文章图片

文章图片
文章图片
随着大模型的迅猛发展 , 混合专家(MoE)模型凭借其独特的架构优势 , 成为扩展模型能力的重要方向 。 MoE通过创新性的路由机制 , 动态地将输入token分配给不同的专家网络 , 不仅高效实现了模型参数的规模化扩展 , 更在处理复杂任务时展现出显著优势 。 然而 , 将MoE模型在分布式集群环境下进行训练时 , 训练效率不足 , 已成为亟待解决的难题 。
MoE大规模训练难题:一半以上的训练时间在等待?实践表明 , MoE模型训练集群的效率面临两方面挑战:(1)专家并行引入计算和通信等待 , 当模型规模较大时 , 需要切分专家到不同设备形成并行(EP) , 这就引入额外All-to-All通信 , 同时MoE层绝大部分EP通信与计算存在时序依赖关系 , 一般的串行执行模式会导致大量计算单元空闲 , 等待通信;(2)负载不均引入计算和计算等待 , MOE算法核心是“有能者居之” , 在训练过程中会出现部分热专家被频繁调用 , 而冷专家使用率较低;同时 , 真实训练数据的长度不一 , 不同的模型层(如稀疏层、嵌入层等)的计算量也存在明显差异 , 造成不同卡之间计算也在互相等待 。
形象地说 , MoE训练系统就像一个交通拥塞严重的城区:1)人车混行阻塞 , 所有车辆(计算)必须等待行人(通信)完全通过斑马线才能通行 , 造成大量无效等待;2)车道分配僵化 , 固定划分的直行、左转车道就像静态的专家分配 , 导致热门车道(热专家)大排长龙 , 而冷门车道(冷专家)闲置 。 为此 , 华为团队构建了一套叫做Adaptive PipeEDPB的优化方案 , 就像一个“上帝视角的智慧枢纽” , 让MoE训练集群这个“城市交通”实现无等待的流畅运行 。
DeployMind仿真平台 , 小时级自动并行寻优
华为构建了名为AutoDeploy的仿真平台 , 它是一个基于昇腾硬件训练系统的“数字孪生”平台 , 通过计算/通信/内存三维度的多层级建模、昇腾硬件系统的高精度映射、全局化算法加速运行等技术 , 能在1小时内模拟百万次训练场景 , 实现MoE模型多样化训练负载的快速分析和自动找到与集群硬件规格匹配的最优策略选择 。 在训练实践验证中 , 该建模框架可达到90%精度指标 , 实现低成本且高效的最优并行选择 。
针对Pangu Ultra MoE 718B模型 , 在单卡内存使用约束下 , 华为通过AutoDeploy以训练性能为目标找到了TP8/PP16/VPP2/EP32(其中TP只作用于Attention) , 这一最适合昇腾集群硬件规格的并行方案 , 综合实现计算、通信、内存的最佳平衡 。
Adaptive Pipe通信掩盖98% , 让计算不再等待通信
华为构建了一套称为Adaptive Pipe的通信掩盖框架 , 在AutoDeploy仿真平台自动求解最优并行的基础上 , 采用层次化All-to-All降低机间通信和自适应细粒度前反向掩盖 , 实现通信几乎“零暴露” 。
层次化专家并行通信 。 针对不同服务器之间通信带宽低 , 但机内通信带宽高的特点 , 华为创新地将通信过程拆成了两步走:第一步 , 让各个机器上“位置相同”的计算单元联手 , 快速地从所有机器上收集完整的数据块(Token);第二步 , 每台机器内部先对数据块进行整理 , 然后利用机器内部的高速通道 , 快速完成互相交换 。 这种分层设计的巧妙之处在于 , 它把每个数据块最多的复制分发操作都限制在单台机器内部的高速网络上完成 , 而在跨机器传输时 , 每个数据块只需要发送一份拷贝 , 相比传统All-to-All通信加速1倍 。
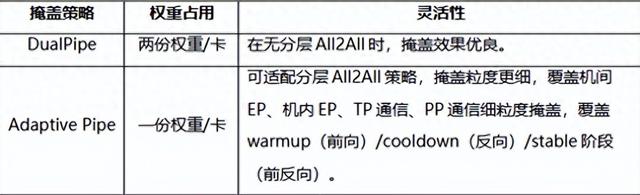
自适应细粒度前反向掩盖 。 在DualPipe掩盖框架的基础上 , 华为基于虚拟流水线并行技术 , 实现了更精密的调度 , Adaptive Pipe(图1) 。 相比DualPipe , Adaptive Pipe仅利用一份权重 , 不仅将流水线并行所需的内存占用减半 , 有效降低了计算“空泡” , 释放了流水线的峰值性能潜力;同时 , 该策略能够额外实现与分层通信的完美协同 , 无缝覆盖机间与机内两层通信的掩盖 。 在这种层次化通信和细粒度计算通信切分调度优化下 , Adaptive Pipe可实现98%以上的EP通信掩盖 , 让计算引擎不受通信等待的束缚 。
