
文章图片

文章图片
文章图片
文章图片

文章图片

机器之心发布
机器之心编辑部
你是否注意到 , 现在的 AI 越来越 \"聪明\" 了?能写小说、做翻译、甚至帮医生看 CT 片 , 这些能力背后离不开一个默默工作的 \"超级大脑工厂\"——AI 算力集群 。
随着人工智能从简单规则判断进化到能处理万亿参数的大模型 , 单台计算机的算力就像小舢板面对汪洋大海 , 而算力集群则是把上万台甚至几十万台计算机像搭积木一样连接起来 , 形成一艘能承载巨量计算任务的 \"算力航空母舰\" 。
当我们把上万台计算机整合成一个有机整体时 , 需要解决一系列世界级难题:如何让它们像精密钟表一样协同工作?如何在部分设备故障时依然保持高效运行?如何快速修复大规模训练中的中断问题?
接下来我们将逐一揭秘这些支撑 AI 算力集群的关键特性 , 看看华为团队如何用工程智慧驯服这头算力巨兽 。
技术报告地址:https://gitcode.com/ascend-tribe/ascend-cluster-infra/blob/main/Overview/%E6%98%87%E8%85%BE%E9%9B%86%E7%BE%A4%E5%9F%BA%E7%A1%80%E8%AE%BE%E6%96%BD%E7%BB%BC%E8%BF%B0.pdf
超节点高可用
24 小时不停工的智能工厂
就像医院的急诊系统必须时刻在线 , AI 训练和推理也不能轻易中断 。 算力集群里每台计算机都有 \"备用替身\" , 当某台机器出现故障(比如突然断电或硬件损坏) , 系统会立刻启动备用机接管任务 , 就像接力赛中接力棒无缝传递 , 确保自动驾驶训练、语音识别等任务持续运行 , 不会因为个别设备故障而全盘停止 。
针对 CloudMatrix 384 超节点 , 华为团队提出面向整个超节点的故障容错方案 , 分为 “系统层容错”、“业务层容错” , 以及后续 “运维层容错” , 核心思想就是 将故障问题转为亚健康问题 , 通过运维手段优雅消除:
(1) 系统层容错:通过超时代答欺骗 OS + 网络路由切换 , 防系统蓝屏 , 同时避免整个超节点级故障 。
(2) 业务层容错:租户无感知下 , 通过重试容忍网络闪断 , 将系统故障转为亚健康 ,
(3) 运维层容错:主要构筑亚健康感知和优雅恢复技术 , 通过主动方式将消减亚健康事件影响 。
集群线性度:人多力量大的完美协作
理想情况下 , 100 台计算机的算力应该是 1 台的 100 倍 , 1000 台就是 1000 倍 , 这就是 \"线性度\" 。 算力集群通过精密的任务分配算法 , 让每台计算机都像 orchestra(交响乐团)的乐手一样各司其职 , 避免出现 \"三台和尚没水喝\" 的混乱 。 比如训练一个需要万亿次计算的模型时 , 万台计算机能像整齐划一地划桨的龙舟队 , 让算力随规模增长而几乎同步提升 。
华为团队提出拓扑感知的协同编排技术 TACO、网络级网存算融合技术 NSF、拓扑感知的层次化集合通信技术 NB、无侵入通信跨层测量与诊断技术 AICT 等四项关键技术 , 实现盘古模型训练线性度提升 。
实验及理论分析结果显示 , 训练Pangu Ultra 135B 稠密模型时 , 4K 卡 Atlas 800T A2 集群相比 256 卡基线 , 线性度为 96% 。 训练Pangu Ultra MoE 718B 稀疏模型时 , 8K 卡 Atlas 800T A2 集群相比 512 卡基线 , 线性度 95.05%;4K 卡 CloudMatrix 384 集群相比 256 卡基线 , 线性度 96.48% 。
万卡集群训练快速恢复
带 \"存档功能\" 的训练师
当用上万个计算单元(俗称 \"万卡\")训练超大规模模型时 , 偶尔有几台机器 \"罢工\" 是难免的 。 这时系统会像游戏存档一样 , 自动记录最近的训练进度 。 一旦检测到故障 , 能快速定位出问题的计算单元 , 跳过故障部分 , 从最新的存档点继续训练 , 避免从头再来的巨大浪费 。 比如训练一个需要 30 天的模型 , 即使中间有设备故障 , 也能在几分钟内恢复进度 , 就像视频播放可以随时续播 。
