
文章图片
文章图片
文章图片
文章图片
文章图片
Google DeepMind团队开发的DataRater可以全自动评估数据质量 , 通过元学习自动筛选有价值的数据 , 提升模型训练效率 。 DataRater使用元梯度优化 , 能有效减少训练计算量 , 提高模型性能 , 尤其在低质量数据集上效果显著 , 且能跨不同模型规模进行泛化 。
机器学习领域有一条铁律 , 「Garbage In Garbage Out.」 , 就是说模型的质量很大程度上取决于训练数据的质量 。
大模型在预训练阶段会吸收海量的数据 , 其中数据的来源非常杂 , 导致质量参差不齐 。
大量的实验和经验已经证明了 , 对预训练数据进行质量筛选是提高模型能力和效率的关键 。
常规做法是直接人工筛选数据源 , 或是对不同数据源编写启发式规则筛选出高质量数据 , 再手动调整 , 工作量非常大 。
随着合成数据的盛行 , 把一些偏差、重复、质量低下的数据都加入到预训练数据集中 , 进一步扰乱了模型的性能分析 。
最近 , Google DeepMind的研究人员发布了一个数据质量评估框架DataRater , 可用于估计任意数据对最终训练效果的价值 , 即数据质量 。
论文链接:https://arxiv.org/pdf/2505.17895
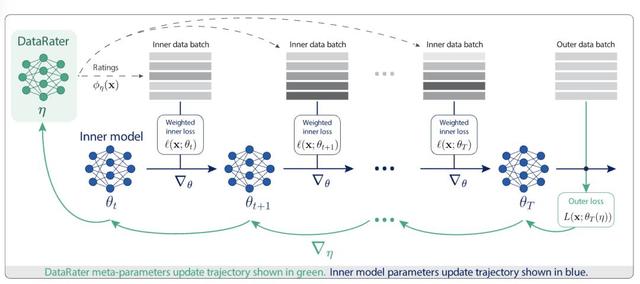
DataRater的核心思路是使用「元学习」来自动学习筛选或混合数据流的标准 , 以一种数据驱动的方式 , 让数据展现出本身的价值 。
指定训练目标(提高在保留数据上的训练效率、更小的验证损失值)后 , DataRater使用元梯度(根据数据与性能之间的联系进行计算)进行训练 , 可以极大减少训练计算量以匹配性能 , 提升样本效率 , 高效地筛选出低质量训练数据集 。
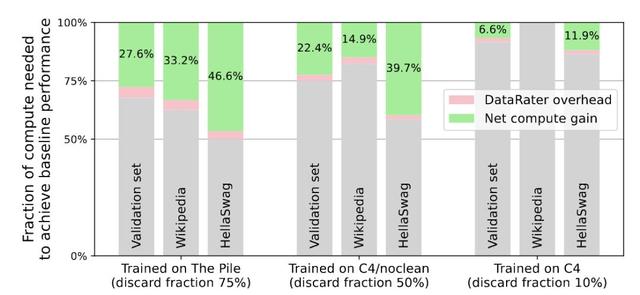
实验表明 , 经过DataRater筛选的数据大幅减少了训练所需的浮点运算次数(最高可达46.6%的净计算收益) , 并且可以提高跨多种预训练语料库(例如 , Pile、C4/noclean)语言模型的最终性能 。
在性能分析上 , DataRater也能够学会识别并降低「符合人类对低质量数据直觉」的数据权重 , 比如文本编码错误、OCR错误或者无关内容等 。
最重要的是 , 使用固定规模内部模型(4亿参数)进行元训练的DataRater模型 , 能够有效地将其学到的数据估值策略泛化 , 以对更大规模模型(5000万到10亿参数)的训练也同样有效 , 并且最佳数据丢弃比例也是一致的 。
数据质量评估器DataRater 过滤问题假设我们的训练目标是开发一个预测器 , 可以根据输入数据做出预测 , 对于大语言模型来说 , 输入数据是一组token序列 , 比如一段文本 。
构造训练集后 , 需要定义一个「损失函数」来衡量其在该数据集上预测的准确性;
在另一个不同分布的测试集上 , 可能需要定义一个新的损失函数来评估其性能 。
学习算法会从训练集中随机选取一批数据 , 然后根据这些数据来更新模型参数 , 经过多次迭代后 , 模型参数最终确定下来 。
【75%预训练数据都能删,Jeff Dean新作:全自动筛除低质量数据】模型在该测试集上的表现 , 可以用来衡量算法性能 。
