
文章图片

文章图片
文章图片
文章图片
文章图片
苹果一篇论文 , 再遭打脸 。 研究员联手Claude Opus用一篇4页论文再反击 , 揭露实验设计漏洞 , 甚至指出部分测试无解却让模型「背锅」的华点 。
几天前 , 苹果怒斥大模型根本不会推理论文 , 引发全网无数讨论与争议 。
在许多人看来 , 没有站在AI前沿的人 ,却质疑当今最领先推理模型o3-mini、DeepSeek-R1推理能力 , 实在没有说服力 。
论文一出 , 备受质疑 。
一位研究员发文称 , 其研究方法并不可靠 , 比如通过在数学题中添加无关内容测试模型的表现 。
最近 , Open Philanthropy研究人员联手Anthropic发表的一篇论文——The Illusion of the Illusion of Thinking , 再次将矛头指向苹果 。
论文地址:https://arxiv.org/pdf/2506.09250
这篇仅4页论文一针见血 , 揭露了苹果论文在汉诺塔实验、自动评估框架 , 以及「过河」基准测试中的三大缺陷 。
甚至 , 文中还指出部分测试用例在数学上无解 , 模型却因此被误判为「推理失败」 。
更引人注目的是 , 论文作者之一 , 还有一个是AI——Claude Opus 。
论文中 , 具体指出了哪些问题 , 让我们一探究竟 。
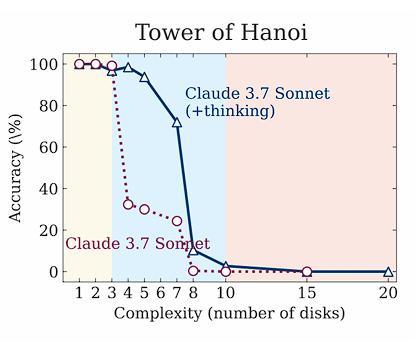
推理大模型失败 , 是非战之罪在The illusion of thinking中 , 作者给出了四个例子 , 说明当问题的尺度变大时 , 大模型的表现变得越来越差 。
他们据此得出结论:大模型实际上只是在进行着模式匹配 , 从训练数据集中找出对该问题的已有解答 。
汉诺塔问题示例
然而Lawsen和Claude指出上述研究中 , 推理大模型失败源头在于token数超过了模型的上限 。
例如 , 在汉诺塔的任务中 , 模型必须打印指数级数量的步骤——仅15个盘子就需要超过32000次移动 , 这导致它们达到输出上限 。
Sonnet 3.7的输出限制是128k , DeepSeek R1是64K , 以及o3-mini是100k token 。
这包括他们在输出最终答案之前使用的推理token , 所有模型在超过13个盘子的情况下都会出现0准确率 , 仅仅因为它们无法输出那么多!
不同大模型能够应对的汉诺塔盘子数 , 不考虑任何推理token , 大模型最大可解决规模为DeepSeek: 12个盘子 , Sonnet 3.7和o3-mini为13个盘子
在使用Claude测试时 , 作者观察到当问题规模过大时 , 它们甚至不会进行推理 , 而是会说 , 「由于移动次数众多 , 我将解释解决方案方法」 , 而不是逐一列出所有32767次移动 。
针对非常小的问题(大约5-6个盘子)的 , 大模型会进行推理 。