图1 :自适应细粒度前反向掩盖方案:(a) warmup阶段纯前向;(b) cooldown阶段纯反向;(c) stable阶段前反向掩盖;第一行为计算算子 , 第二行为机内EP通信 , 第三行为机间EP通信;F代表前向算子 , B代表反向算子 , R代表重计算算子 , PP P2P代表stage间的P2P通信 。
EDPB全局负载均衡 , 让计算之间不再互相等待 , 训练再加速25%在最优并行和通信掩盖基础上 , 由于MoE模型训练过程中天然存在的负载不均问题 , 集群训练效率时高时低 。 华为团队创新性地提出了EDPB全局负载均衡 , 实现专家均衡调度(图2) , 在最优并行和通信掩盖基础上 , 再取得了25.5%的吞吐提升收益 。
图2:集群P2P通信分析对比
专家预测动态迁移(E) 。 MoE模型训练中 , 设备间的专家负载不均衡如同“跷跷板”——部分设备满载运行 , 另一些却处于“半休眠”状态 。 团队提出了基于多目标优化的专家动态迁移技术 , 让专家在分布式设备间“智能流动” 。 该技术主要有三个特点:
· 预测先行:让专家负载“看得见未来”:预测负载趋势 , 实现“计算零存储开销 , 预测毫秒级响应”;
· 双层优化:计算与通信的黄金分割点:提出节点-设备双层贪心优化架构 , 在让计算资源“齐步走”的同时 , 给通信链路“减负”;
· 智能触发:给专家迁移装上“红绿灯”:设计分层迁移阈值机制 , 通过预评估迁移收益动态决策 , 实现专家迁移的智能触发 。
图3:基于专家动态迁移的EP间负载均衡整体框架图
数据重排Attention计算均衡(D) 。 在模型预训练中普遍采用数据拼接固定长度的策略 , 但跨数据的稀疏Attention计算量差异显著 , 会引入负载不均衡问题 , 导致DP间出现“快等慢”的资源浪费 。 为解决这一问题 , 华为团队提出了一种精度无损的动态数据重排方案 , 其核心在于:通过线性模型量化单样本计算耗时 , 在严格保持训练精度无损下 , 批次内采用贪心算法构建最小化耗时的数据重排 , 实现负载均衡 。
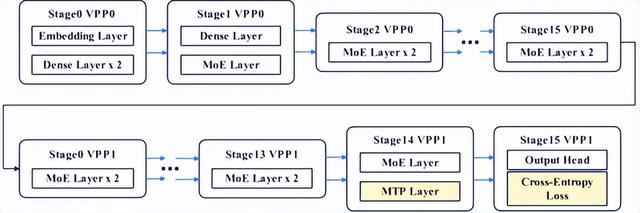
虚拟流水线层间负载均衡(P) 。 MoE模型通常采用混合结构 , Dense层、MTP层、输出层所在的Stage与纯MoE层所在的Stage负载不均 , 会造成的Stage间等待 。 团队提出虚拟流水线层间负载均衡技术 , 将MTP层与输出层分离 , 同时将MTP Layer的 Embedding计算前移至首个Stage , 有效规避Stage间等待问题 , 实现负载均衡 。
图4:基于异构模块设计的VPP并行负载均衡
整体系统收益回到最开始提到的城市交通场景 , Adaptive PipeEDPB这套方案 , 形象的说就是创新性地引入智慧化交通设施:首先 , 建造\"行人地下通道\"(通信掩盖) , 彻底分离人车动线 , 使车辆(计算)无需等待即可持续通行 , 行人(通信)在底层独立穿行;其次 , 部署\"智能可变车道\"(动态专家迁移) , 根据实时车流(数据分布)动态调整车道功能 , 让闲置的左转车道也能分担直行压力 , 实现负载均衡 , 整体让城市交通实现无堵车流畅运行 。
在Pangu Ultra MoE 718B模型的训练实践中 , 华为团队在8K序列上测试了Adaptive PipeEDPB吞吐收益情况 , 在最优并行策略的初始性能基础上 , 实现了系统端到端72.6%的训练吞吐提升 。
【上帝视角的昇腾MoE训练智能交通系统让训练效率提升70%】
推荐阅读















- SSM+扩散模型,竟造出一种全新的「视频世界模型」
- AI拒绝机是人类自找的,因为算法有时候也会「自私」
- 高通的Centriq 2400和Falkor架构
- 国产手机这些新技术,让我感觉iPhone17真的不香了
- 老人机≠低配机!讲个道理,你真的低估老年人的用机习惯
- 看似无害的提问偷走RAG记忆,IKEA:隐蔽高效数据提取攻击新范式
- 轻薄全能旗舰vivo S30,这个夏天最酷的科技潮品
- 即将发布的5款新机,每一款都很有看点!你最期待哪一款?
- vivo S30 Pro mini影像深度测评:氛围感直出的艺术
- 原来 2124 元也能有提升幸福感的好手机