过滤过程的目标是从训练集中找到最合适的子集 , 使得最终模型在测试集上的误差最小 。
因为学习算法通常无法找到最优的参数 , 所以在精心挑选的数据子集上训练速度会更快 。
DataRater算法研究人员采用了一种连续的松弛方法 , 用三步来选择要保留哪些数据:
1. 在每一步的梯度计算中 , 决定哪些数据点要包括进去 , 类似于给每个数据点分配一个「重要性」权重;
2. 将「重要性」权重从二进制(选/不?。 ┍湮闹担ǚ段Т?到1) , 可以用来做梯度加权 , 同时确保每个批次中所有权重的总和为1 , 以保持梯度的规模不变 。
3. 用一个评分函数来表示权重 , 无需为每个数据点单独列出一个权重 , 其中评分函数会根据每个数据点的价值来给出一个分数 , 然后通过softmax函数将分数转化为归一化的权重 。
在每一步 , DataRater会从训练集中随机选取一批数据 , 然后根据数据的权重来更新模型的参数 , 最终可以得到一个参数向量 。
为了优化过滤算法 , 算法的目标是找到一个评分函数的参数 , 使得最终模型在测试集上的预期误差最小 。
元优化研究人员采用元梯度方法 , 通过随机梯度法来大致优化参数:
计算损失函数(外层损失 , outer loss)相对于参数的梯度 , 其梯度通过反向传播经过多次针对模型参数的优化更新(内层损失 , inner loss)来计算 。
元学习目标:假设训练数据集和测试数据集具有相同的分布 , DataRater算法无需针对某个特定的下游任务进行优化 , 只需要最大化给定数据集的训练效率 。
数据评估的外层损失所依据的「保留数据」是「输入训练数据的一个不相交的子集」 , 其目标是「生成给定原始数据集的一个精选变体」 , 实现更快的学习效率 。
内层和外层损失具有相同的函数形式 , 即针对下一个token预测的交叉熵损失 。
研究人员使用non-causal Transformer来实现DataRater模型 , 基于元梯度下降法来优化其参数 。
实验结果为了评估DataRater在构造数据集方面的有效性 , 研究人员用三步方法进行评估:
1. 为指定输入数据集「元学习」出一个数据评分模型(DataRater);
2. 使用训练好的数据评分模型来构造测试集;
3. 从随机初始化开始 , 在构造的数据集上训练不同规模(5000万、1.5亿、4亿和10亿参数)的语言模型 , 随后评估其性能 。
语言模型和DataRater模型都基于Chinchilla架构 , 模型从随机初始化开始训练 , 遵循Chinchilla的训练协议和token预算 。
研究人员在C4、C4/noclean和Pile验证集以及英文维基百科上测量负对数似然(NLL)值 , 在HellaSwag、SIQA、PIQA、ARC Easy和Commonsense QA下游任务上测量准确率 。
达到10亿参数模型基线性能所需的计算量的比例 , 以在DataRater模型筛选后的数据集上达到最终基线性能所需的训练步数为指标
DataRater模型能否加速学习?对于像Pile和C4/noclean这样质量较差的数据集 , 节省了大量的浮点运算(FLOPS) 。
对于10亿参数的模型 , 下图展现了使用DataRater模型相比基线训练节省的计算量 , 包含了数据筛选过程的计算开销 。