之后 , 它只是:重复问题 , 重复算法 , 打印步骤 , 然后到了9-10个盘子时 , 这时模型遇到了其输出的上限 , 这时 , 模型也许应该给出回复 , 「我写不下2^n_圆盘-1步 , 这超过了我的输出上限」 。
不同尺度的问题 , 大模型输出的token数在9-10个盘子时达到峰值
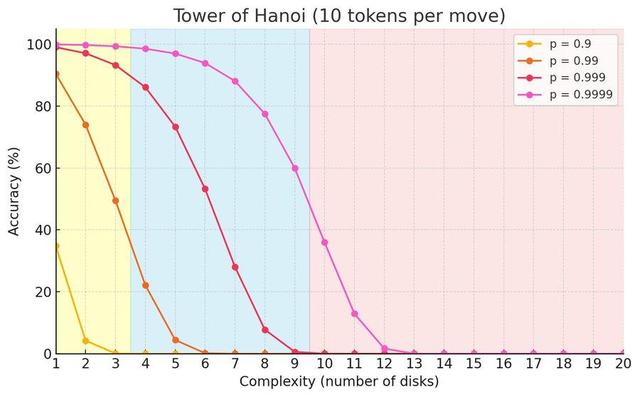
此外 , 大模型给出的解答之所以是错误的 , 可能的原因是在每一步推理过程中 , 大模型由于其是概念模型 , 会忘记之前选定的盘子 。
即使大模型每一步选对正确盘子的概率是99.99% , 当盘子数超过11%个时 , 大模型给出正确回答的概率 , 也会呈现指数衰减 。
这意味着即使大模型能够进行推理 , 但由于其在推理过程中 , 某汉诺塔盘顶的盘子编号从A记错成了B , 也会导致其给出的指令无法执行 。
而当前的评价要求大模型给出的回答完全没有错误 , 这样的评价标准 , 未免有些过于严苛了 。
大模型不同观察准确性下 , 随着问题复杂度增长其回答准确性的变化
至于The illusion of thinking文中列出的另一案例过河问题(River Crossing) , 当问题变为n=6时 , 问题在数学上就是无解的 , 这样的不可解的问题数目并不少 。 将大模型面对这些不可解问题的失败 , 当做大模型缺少推理能力的证据 , 这样做无疑是不妥的 。
除了指出The illusion of thinking中的评价缺陷 , 最新论文也指出对大模型推理能力对正确评价方法 。
即不是让大模型逐行编写每个步骤时 , 而是其给出一个Lua程序去解答问题 , 然后运行大模型给出的程序 , 再判断程序的输出否是正确的解答 。
结果显示 , Claude-3.7-Sonnet , Claude Opus 4 , OpenAIo3 , Google Gemini 2.5都能够在5000个token的限制下 , 输出能得到正确解答的程序 , 准确率极高 。
这完全消除了所谓的推理能力崩溃现象 , 表明模型并非未能进行推理 。 它们只是未能遵循一个人为的、过于严格的评分标准 。
LLM推理能力引热议苹果发布「思考的幻觉」论文的时间 , 恰逢WWDC之前 , 这进一步加剧了其影响力 , 使得其被广泛讨论 。
这其中就包含不少批评的声音 , 比如有人暗示苹果在大模型方面落后于OpenAI和谷歌等竞争对手 , 可能试图降低人们的期望 。
他们戏称 , 提出了一些关于「这一切都是假的 , 毫无意义」的研究 , 可以挽救苹果在Siri等表现不佳的AI产品上的声誉 。
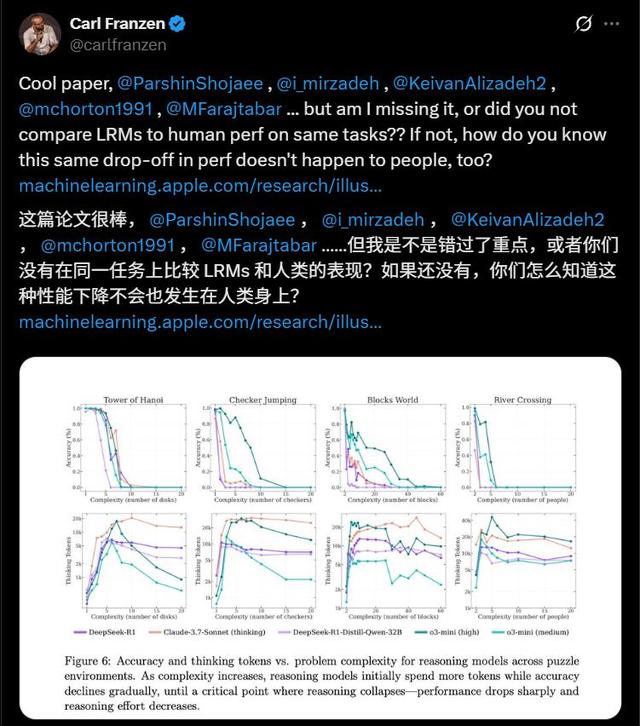
还有人批评道 , 即使是人类 , 也大多无法准确无误的写出针对13个盘子的汉诺塔问题的一步步解法 , 如果没有进行这样的比较 , 苹果又如何知道这样随着问题规模变大而遇到的准确性下降 , 不会出现在人类身上 。
而法国高效能AI初创公司Pleias的工程师Alexander Doria指出思考的幻觉一文略了细微差别 , 认为模型可能在学习部分启发式方法 , 而不是简单地匹配模式 。
