
文章图片

文章图片
文章图片

文章图片

文章图片
【田渊栋:连续思维链效率更高,可同时编码多个路径,“叠加态”式并行搜索】
文章图片
AI也有量子叠加态了?
连续思维链的并行搜索类似于量子叠加 , 比离散型思维链更具优势 。
这是AI大牛田渊栋团队的最新研究成果 。
传统LLM通过生成 “思维token”(如文本形式的中间步骤)进行推理(即离散思维链) , 但在处理复杂任务(如判断有向图中节点是否可达)时效率低下 , 需要O(n^2)步解码(n为节点数) , 且容易陷入局部解 。
近期研究发现 , 用连续隐向量(非离散token)进行推理能显著提升性能 , 但缺乏理论解释 。
田渊栋领衔来自UC伯克利、UCSD的科学家们利用连续空间中的 “叠加态” , 让大模型进行并行推理 , 大幅提升了模型在图可达性等任务中的表现 , 给上述连续思维链提供了理论支持 。
团队证明了:
对于具有n个顶点且直径为D的图 ,一个包含D步连续CoTs的两层Transformer可以解决有向图可达性问题 , 而具有离散CoTs的恒定深度Transformer的最佳已知结果需要O(n^2)个解码步骤 。
简单来说 , 对于有向图可达性问题 , 离散思维链类似于深度优先搜索(DFS) , 每次只能选择单一路径 , 导致步骤多且容易受限 。
而连续思维链可以同时编码多个候选图路径 , 类似于广度优先搜索(BFS) , 并且可以利用这种“叠加”进行隐式的「并行搜索」 , 比离散思维链更具优势 。
让我们来看看实验细节 。
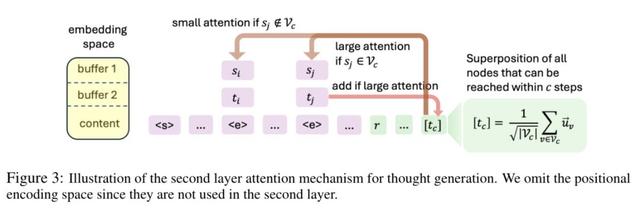
跟着“导航”找思维路径 像 “导航仪” 一样的注意力选择器团队设计了一种注意力选择器机制 , 使模型能根据当前token选择性地关注特定位置(如边的源节点和目标节点) , 确保信息的有效提取 。
这个注意力选择器就好比我们开车时用的导航仪 , 能帮模型在一堆信息里精准找到该关注的地方 。
具体来说 , 当模型在处理信息时 , 遇到特定的 “标记” , 比如表示一条边结束的token , 就像导航仪识别出一个路口标识 , 这时候它就会自动把注意力集中到这条边的起点和终点节点上 。
就像你看到 “前方路口右转” 的提示后 , 会重点关注那个路口的位置 。
如果没遇到这种明确的标记 , 注意力选择器就会模型去关注开头的信息 , 比如问题最开始给出的条件 , 这样就能确保模型不会在信息堆里迷路 , 始终能从正确的起点开始思考 。
两层连续思维Transformer进行叠加态维护什么是连续思维的“叠加态”?
我们这里所说的“叠加态” 就像一个装着所有可能答案的“盒子” 。
比如 , 从根节点出发走c步后 , 这个盒子里不会只装着一条路径 , 而是同时装着所有c步内可达的节点 , 这些节点的信息被 “揉” 成一个向量(即思维向量) , 让模型能一次性处理所有可能性 , 而不是一次只考虑一条路径 。
第一层Transformer:“整理” 边的信息
假设我们有一个有向图 , 边用token 表示 , 每个边token旁边还带着它的源节点(起点)和目标节点(终点) 。
此外 , 根节点r是探索的起点 , 初始思维向量就是r的嵌入向量
。
第一层Transformer 有5个注意力头 , 每个头就像一个 “信息收集小助手” , 它们的任务是:
当遇到一个边token 时 , 小助手会 “主动” 关注这个边的源节点和目标节点 , 并把这两个节点的信息 “复制” 到边token的位置上 , 就像在边token旁边贴两张标签 , 分别写着 “起点是XXX” 和 “终点是XXX” 。
举个例子:如果有一条边是从节点A到节点B , 边token 会被处理成包含A和B的信息 , 方便后续使用 。
经过第一层处理后 , 每条边的信息都被明确标注了起点和终点 , 初始思维向量也被保留下来 , 作为下一步探索的基础 。
第二层Transformer:“并行探索” 所有可能路径
这一层就像 “探索指挥官” , 它会根据当前的叠加态(即当前能到达的所有节点) , 去寻找下一步能到达的新节点:
假设当前叠加态里有节点集合Vc(c步内可达的节点) , 模型会 “扫描” 所有边 , 看看哪些边的源节点在Vc里 。 比如 , 若Vc里有节点A和B , 就查看从A和B出发的所有边 。