10亿参数模型训练过程中的性能指标
结果表明 , 使用数据评分模型筛选后的数据集不仅加快了学习速度 , 还能提高模型的最终性能 。
元训练一个DataRater模型大约需要训练一个单个10亿参数的大型语言模型(LLM)所需的58.4%的浮点运算 。
不过 , DataRater模型筛选后的数据集可以用于训练更大规模的模型 , 可以分摊训练成本 。
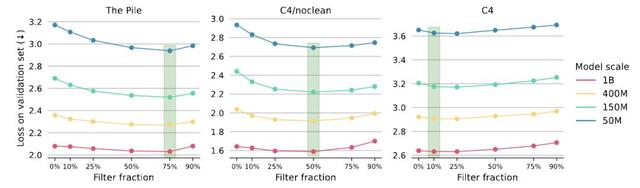
应该移除多少数据?为了确定每个数据集的最佳丢弃比例 , 研究人员测试了5种候选丢弃比例(10%、25%、50%、75%和90%) , 使用最小的模型(5000万参数) , 并选择了在验证集上负对数似然(NLL)表现最佳的丢弃比例 。
结果显示 , 使用最小尺寸模型是足够的 , 因为最佳丢弃比例在不同模型大小之间是共享的 。
最优值取决于底层数据的质量:对于C4 , 丢弃10%;对于C4/noclean , 丢弃50%;对于Pile , 丢弃75%
DataRater是否稳?。 ?研究人员为每个数据集训练了一个数据评分模型 , 内部模型尺寸固定为4亿参数 。
DataRater模型能够跨模型规模泛化:在对3个输入数据集、4种模型规模和7种指标的实验中 , 73/84个实验都展现出了性能提升 。
对于质量较低的数据集 , 如C4/noclean和Pile , 在NLL指标和HellaSwag任务上 , 性能提升在不同尺寸模型上是一致的 , 但在下游评估中的差异则更多 。
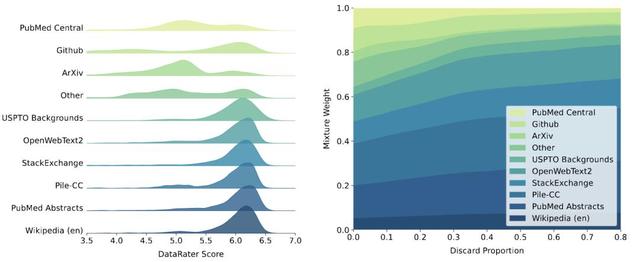
DataRater模型学到了什么?DataRater可以为不同的数据子集分配细致的评分 , 左长尾效应代表了「在很低丢弃比例下也仍然应该被丢弃的数据点」 。
随着丢弃比例的增加 , DataRater模型还学会了在混合层面上重新加权数据 。
DataRater模型能够识别低质量的数据 , 比如Pile数据集上被分配低评分的样本往往是低质量的 。
上图显示的例子中 , 错误的文本编码、光学字符识别(OCR)错误、大量空白符、非打印字符、高熵文本(如数字或字符串数据的列表和表格)以及私有SSH密钥、全大写的英文、多语言数据(Pile包含超过97%的英文数据)等都被识别出来了 。
参考资料https://x.com/fly51fly/status/1927120407796027465
推荐阅读














- 红米努力冲销量,7550mAh+金属中框低至1486元起,跑分可达240万
- 小米MIX Flip 2开启预约:搭载骁龙8至尊版 唯一满配旗舰小折叠
- REDMI两款新品预热:K80至尊版+旗舰小平板,主打豪华性能体验
- 搜索智能体RAG落地不佳?UIUC开源s3,仅需2.4k样本,训练快效果好
- 小米新机官方预热:搭载「玄戒O1」,即将发布
- 英特尔退役锐炫A770/750显卡:计划为新产品让路?
- 小米“续航王”突然变香了,1TB+7550mAh,冲上新机热销榜第一名
- 太菜,还得多练!苹果AI Siri预计推迟到2026年春季才发布
- 红米新机官方预热:6月份,即将发布
- 疯狂抢夺英伟达工程师!黄仁勋:不再将中国市场纳入业绩预测 业务被迫让给华为