
文章图片

文章图片
文章图片
机器之心报道
编辑:杨文、泽南
昨天 , 月之暗面发了篇博客 , 介绍了一款名为 Kimi-Researcher 的自主 Agent 。
这款 Agent 擅长多轮搜索和推理 , 平均每项任务执行 23 个推理步骤 , 访问超过 200 个网址 。 它是基于 Kimi k 系列模型的内部版本构建 , 并完全通过端到端智能体强化学习进行训练 , 也是国内少有的基于自研模型打造的 Agent 。
GitHub 链接:https://moonshotai.github.io/Kimi-Researcher/
在「人类最后一场考试」(Humanity's Last Exam) 中 , Kimi-Researcher 取得了 26.9% 的 Pass@1 成绩 , 创下最新的 SOTA 水平 , Pass@4 准确率也达到了 40.17% 。
从初始的 8.6% HLE 分数开始 , Kimi-Researcher 几乎完全依靠端到端的强化学习训练将成绩提升至 26.9% , 强有力地证明了端到端智能体强化学习在提升 Agent 智能方面的巨大潜力 。
Kimi-Researcher 还在多个复杂且极具挑战性的实际基准测试中表现出色 。 在 xbench (一款旨在将 AI 能力与实际生产力相结合的全新动态、专业对齐套件)上 , Kimi-Researcher 在 xbench-DeepSearch 子任务上平均 pass@1 达到了 69% 的分数(4 次运行的平均值) , 超越了诸如 o3 等带有搜索工具的模型 。 在多轮搜索推理(如 FRAMES、Seal-0)和事实信息检索(如 SimpleQA)等基准测试中 , Kimi-Researcher 同样取得了优异成绩 。
举个例子 。 我们想找一部外国动画电影 , 但只记得大概剧情:
我想找一部外国的动画电影 , 讲的是一位公主被许配给一个强大的巫师 。 我记得她被关在塔里 , 等着结婚的时机 。 有一次她偷偷溜进城里 , 看人们缝纫之类的事情 。 总之 , 有一天几位王子从世界各地带来珍贵礼物 , 她发现其中一位王子为了得到一颗宝珠作为礼物 , 曾与当地人激烈交战 。 她指责他是小偷 , 因为他从他们那儿偷走了圣物 。
随后 , 一个巫师说服国王相信她在撒谎 , 说她被某种邪灵附体 , 并承诺要为她“净化” , 作为交换条件是娶她为妻 。 然后巫师用魔法让她变成一个成年女子 , 并把她带走 。 他把她关进地牢 , 但她有一枚可以许三个愿望的戒指 。
由于被施了魔法 , 让她失去了逃跑的意志 , 她把前两个愿望浪费在了一些愚蠢的东西上 , 比如一块布或者一张床之类的……然后她好像逃出来了……并且耍了那个巫师一把……她后来还找到了一块可以生出水的石头……我记得还有人被变成青蛙……
整部电影发生在一个有点后末日设定的世界里 , 是一个古老魔法文明崩塌几百年之后的背景 。 如果有人知道这是什么电影 , 请告诉我 。 我一直在找这部电影 , 已经找了好久了 。
[ 上下滑动查看更多
Kimi-Researcher 就会根据给定的模糊信息进行检索 , 最终识别出该电影为《阿瑞特公主》 , 并一一找出该电影与剧情描述之间的对应关系 。
此外 , 它还能进行学术研究、法律与政策分析、临床证据审查、企业财报分析等 。
Kimi–Researcher 现已开始逐步向用户推出 , 可以在 Kimi 内实现对任意主题的深入、全面研究 。 月之暗面也计划在接下来的几个月内开源 Kimi–Researcher 所依赖的基础预训练模型及其强化学习模型 。
端到端的智能体强化学习
Kimi–Researcher 是一个自主的智能体与思维模型 , 旨在通过多步规划、推理和工具使用来解决复杂问题 。 它利用了三个主要工具:一个并行的实时内部搜索工具;一个用于交互式网页任务的基于文本的浏览器工具;以及一个用于自动执行代码的编码工具 。