对于符合条件的边 , 其目标节点会被 “添加” 到叠加态中 , 形成新的节点集合Vc+1(c+1步内可达的节点) 。 这就好比从A和B出发 , 发现能到达C和D , 于是把C和D也放进 “盒子” , 让下一轮探索能考虑这些新节点 。
MLP层:“过滤” 和 “平衡”
过滤噪声:叠加态在扩展过程中可能会混入一些 “不重要的节点”(类似盒子里进了杂物) , MLP层会像 “筛子” 一样 , 把那些权重很小的节点(即几乎不可能到达的节点)过滤掉 , 只保留有价值的节点 。
平衡权重:过滤后 , MLP层会让剩下的节点在叠加态中的 “权重” 变得均匀 , 就像把盒子里的节点信息整理得整整齐齐 , 不让某个节点的信息 “压倒” 其他节点 , 确保模型能公平地考虑每一个可能的路径 。
对比试验及结果团队使用ProsQA数据集的子集进行实验 , 该子集中的问题需要3-4推理步长来解决 , 且图中的每个节点都作为一个专用token注入到词汇表中 。
实验结果显示 , 采用COCONUT(连续思维链)的2层Transformer模型在解决ProsQA问题时表现出色 , 准确率接近100% 。
相比之下 , 12层的离散CoT模型准确率仅为83% , 而无CoT基线模型只能解决约75%的任务 。
此外 , 团队还通过对注意力模式和连续思维表示的分析 , 进一步证实了模型中存在预期的叠加态搜索行为 , 直接支持了“叠加态存在”的理论假设 。
不仅能搞科研 , 还能写小说田渊栋任职于Meta GenAI(前FAIR) , 但业余时间是一位小说家(doge) 。
没错 , 具体来说是科幻小说家 。
田渊栋在谈到第一部作品的写作动因时说:
在AI最火热的时候我写了本小说
2020年到2021年 , 他完成了第一部长篇科幻小说《破晓之钟》 , 该作品于2024年6月正式出版 。
△
《破晓之钟》讲述了几个初出茅庐的科学家们如何面对来自外太空的挑战、如何处理人类危机的故事 。
但区别于《三体》 , 《破晓之钟》的技术背景离我们当前所处的时代更近 , 甚至都是我们这几年人人都在谈论、全球火热的技术风口 。
这本书的核心观点是:AI只是在模仿数据 , 却让人误以为它有智慧 。
这一观点写于ChatGPT爆火之前 , 却精准预言了大语言模型的本质 。
这部作品也收获了不少读者的好评 。
田渊栋在今年5月接受交大校友采访时还透露 , 由于写第一部小说时还没有大模型 , 所以每个字都是自己手敲的 , 接下来的第二部应该会用AI尝试一下辅助写作 。
目前 , 他的第二部小说正在构思中 , 还是延续《破晓之钟》世界观 , 时间线会往后推很多 , 可能涉及到“群体意识”和“星际殖民”这类议题 。
他说:
我希望写出更大的宇宙 , 但核心依然是人类的选择与挣扎 。
论文地址:https://arxiv.org/abs/2505.12514
参考链接:
[1
https://x.com/tydsh/status/1935206012799303817
[2
https://zhuanlan.zhihu.com/p/15135181332?share_code=1io696PXYfDXYutm_psn=1919011036050219530
[3
https://www.douban.com/doubanapp/dispatch/book/36946627?dt_dapp=1
推荐阅读












- 华为Pura80系列“连续变焦”专利详细解析!对比索尼,谁更强?
- 手机or相机?华为首发一底双长焦,年底还有连续光变?
- 荣耀Magic8Pro大改变:连续光变+24GB运存,封神之作
- 抛开传统固化思维,索尼、佳能、尼康三家微单相机优劣之分与选择
- C++创始人:需要改变的不是语言,而是开发者的思维方式!
- 四大引擎来袭,20个应用连续启动0卡顿,魅族Flyme AIOS2再确认
- 登山机器人五一爆火,参演流浪地球的机器人公司连续融资两轮
- 被人遗忘的「中端SOC」,已经连续四年都在原地踏步了
- 魅族16系列与Flyme 12:经典再现,20 个应用连续启动 0 卡顿
- 连续拍8小时视频还有20%的电,OPPO K12s的续航有多牛?