘侧实现响应灵敏的实时智能 。
3、可扩展性能的新架构特性
据介绍 , Mali G1-Ultra带来了双堆叠着色器核心 , 可使内部带宽加倍并减少拥塞;增加快速访问统一寄存器 , 以在着色器执行期间大幅减少内存提取 。 这些更新共同提升了包括实时光照和基于物理的渲染在内的响应效果(这些特效通常属于计算密集型工作负载) 。
此外 , Mali G1-Ultra 还引入 Arm 图像区域依赖 (Image Region Dependencies IRD) , 这是一种更智能的调度特性 , 使 GPU 能同时处理屏幕的不同部分 , 从而在复杂场景中提升性能并减少空闲时间 。
4、为开发者量身打造
为帮助开发者实现更精细的性能优化 , Mali G1 GPU 通过基于块 (tile) 的硬件计数器 , 提供更强的可观测性 。 这些计数器能逐帧按区域洞察 GPU 活动 , 让开发者可以更高效地识别热点 , 并平衡工作负载 。
这些计数器可通过 Vulkan 扩展访问 , 并将在未来的安卓版本中支持 RenderDoc 。 这让游戏引擎公司、游戏工作室和设备 OEM 厂商能够更为轻松地从该架构中获得最大性能 , 同时保持视觉质量和电池效率 。
Mali G1 GPU 还支持 Arm 精锐超级分辨率技术 (Arm Accuracy Super Resolution Arm ASR) , 这项时域类超分技术可在减少 GPU 工作负载的同时 , 提升图像质量 。 该技术通过虚幻引擎 5 (Unreal Engine 5) 提供 , 并已集成至《堡垒之夜》手游 。 Arm ASR 能帮助开发者在不牺牲视觉保真度的情况下 , 保持高帧率 , 从而在各种移动设备上实现更流畅的游戏体验与更清晰的细节效果 。
四、Arm Lumex CSS 平台
在2024年5月 , Arm就推出了面向客户端的计算子系统(CSS for Client) , 整合了当时最新的 Armv9.2 指令集的 CPU 集群 , 包括Cortex-X925 CPU、Cortex-A725 CPU、更新后的Cortex-A520 CPU , 以及Immortalis-G925 GPU等IP 。
此次Arm最新的发布的Arm Lumex CSS 平台是专门面向旗舰智能手机和大屏计算设备的计算子系统 , 不仅整合了前面介绍的Arm C1 CPU集群、Mali G1-Ultra GPU、C1-DSU , 还带来了Arm SI L1 系统互连与 Arm MMU L1 系统内存管理单元等IP 。
1、面向AI优先SoC平台的系统IP
Lumex CSS平台要支持 AI 优先体验 , 自然不能只局限于CPU、GPU等计算 IP 和前面提到的多核调度的DSU IP的提升 , 还必须在整个互连和内存架构层面持续演进 。 所以 , Arm为了Lumex CSS平台带来了全新的SI L1和MMU L1和NoC S3等系统IP , 专为满足高要求 AI 和其他计算密集型工作负载的带宽与延迟需求而优化 。
具体来说 , 新的SI L1系统互连适用于需要硬件管理一致性、SLC和高级QoS的数据共享的高性能设计 。 其配备了业内先进的 , 且具有出色面积效率的系统级缓存 (SLC), 相比标准编译的 RAM , 其泄漏功耗降低了 71% , 大幅减少了待机功耗 。
SI L1 系统互连面向旗舰移动设备 , 具备完全集成的可选 SLC 并支持 Arm 内存标记扩展 (Memory Tagging Extension MTE) 特性 , 可提供一流的安全性 。
而MMU L1则是新一代面向移动优化的内存管理单元(Memory Management Unit , MMU) , 通过PPA优化提高系统MMU的可负担性和可扩展的安全基础 , 可以为Android和Windows设备实现基于内存转换的安全、经济、高效的可扩展虚拟化 。
据Arm披露的数据显示 , SI L1 系统互连相比上代的CI-7000 , 互联延迟降低了75%;MMU L1相比上代的MMU-700最多可将TBU延迟降低83% 。
NoC S3 片上网络互连则面向注重成本且非一致性的移动系统 。
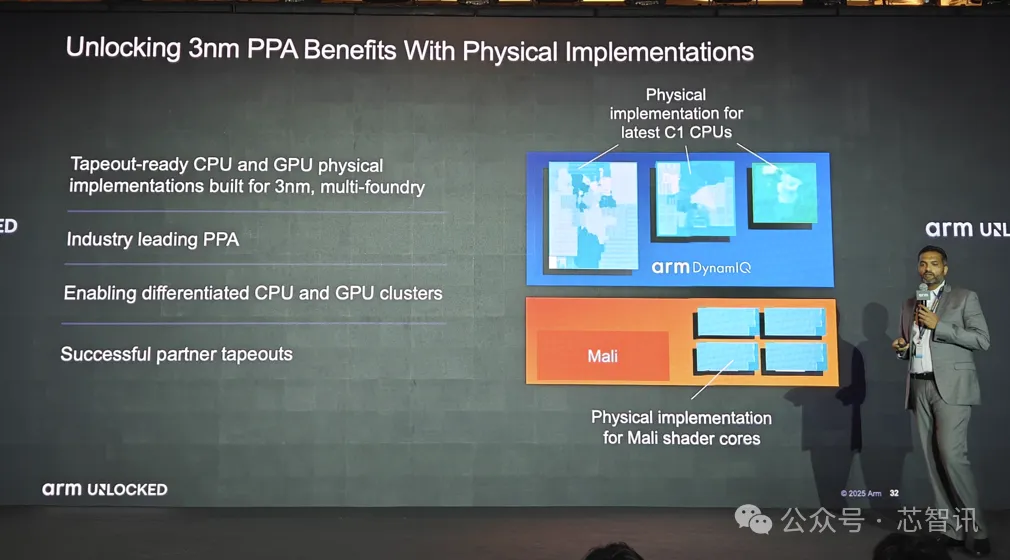
2、解锁3nm物理实现
据Arm介绍 , Lumex CSS提供针对3nm工艺优化、生产就绪的 CPU 和 GPU 实现 , 已为多家晶圆代工厂所支持 。
如此一来 , Arm 的芯片合作伙伴和 OEM 厂商能够:将这些实现作为灵活的构建模块 , 以便专注于 CPU 和 GPU 集群层面的差异化设计;实现卓越的频率和 PPA;在向最新 3nm 工艺节点过渡时 , 助力确保芯片一次流片成功 。