传统 agent 开发存在以下几个关键限制:
- 基于工作流的系统:多智能体工作流将角色分配给特定智能体 , 并使用基于提示的工作流进行协调 。 虽然有效 , 但它们依赖于特定的语言模型版本 , 并且在模型或环境发生变化时需要频繁手动更新 , 从而限制了系统的可扩展性和灵活性 。
- 带监督微调的模仿学习(SFT):模仿学习能使模型很好地对齐人类演示 , 但在数据标注方面存在困难 , 尤其是在具有长时间跨度、动态环境中的智能体任务中 。 此外 , SFT 数据集通常与特定工具版本强耦合 , 导致随着工具的演变 , 其泛化能力会下降 。
OpenAI 的 Deep Research 等先前研究也展示了这种方法的强大性能 , 但它也带来了新的挑战:
- 动态环境:即使面对相同的查询 , 环境结果也可能随时间发生变化 , 智能体必须具备适应不断变化条件的能力 。 目标是实现对分布变化的鲁棒泛化能力 。
- 长程任务:Kimi–Researcher 每条轨迹可执行超过 70 次搜索查询 , 使用的上下文窗口长度甚至达数十万 token 。 这对模型的记忆管理能力以及长上下文处理能力提出了极高要求 。
- 数据稀缺:高质量的用于智能体问答的强化学习数据集非常稀缺 。 该研究团队通过自动合成训练数据的方式解决这一问题 , 从而实现无需人工标注的大规模学习 。
- 执行效率:多轮推理和频繁工具调用可能导致训练效率低下 , GPU 资源利用不足 。 优化 rollout 效率是实现可扩展、实用的智能体强化学习训练的关键 。
Kimi–Researcher 是通过端到端的强化学习进行训练的 。 研究团队在多个任务领域中观察到了智能体性能的持续提升 。 图 2-a 展示了 Kimi–Researcher 在强化学习过程中整体训练准确率的变化趋势;图 2-b 则呈现了模型在若干内部数据集上的性能表现 。
训练数据
为了解决高质量智能体数据集稀缺的问题 , 研究团队在训练语料的构建上采取了两种互补的策略 。
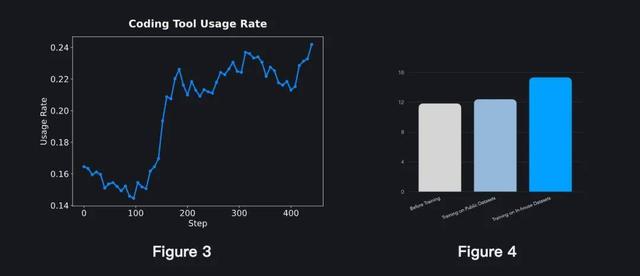
首先 , 他们设计了一套具有挑战性的、以工具使用为核心的任务 , 旨在促进智能体对工具使用的深入学习 。 这些任务提示被刻意构造为必须调用特定工具才能解决 —— 从而使得简单的策略要么根本无法完成任务 , 要么效率极低 。 通过将工具依赖性融入任务设计中 , 智能体不仅学会了何时调用工具 , 也学会了在复杂的现实环境中如何高效协同使用多种工具 。 (图 3 展示了在这些训练数据中 , 模型对工具的调用频率 。 )
其次 , 他们策划并整合了一批以推理为核心的任务 , 旨在强化智能体的核心认知能力 , 以及其将推理与工具使用结合的能力 。 该部分进一步细分为以下两类:
- 数学与代码推理:任务聚焦于逻辑推理、算法问题求解和序列计算 。 Kimi–Researcher 不仅依赖思维链进行解题 , 还能结合工具集解决这类复杂问题 。
- 高难度搜索:这类任务要求智能体在上下文限制下进行多轮搜索、信息整合与推理 , 最终得出有效答案 。 案例研究表明 , 这些高难搜索任务促使模型产生更深层的规划能力 , 以及更健壮、工具增强的推理策略 。
此外 , 他们还设计了严格的过滤流程 , 以剔除歧义、不严谨或无效的问答对;其中引入的 Pass@N 检查机制 , 可确保仅保留具有挑战性的问题 。 图 4 展示了基于两项实验结果的合成任务效果评估 。
强化学习训练
该模型主要采用 REINFORCE 算法进行训练 。 以下因素有助于提升训练过程的稳定性:
- 基于当前策略的数据生成(On-policy Training):生成严格的 on-policy 数据至关重要 。 在训练过程中 , 研究团队禁用了 LLM 引擎中的工具调用格式强制机制 , 确保每条轨迹完全基于模型自身的概率分布生成 。
