
文章图片
文章图片
在大语言模型蓬勃发展的背景下 , Transformer 架构依然是不可替代的核心组件 。 尽管其自注意力机制存在计算复杂度为二次方的问题 , 成为众多研究试图突破的重点 , 但 Transformer 在推理时灵活建模长距离上下文的能力 , 使得许多线性复杂度的替代方案(如 RNN、Linear Attention、SSM 等)难以真正取代它的地位 。
尤其是在大语言模型广泛采用 decoder-only 架构之后 , 自注意力机制的重要性进一步凸显 。 然而 , 这种机制也带来新的挑战:推理过程中每一步都需要访问 Key-Value(KV)缓存 , 该缓存的大小随着生成序列长度线性增长 , 逐渐成为影响推理效率的关键瓶颈 。 随着模型参数维度不断扩大 , KV 缓存所需的显存和带宽开销显著上升 , 限制了模型的推理长度与可支持的 batch size 。
值得一提的是 , 近期由 DeepSeek 团队提出的 MLA 机制 , 通过在隐空间维度对 KV 缓存进行压缩 , 显著提升了推理效率 , 推动了大模型在低资源场景下的高效部署 。 但随着生成序列的持续增长 , 时间维度的冗余信息也逐渐暴露 , 压缩其所带来的潜力亟待挖掘 。 然而 , 如何在保持性能的前提下压缩时间维度 , 一直受到增量式推理复杂性的限制 。
为此 , 剑桥大学机器智能实验室最新提出了 Multi-head Temporal Latent Attention(MTLA) , 首次将时序压缩与隐空间压缩相结合 , 在 KV 缓存的两个维度上同时施加时空压缩策略 。 MTLA 利用超网络动态融合相邻时间步的信息 , 并设计了步幅感知的因果掩码以确保训练与推理的一致性 , 在显著降低推理显存与计算成本的同时 , 保持甚至略优于传统注意力机制的模型性能 , 为大语言模型推理效率的提升提供了新的解决思路 。
- 论文标题:Multi-head Temporal Latent Attention
- 论文地址:https://arxiv.org/pdf/2505.13544
- 项目地址:https://github.com/D-Keqi/mtla
在构建大语言模型时 , KV 缓存带来的显存与计算开销问题早已受到广泛关注 。 当前主流的大模型通常采用基于自注意力的 Grouped-Query Attention(GQA)机制 , 对标准 Transformer 中的 Multi-Head Attention(MHA)进行改进 。 GQA 通过减少 Key/Value 头的数量来减小 KV 缓存的规模 , 具体做法是将多个 Query 头分组 , 每组共享同一个 KV 头 。
当 GQA 的组数等于 Query 头数量时 , 其等价于标准 MHA;而当组数为 1 时 , 即所有 Query 头共享同一组 KV , 这种极端形式被称为 Multi-Query Attention(MQA) 。 虽然 MQA 极大地减少了显存占用 , 但显著影响模型性能;相比之下 , GQA 在效率与效果之间取得了更好的平衡 , 因此成为当前大语言模型中最常见的注意力变体 。
与此不同 , DeepSeek 团队提出的 Multi-head Latent Attention(MLA)采用了另一种思路:不减少头的数量 , 而是在隐空间中压缩 KV 的特征维度 。 实验结果表明 , MLA 相较于 GQA 表现出更优的性能与效率 。 然而 , 这种压缩方式仍存在上限 , 为了维持模型性能 , 隐空间维度的压缩幅度不能过大 , 因此 KV 缓存的存储开销依然是限制模型推理效率的一大瓶颈 。
除了在隐空间对 KV 缓存进行压缩之外 , 时间维度也是一个极具潜力但尚未充分挖掘的方向 。 随着生成序列变得越来越长 , KV 缓存中在时间轴上的信息冗余也日益明显 。 然而 , 由于自注意力机制在生成时通常采用自回归的增量推理模式 , KV 缓存与每一个生成的 token 是一一对应的 , 这使得在保持模型性能的前提下压缩时间维度成为一项挑战 , 也导致了该方向长期缺乏有效解决方案 。
MTLA 的提出正是对这一空白的回应 。 它通过引入时间压缩机制和步幅感知的因果掩码 , 巧妙解决了训练与推理行为不一致的问题 , 在保持高效并行训练能力的同时 , 实现了推理过程中的 KV 时间压缩 。 进一步地 , MTLA 还结合了 MLA 的隐空间压缩策略 , 从空间与时间两个维度同时优化 KV 缓存的表示 , 将自注意力机制的效率推向了新的高度 。
MTLA 的核心技术与训练策略