为了使万卡集群训练可以达到分钟级快恢 , 华为团队提出了以下多个创新:
(1) 进程级重调度恢复:正常节点通过参数面网络将临终 CKPT 传递到备用节点上 , 完成参数状态恢复后继续训练 , 能够有效缩短训练恢复时间到 3min 以内 。
(2) 进程级在线恢复:针对硬件 UCE 故障 , 通过业务面昇腾 CANN 软件、框架软件、MindCluster 软件配合实现故障地址在线修复 , 进一步缩短训练恢复时间到 30s 以内 。
(3) 算子级在线恢复:针对 CloudMatrix 384 产品 HCCS 网络、ROCE 参数面网络提供 HCCL 算子重试能力 , 容忍更长时间的网络异常 , 实现网络故障影响的通信算子秒级重执行 , 训练任务不中断 。
超大规模 MoE 模型推理分钟级恢复
各路英豪来帮忙
随着千亿 MOE 模型架构演进 , 实例部署的组网架构从传统的一机八卡演进为大 EP 组网架构 , 将多且小的专家部署在多个服务器节点上缓解显存带宽压力 , 目前在大 EP 组网架构下主要面临部署规模扩大导致的故障概率数量增大、故障爆炸半径变大的可靠性问题 , 任意硬件故障都会导致整个 Decode 实例不可用 , 进而导致推理业务受损 , 甚至中断 。
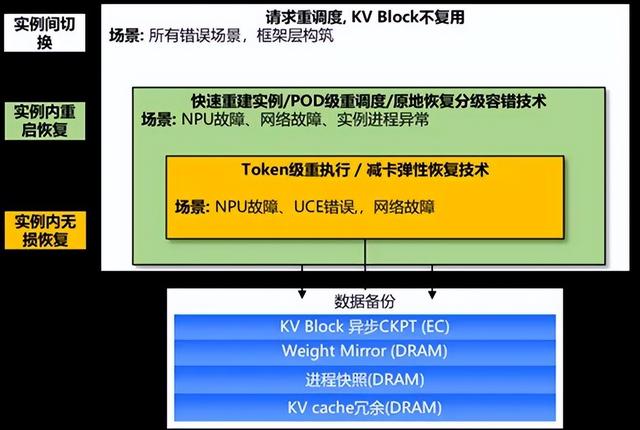
针对当前超大规模 MoE 模型带来的大 EP 推理架构的可靠性难题 , 华为提出三级容错方案 , 实例间切换、实例内重启恢复、实例内无损恢复 , 从硬件驱动层、框架层、平台层相互协作 , 构筑端到端可靠性体系 。 在不同的故障场景下 , 采用不同的容错恢复手段 , 可以最小化用户损失 。
(1) 实例内快速重启恢复技术:根据实际环境测试验证 , 该技术将实例恢复时间从 20min 降低 5min 。
(2) TOKEN 级重试:基于 DeepSeekV3 在 CloudMatrix 384 超节点场景下 , 验证 30~60s 实现实例恢复 。
(3) 减卡弹性恢复技术:作为当前进行工作 , 解决硬件故障下业务中断问题 , 通过专家迁移 , 实现故障时推理进程不退出 , 以减卡为容错手段 , 动态调整推理实例规模 , 在用户无感知情况下秒级恢复 。
故障管理与感知诊断
24 小时在线的设备医生
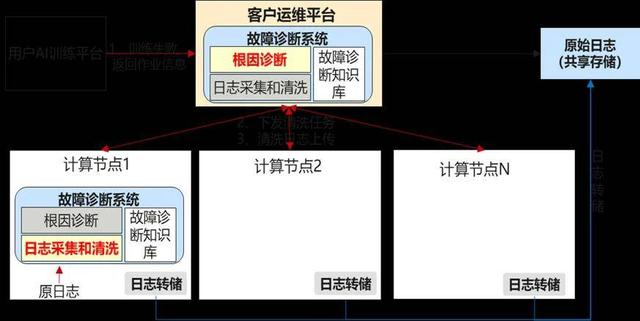
算力集群里有一套实时监控系统 , 就像给每台计算机安装了 \"健康手环\" , 持续监测温度、算力利用率、数据传输速度等指标 。 一旦发现某台设备运行异常(比如散热不良导致速度变慢) , 系统会立即发出警报 , 并像医生一样分析故障原因 —— 是硬件老化?网络拥堵?还是软件 bug?快速定位问题并启动修复机制 , 防止小故障演变成大停机 。
针对面向算力集群的硬件故障管理 , 华为团队提供了一套完整的解决方案:基于 CloudMatrix 384 超节点的设备物理形态和组网方案的昇腾 AI 硬件灾备高可靠架构设计、涵盖基础检错纠错能力、故障隔离能力、故障容错能力以及深度巡检与故障预测能力的昇腾 RAS 统一故障管理容错框架、进一步提升光链路的可靠性的网络自诊断可靠性管理、以及绿色低碳、稳定可靠和安全可信的云数据中心管理体系 。
针对面向算力集群的故障感知能力 , 华为团队构建了大规模集群在线故障感知(全栈可观测)和故障诊断(全栈故障模式库、跨域故障诊断、计算节点故障诊断、网络故障诊断)技术:
【华为昇腾万卡集群揭秘:如何驯服AI算力「巨兽」?】(1) 全栈可观测能力:构建了大规模集群的故障感知能力 , 主要由集群运行视图、告警视图、网络链路监控、告警接入和配置、网络流可观测能力组成
(2) 故障诊断能力:包括全栈故障模式库、跨域故障诊断、计算节点故障诊断、网络故障诊断;
建模仿真
算力底座的 “数字化风洞”