3、全栈软件已就绪
为充分释放 Lumex CSS性能潜力 , 帮助客户在硅片发货前 , 实现从固件到应用程序的所有层的顶级性能 , Arm 推出了全新系列的软件与工具 , 助力开发者即刻着手原型设计、构建 AI 工作负载 , 以及利用 Lumex CSS 平台的完整 AI 功能 。
这些软件与工具包括:完整的 Android 16 就绪软件栈 , 涵盖可信固件至应用程序层;完整且免费的启用 SME2 的 KleidiAI 软件库;全新的自顶向下的遥测解决方案 , 用于分析应用性能、识别瓶颈并优化算法 。
Arm KleidiAI 于 2024 年推出 , 旨在为Arm CPU 上运行的 AI 推理工作负载提供软件性能优化 , 开发者无需进行任何额外的工作 , 目前该软件库已应用于移动端、云和数据中心等关键领域 , 包括 KleidiAI 已被集成到 ExecuTorch、Llama.cpp、MediaPipe、PyTorch、LightRT等几乎所有主流AI框架的最新版本中 , 开发者只需开始构建应用程序 , 即可在基于 Arm 架构的平台上自动获取性能的显著提升 。
因此 , 当基于 Lumex 的设备在未来数月上市时 , 应用程序即刻就能在其 AI 工作负载上实现性能和效率提升 。
在图形处理方面 , 随着未来的安卓版本将支持 RenderDoc , 以及通过 Lumex 提供 Vulkan计数器、Streamline 和 Perfetto 等统一可观测性工具 , 开发者能够实时分析工作负载、调优延迟 , 并精确平衡电池续航与视觉效果 。
小结:
Arm全新推出的 C1 CPU 集群提供了高性能、高能效、高可扩展性的内核IP选择 , 并且凭借对于SME2的支持 , 极大地提升了CPU的AI性能 , 为未来端侧 AI 的发展奠定了坚实的基础 。
全新的Mali G1-Ultra 则重新定义了移动 GPU 的性能 , 在光线追踪性能提升的同时 , 在架构效率和AI加速性能上也迎来了突破性进展 , 有望为新一代移动终端的游戏体验和AI应用带来更出色的体验 。
基于全新IP的Arm Lumex CSS 平台则为客户带来了更为完整的CPU/GPU集群解决方案和软件栈 , 以及基于3nm节点的物理版图 , 这在当前众多科技大厂纷纷自研芯片的热潮下 , 将有助于他们大幅降低在CPU/GPU集群研发上的投入 , 可以更专注地投入到自己核心的需求研发上 , 提升芯片一次流片成功率 , 加速产品的推出周期 。
不过 , Arm高管在采访环节也明确指出 , 目前Arm的 CSS 平台只是专注于其擅长的CPU、GPU IP和集群解决方案 , 可以为客户提供参考设计和物理实现 , 并不意味着Arm利用Lumex CSS平台就可以为客户定制完整的SoC解决方案 , 客户也并不能利用Lumex CSS平台就能够直接交由晶圆代工厂生产自己的芯片 , 因为SoC并不只有CPU/GPU就能够运行 , 这并不是一个完整的SoC解决方案 , 客户仍然需要在Lumex CSS平台基础上加入一系列自己的IP或第三方IP来打造一个完整的SoC解决方案 , 比如接口IP、NPU IP、基带IP等等 。
值得一提的是 , 以往Arm在发布全新的CPU/GPU IP时都会透露相关产品的大致上市时间 , 也会有相关芯片厂商宣布将会率先采用 , 但是在这次的发布会上却并没有 , 只有vivo这家手机厂商高管有上台发言 。 不过 , 猜测联发科即将发布的天玑9500有可能会采用Arm全新的C1 CPU集群及G1-Ultra GPU 。
【Arm Lumex CSS发布:全新C1 CPU与G1-Ultra GPU详解】编辑:芯智讯-浪客剑
推荐阅读













- HarmonyOS 5再次发力:华为Mate40 Pro,升级有望!
- AMD力挺x86生态系,直言Arm架构已无优势
- AMD:与x86相比,Arm架构已无任何优势!
- x86强势回归!AMD自信:Arm架构处理器已无任何优势
- HarmonyOS 6.0新功能被确认:控制中心有变化,人脸解锁也是!
- HarmonyOS 5.1再次发力:多款机型已推送更新,你收到了吗?
- ARM聘亚马逊AI芯片主管,助力自主芯片研发
- 为加速自研芯片研发,Arm挖来了亚马逊AI芯片掌门人
- 小米玄戒O2最快明年二季度推出 将采用最新Arm公版架构
- Arm神经技术革新移动端AI图形性能,设备预计明年底上市