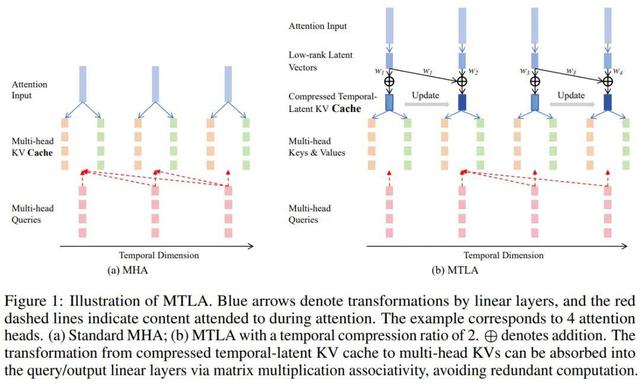
在增量推理阶段 , MTLA 会对经过隐空间压缩后的 KV 缓存进行时间维度的增量式合并 , 进一步压缩存储空间 。 上图展示了该过程的示意 , 并与标准的 MHA 进行了对比 。
以时间压缩率 s=2 为例 , 每两个相邻的 KV 缓存将合并为一个 。 在生成第一个字符时 , KV 缓存长度为 1;生成第二个字符后 , 新生成的 KV 与前一个被合并 , KV 缓存长度仍然保持为 1 。 这种动态合并机制有效压缩了时间维度上的冗余信息 。
然而 , 这也带来了并行训练上的挑战:虽然两个时间步的 KV 缓存长度相同 , 但它们所包含的信息不同 , 若不加以区分 , 容易导致训练与推理行为不一致 。
【时空压缩!剑桥大学注意力机制MTLA:推理加速5倍,显存减至1/8】MTLA 通过一种优雅的方式解决了这一问题 。 正如下图所示 , 在训练阶段 , MTLA 保留了所有中间状态的 KV 表达 , 并引入了步幅感知因果掩码(stride-aware causal mask) , 确保每个 query 在训练时访问到与推理阶段一致的 KV 区域 , 从而准确模拟增量推理中的注意力行为 。
得益于这一设计 , MTLA 能够像标准注意力机制一样通过矩阵乘法实现高效并行计算 , 在保持训练效率的同时完成对时间维度的压缩 。
此外 , MTLA 还引入了解耦的旋转位置编码(decoupled RoPE)来建模位置信息 , 并对其进行了时间维度上的压缩 , 进一步提升了整体效率 。
值得强调的是 , MTLA 不仅是一种更高效的自注意力机制 , 它还具备极强的灵活性与可调性 。 例如 , 当将时间压缩率 s 设置得足够大时 , MTLA 在推理过程中几乎只保留一个 KV 缓存 , 这种形式本质上就退化为一种线性序列建模方法 。 换句话说 , 线性序列建模可以被视为 MTLA 的极端情况 , MTLA 在注意力机制与线性模型之间架起了一座桥梁 。
然而 , 在许多复杂任务中 , 传统注意力机制所具备的二次计算复杂度虽然代价高昂 , 却提供了更强的建模能力 。 因此 , MTLA 所引入的 “可调时间压缩率 s” 这一设计思路 , 恰恰为模型提供了一个在效率与性能之间灵活权衡的可能空间 。
MTLA 的卓越性能
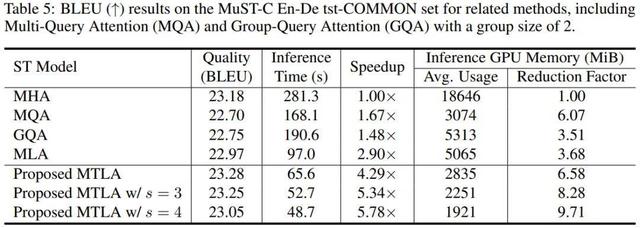
MTLA 在一系列任务中展现了出色的性能 , 包括语音翻译 , 文本摘要生成 , 语音识别和口语理解 。 例如在语音翻译中 , MTLA 在保持与标准 MHA 相当的翻译质量的同时 , 实现了超过 5 倍的推理速度提升 , 并将推理过程中的 GPU 显存占用降低了超过 8 倍 。
值得注意的是 , 仅当时间压缩率 s=2 时 , MTLA 对 KV 缓存的压缩程度就已经与 MQA 相当 , 且在模型性能上更具优势 。 而相比之下 , MQA 所采用的减少 KV 头数量的方法已达上限 , 而 MTLA 还有进一步的空间 。
未来发展
MTLA 具备在大规模场景中部署的显著潜力 , 尤其是在大语言模型参数规模不断扩大、以及思维链等技术推动下生成序列日益增长的背景下 , 对 KV 缓存进行时空压缩正是缓解推理开销的关键手段 。 在这样的趋势下 , MTLA 有望成为未来大语言模型中自注意力模块的重要替代方案 。
当然 , 与 DeepSeek 提出的 MLA 类似 , MTLA 相较于 GQA 和 MQA , 在工程落地方面的改动不再是简单的一两行代码可以实现的优化 。 这也意味着要将其大规模应用到现有 LLM 框架中 , 还需要来自社区的持续推动与协同开发 。
为促进这一过程 , MTLA 的实现代码已全面开源 , 希望能够为研究者与工程实践者提供便利 , 共同推动高效注意力机制在大模型时代的落地与普及 。
推荐阅读














- 不止实时翻译,时空壶用L1-L5分级,揭示AI同传的未来
- 影视飓风“开炮”视频下架,“画质压缩”事件平台冤不冤?
- 动了谁的奶酪 “揭露各平台压缩视频画质”的视频为何全网下架?
- 看了网飞的1080P才知道什么叫做真正的高清视频,无锐化无压缩
- 格力空调e1是什么故障
- 冰箱发出响声是怎么回事
- 冷藏柜噪音大是什么原因
- 压缩面膜敷多久效果最好,压缩面膜怎么用?
- 压缩机工作原理是什么,压缩机工作原理
- 时空伴随是绿码就不用隔离吗,时空伴随者需要隔离14天吗 时空伴随者黄码几天可以变绿码