- 负样本控制(Negative Sample Control):负样本会导致 token 概率下降 , 从而在训练中增加熵崩塌(entropy collapse)的风险 。 为应对这一问题 , 他们策略性地丢弃部分负样本 , 使模型能够在更长的训练周期中持续提升表现 。
- 格式奖励(Format Reward):如果轨迹中包含非法的工具调用 , 或上下文 / 迭代次数超出限制 , 模型将受到惩罚 。
- 正确性奖励(Correctness Reward):对于格式合法的轨迹 , 奖励依据模型输出与标准答案(ground truth)之间的匹配程度进行评估 。
上下文管理
在长程研究任务中 , 智能体的观察上下文可能会迅速膨胀 。 如果没有有效的记忆管理机制 , 普通模型在不到 10 次迭代内就可能超过上下文限制 。 为了解决这一问题 , 研究团队设计了一套上下文管理机制 , 使模型能够保留关键信息 , 同时舍弃无用文档 , 从而将单条轨迹的迭代次数扩展至 50 次以上 。
早期的消融实验表明 , 引入上下文管理机制的模型迭代次数平均提升了 30% , 这使其能够获取更多信息 , 进而实现更优的任务表现 。
大规模智能体RL infra
为应对大规模智能体强化学习在效率与稳定性方面的挑战 , 研究者构建了一套具备以下关键特性的基础设施体系:
- 完全异步的 rollout 系统:实现了一个具备扩展性、类 Gym 接口的全异步 rollout 系统 。 基于服务端架构 , 该系统能够高效并行协调智能体的轨迹生成、环境交互与奖励计算 。 相较于同步系统 , 这一设计通过消除资源空转时间显著提升了运行效率 。
- 回合级局部回放(Turn-level Partial Rollout):在 Agent RL 训练中 , 大多数任务可在早期阶段完成 , 但仍有一小部分任务需要大量迭代 。 为解决这一长尾问题 , 研究者设计了回合级局部回放机制 。 具体来说 , 超出时间预算的任务将被保存至 replay buffer , 在后续迭代中以更新后的模型权重继续执行剩余部分 。 配合优化算法 , 该机制可实现显著的 rollout 加速(至少提升 1.5 倍) 。
- 强大的沙盒环境:研究者构建了统一的沙盒架构 , 在保持任务隔离性的同时 , 消除了容器间通信开销 。 基于 Kubernetes 的混合云架构实现了零停机调度与动态资源分配 。 Agent 与工具之间通过 MCP(Model Context Protocol)进行通信 , 支持有状态会话与断线重连功能 。 该架构支持多副本部署 , 确保在生产环境中具备容错能力与高可用性 。
在端到端强化学习过程中 , 研究者观察到 Kimi–Researcher 出现了一些值得关注的能力涌现 。
- 面对多来源信息冲突时 , Kimi–Researcher 能通过迭代假设修正与自我纠错机制来消除矛盾 , 逐步推导出一致且合理的结论 。
- 展现出谨慎与严谨的行为模式:即便面对看似简单的问题 , Kimi–Researcher也会主动进行额外搜索 , 并交叉验证信息后再作答 , 体现出高度可靠性与信息安全意识 。
推荐阅读















- 「悄悄发育」的华为 AI,这次放了个「大招」
- 老罗数字人刷屏背后,AI导演正偷偷改写直播「剧本」
- 支付宝突然整了个王炸级大招,「看一下支付」
- 苹果官方大降价!额外还送 AirPods 4 降噪耳机「详细版本」
- 7410mAh+100W快充+超324万跑分,红米两台新「性能猛兽」月底杀到
- 同一天开源新模型,一推理一编程,MiniMax和月之暗面开卷了
- 能「听」见更能「听」懂万国语,Leion Hey2 什么水平?
- 「摸鱼」被踢,GPT-4o真不行,30天筹款破万,AI真人秀太上头
- 挑战一线品牌!七彩虹iGame M16 是否配得上「万元旗舰守门员」?
- 月之暗面放王炸!开源Kimi新模型:超新版DeepSeek R1全球第一