而宾夕法尼亚大学沃顿商学院专注于人工智能的教授Ethan Mollick认为 , 认为大语言模型正在「遇到瓶颈」的观点为时过早 , 并将此比作那些未能应验的关于「模型崩溃」的类似主张 。
上述争议凸显了一个日益增长的共识:设计合理的大模型评估方案 , 如今与模型设计同等重要 。
要求大模型枚举每一步可能更多地考验它们的输出上限而非规划能力 , 而输出程序化答案或给予大模型外部临时工作区则能更清晰地展现其实际推理能力 。
该案例还突出了开发者在部署自主系统时面临的实际限制——上下文窗口、输出预算和任务表述可能决定或破坏用户可见的性能 。 对于在企业技术决策者构建基于推理大模型的应用而言 , 这场辩论不仅仅是学术性的 。 它提出了关于在生产工作流程中何时、何地以及如何信任这些模型的关键问题——尤其是在任务涉及长规划链或需要精确的逐步输出时 。
如果一个模型在处理复杂提示时看似「失败」 , 问题可能不在于其推理能力 , 而在于任务如何被构建、需要多少输出 , 或模型能访问多少内存 。 这对于构建如协作者、自主代理或决策支持系统等工具的产业尤其相关 , 在这些产业中 , 可解释性和任务复杂性都可能很高 。
理解上下文窗口、token预算以及评估中使用的评分标准对于可靠的系统设计至关重要 。 开发者可能需要考虑外部化内存、分块推理步骤或使用函数或代码等压缩输出 , 而不是完整的语言解释 。
更重要的是 , 这篇论文的争议提醒我们 , 基准测试与现实应用并不相同 。
企业团队应谨慎避免过度依赖那些不能反映实际应用场景的合成基准测试——或者那些无意中限制模型展示其能力的基准测试 。 对机器学习研究人员来说 , 一个重要的启示是:在宣称一个人工智能里程碑或讣告之前 , 务必确保测试本身没有将系统置于一个太小而无法思考的框框之中 。
参考资料https://arxiv.org/pdf/2506.09250
【Claude与人类共著论文,苹果再遭打脸,实验黑幕曝光】https://lawsen.substack.com/p/when-your-joke-paper-goes-viral
推荐阅读













- 三星电子寻求与中国企业合作 降低OLED面板成本
- 消息称亚马逊云计算部门将与SK联手 在蔚山打造韩国最大AI数据中心
- BOOST电路设计与工作原理讲解
- 红米K80至尊版突然官宣:与K Pad一起来袭,配置规格基本没悬念
- REDMI K Pad图赏:质感与便携兼得,全金属机身×窄边设计
- 影像与性能的双重巅峰:OPPOFindX8Ultra,带来专业的拍摄体验!
- 大唐电信小米将在德国“对簿公堂”,涉及3项4G与5G标准相关专利
- 配色与手感双满分,vivo S30 Pro mini带来小屏魅力之美
- x86-64 CPU架构版本划分与历史演进全解析\uD83C\uDF1F
- 小米16 Pro与红米K90 Pro:屏幕再次被敲定,配置规格也悬念不大了