在正式开展复杂 AI 模型的训推之前 , 算力集群可以先在虚拟环境的 “数字化风洞” 中 \"彩排\" 。 比如研发一个新药筛选模型时 , 先通过模拟不同的算法参数、数据输入和计算资源分配方案 , 预测模型在真实场景中的表现 , 就像电影导演用动画预演复杂镜头 。 这种 \"先模拟后实战\" 的方式 , 能提前发现计算系统的瓶颈点和逻辑漏洞 , 并提出相应优化手段 , 节省大量真实训推的时间和资源 。
华为团队创新性提出系统化、可扩展的马尔科夫建模仿真平台 , 围绕对训练、推理、高可用三大核心领域实现多维度系统性建模分析与性能预测调优 , 实现集群资源高效配置与动态优化 , 达成算力极致利用与系统长期稳定可靠运行 。
(1) Sim2Train 训练建模仿真:马尔科夫训练集群建模仿真平台 , AdaptPack 编排优化长序列 PP 空泡 , 吞吐提升 4.5%-8.24% 。 通信与计算协同场景 , 引入 AdaptS/R 技术 , 通信暴露时间降 89.84% , 单步总时长缩短 3.25%;MoE 通过 AdaptExpert 提升端到端性能 7.5% 。
(2) Sim2Infer 推理建模仿真:面向昇腾复杂推理系统的马尔科夫建模仿真平台 , 实现了从高层算子描述到底层硬件指令的自动化映射与仿真 , 平均误差低至 6.6% 。
(3) Sim2Availability 高可用建模仿真:马尔科夫高可用建模仿真框架 , 通过离散时间步长仿真 , 建模单步时长内的故障性能劣化影响与恢复耗时 , 模拟复杂系统训练任务中的故障场景及运维响应 , 实现对训练过程性能表现与故障恢复状态的全周期监控仿真 。
框架迁移
给模型跑车换更酷炫轮胎
自从 2020 年 3 月全面开源以来 , 华为推出的全场景 AI 框架昇思 MindSpore 一路高歌猛进 , 开发者生态迅速成长 。 除了为基于昇腾 + 昇思的自主创新外 , 昇思 MindSpore 也提供了拥抱主流生态的兼容方案 , 适应大模型时代的挑战和需求 。
(1) 训练阶段 , MindSpore 构建了 MSAdapter 生态适配工具 , 覆盖 90% 以上 PyTorch 接口 , 实现第三方框架的无缝迁移 , 并针对动态图执行效率的问题 , 通过多级流水线技术与即时编译(JIT)优化显著提升执行效率 。
(2) 推理阶段 , MindSpore 基于主流生态的 HuggingFace 权重配置 , 无需修改即可实现一键部署 , 通过 vllm-MindSpore 插件对接 vLLM 框架 , 支持大模型推理服务化能力 。 实现盘古 72B 模型快速部署 , 实现推理性能提升 。
总结与展望
综上所述 , 华为团队针对昇腾算力集群基础设施 , 提出了针对超节点高可用、集群线性度、万卡集群训练快速恢复、万亿 MoE 模型推理容错、集群故障感知及感知诊断、集群仿真建模、框架迁移等方面的全维度的创新方案 。
随着新型应用快速变化 , 硬件系统持续创新 , 系统架构不断演进 , 工程能力走向智能化 , 未来算力基础设施的演进将走上算法 - 算力 - 工程协同进化的道路 , 有可能形成形成 “应用需求→硬件创新→工程反哺” 的闭环 , 算法层驱动算力专用化(如复合 AI 需异构加速) , 算力层通过架构革新(如光电混合)释放性能潜力 , 工程层以智能化手段(如 AI 运维)弥合复杂度鸿沟 , 最终实现高效、弹性、自愈的下一代算力基础设施 。
推荐阅读











- 白屏、卡死、闪退,苹果iOS 18.5上演邮箱“崩溃门”
- 618入手华为笔记本Linux版,这些用机技巧必须学会
- 算力瓶颈破局,华为再提速
- 华为、新紫光等加持,中国集成电路学院+1
- 中国大陆出货量排名前10机型:苹果3款,小米2款,华为1款
- 800美元以上高端机型20强榜单:华为独占8款,小米1款上榜
- 为什么有人就是不“待见”华为手机?3个原因“扎心”又现实!
- 华为、vivo在预热,小米被致敬,荣耀、OPPO在干啥
- 新数据出炉:华为稳坐头把交椅,份额难以撼动,诺基亚、思科掉队
- 华为和小米到底谁才是今年第一季度手机销量第一?