
文章图片
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
共同第一作者包括:陈家棋 , 斯坦福大学访问学者 , 复旦大学硕士 , 研究方向为 LLM Agent和大一统模型;朱小烨 , 华南理工大学本科 , 研究方向为 LLM Agent、LLM 和强化学习;王越 , 康奈尔大学本科 , 研究方向为 LLM Agent、多模态语言模型 。 指导老师:Julian McAuley(UCSD)、Li-jia Li (IEEE Fellow LiveX AI) 。
在人工智能内容创作蓬勃发展的今天 , 跨模态生成技术正在重塑艺术创作和视觉表达的边界 。 人们对需求也日趋复杂和多样 , 譬如将静态照片转化为动态视频并叠加环境音效 , 打造沉浸式的多感官体验 。 然而 , 现有生成系统大多受限于训练数据的覆盖范围 , 或是因复杂的多模型协调而效率低下 , 难以满足这些日益增长的创意需求 。
问题背景
图 1 用于 Any-to-Any 生成任务的一种符号化描述方法 。
「将丛林的狂野生长与古老废墟的神秘感融合成一个全新的场景 , 一定会令人惊叹 , 」你的艺术家朋友沉思道 。 「如果还能把这张照片转换成视频 , 再叠加上鸟鸣声和潺潺流水声——那将营造出一种梦幻般的感官体验 。 」这些日益复杂、跨模态的创作需求指向了一个根本性挑战:如何设计一个统一模型 , 能够根据自然语言指令 , 无缝处理任意输入与输出模态组合的生成任务?这样的任务就是该研究关注的「Any-to-Any」生成任务 , 如图 2 所示 。
图 2 Any-to-Any 生成任务
当前 Any-to-Any 生成任务的方法主要分为隐式神经建模和智能体方法 。 隐式神经建模需要大量数据训练 , 虽然能处理常见任务 , 但对新场景适应能力差且生成过程不可控;智能体方法虽然功能灵活但结构复杂 , 运行不稳定且效率较低 。 此外 , 如果人类设计师用 PS 合成图像时 , 需要先背诵所有滤镜组合公式才能操作 , 还有创意可言吗?当前许多方法陷入了这种「知识依赖陷阱」——而真正的 Any-to-Any 生成 , 应该像儿童搭积木:不需要理解木块分子结构 , 只需知道它们如何拼接 。
于是 , 研究团队设想构建一个框架:聚焦于统一的任务表示和语言模型友好的接口 , 从而实现直接的任务指定 。 使系统能够真正理解并执行用户以自然语言描述的任意生成需求 , 同时保持执行过程的可控性和可干预性 。 这一设想从根本上改变了传统生成模型的实现范式 , 为构建真正意义上的 Any-to-Any 生成系统提供了新的技术路线 。
基于符号化表征的生成任务描述框架
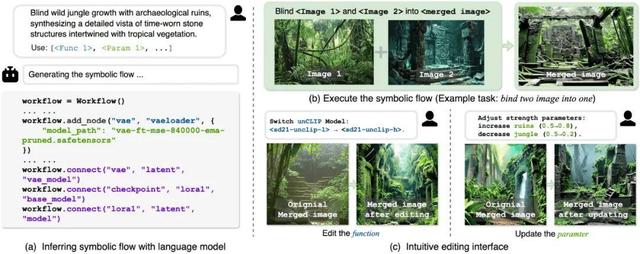
框架设计的核心思路在于对生成任务本质的解构:任何复杂的多模态生成过程 , 本质上都可以拆解为「做什么」(函数)、「怎么做」(参数)和「执行顺序」(拓扑)三个要素 。 基于这样的见解 , 研究提出了 -Language , 这是一种正式表示方法 , 系统地捕捉生成任务的这三个基本组成部分 。 此外 , 研究还介绍了一种无需训练的推理引擎 , 它利用预训练的语言模型作为基础 , 从输入指令和指定的关键函数中得出符号表示 。
图 3 语法风格比较 。
- 基于预训练语言模型的符号化流程推断为使方法灵活而稳健地适应生成任务的多样性和复杂性 , 该研究将高层次的任务描述转化为可执行的符号化流程 。 如图 4 所示 , 提出利用语言模型 (LM) 作为推理引擎 , 从输入指令和指定的关键函数中得出符号表示 。
图 4 利用语言模型 (LM) 生成符号化表示 。
通过三阶段处理实现这一目标:组件推断阶段由语言模型解析任务描述 , 识别所需的函数 (F) 和参数 (Φ);拓扑构建阶段基于输入输出关系 , 建立函数间的数据流连接 (T);迭代优化阶段通过错误反馈循环 (R) 持续修正流程 , 直至满足所有约束条件 (C) 。 图 5 完整展示了从自然语言描述到可执行工作流程的转换过程 , 从而实现了跨模态和跨任务类型的任意转换 。
图 5 推理和执行的演示 。
实验结果
在实验中 , 该研究构建了一个包含 120 个真实世界生成案例的数据集 , 涵盖 12 个任务类别 , 并通过用户研究和可执行性评估验证了方法的有效性 。
- 跨模态生成质量评估(用户研究)
- 复杂工作流执行测试(ComfyBench 基准)
- 消融实验
- 对比实验:符号化 v.s. 代理化方法
- 表示方法本质研究
- 显式流程编辑与错误分析
总结
【CVPR 2025 多模态大一统:斯坦福 x 复旦提出符号主义建模生成式任务】该研究提出的符号化生成任务描述语言及配套推理引擎 , 为多模态任务提供了一种无需专门训练的全新高效解决方案 。 通过利用预训练大语言模型将自然语言指令直接转化为符号化工作流 , 该方法成功实现了 12 类跨模态生成任务的灵活合成 。 实验证明 , 该框架不仅在生成内容质量上媲美现有的先进统一模型 , 更在效率、可编辑性和可中断性等方面展现出显著优势 。 符号化任务表示方法或许能为提升生成式 AI 能力提供一条经济高效且可扩展的技术路径 。
推荐阅读









- 卡莱特惊艳亮相Infocomm USA 2025:焕新视觉体验!
- 618必入产品,2025夏季焦点产品计划重磅发布
- 2025Q1 600美元以上高端手机市场格局:苹果稳居榜首 华为强势回归
- 当芯片遇上AI,TSS2025集邦咨询半导体产业高层论坛干货分享
- CVPR 2025 | 多模态统一学习新范式来了,数据、模型、代码全部开源
- IGN公布2025年度五大显卡推荐,N卡仅两款上榜
- SIGGRAPH 2025奖项出炉:上科大、厦大入选最佳论文
- 西部数据亮相 IDCE 2025 ,全矩阵数据中心产品引领存储“底座”革新
- 新买的华为手机,一定要完成这4步设置,手机能多用好几年!
- 这么多年了,为什么台式机还处于组装(DIY)阶段?