
文章图片

文章图片
文章图片
引言在该系列的文章中 , 已经花了很大的篇幅进行NumPy中多维数组内容的介绍 , 我们可以有多种方式创建多维数组以及对数组进行各种操作、运算等 。
有时候 , 由于数组中的数据量比较大 , 我们希望能将数组保存下来 , 在后续需要复用的时候 , 再重新加载到内存中 。 NumPy也提供了关于数组IO的相关方法 , 本文就来介绍一下关于多维数组保存与加载的各种常用方法 。
本文的主要内容有:
1、使用pickle模块进行数组的保存与加载
2、NumPy单个数组的保存与加载
3、NumPy多个数组的保存与加载
4、使用HDF5格式进行保存与加载
使用pickle模块进行数组的保存与加载pickle模块是Python中的一个标准库 , 用于序列化(即将对象转换为字节流)和反序列化(即将字节流转换为对象) 。 通过pickle , 您可以将几乎所有的Python对象保存到文件中或者通过网络进行传输 。 这个过程也称为“持久化” 。
通过代码 , 简单演示下:
NumPy单个数组的保存与加载通过NumPy进行单个数组的保存比较简单 , 直接提供np.save()和np.load()即可一行实现保存或者加载 。
直接看代码:
通过np.save()保存的是二进制文件 , 还可以将数组保存为纯文本文件 。
同样通过代码演示一下:
NumPy多个数组的保存与加载有时候 , 我们还需要将多个有关联的数组保存到一起 , 这时候 , 可以通过np.savez()函数来实现 。
直接看代码:
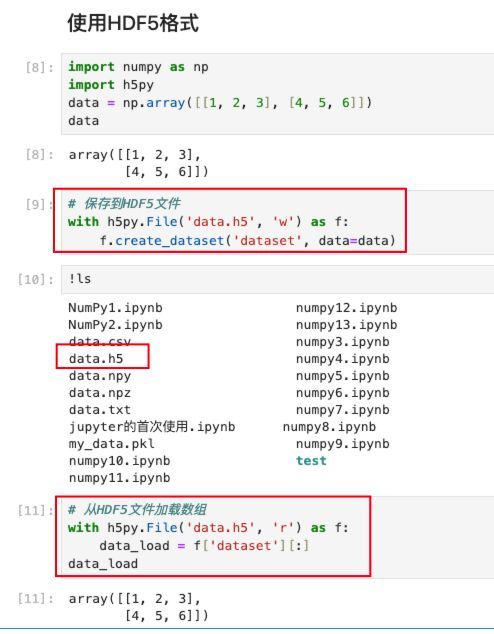
使用HDF5格式进行保存与加载有时候数据量比较大 , 保存和加载会存在性能问题 , 这时候可以考虑将数据保存为HDF5格式 。
HDF5(Hierarchical Data Format version 5)是一种用于存储和管理大量数据的文件格式 。 它采用了层次化的数据组织方式 , 支持多种数据类型 , 广泛应用于科学数据存储、工程、数值计算、机器学习等领域 。
在Python中 , 我们可以通过h5py库来轻松地读写HDF5文件 。 由于h5py是一个三方库 , 在使用之前需要先安装 。 需要注意的是 , 通过pip install h5py后 , 需要注意重启相关的Jupyter notebook的kernel , 否则无法找到该库 。
接下来 , 通过来演示将数组保存到HDF5文件:
总结本文介介绍了将NumPy中的多维数组进行保存和加载的方法 , 我们可以通过pickle进行保存和修改 , 也可以通过np.save()和np.load()进行保存和修改 。 需要保存为文本格式 , 可以使用np.savetxt()和np.loadtxt() 。 保存多个数组 , 可以使用np.savez() 。 数据量比较大时 , 可以考虑HDF5文件 。
以上就是本文的全部内容 , 感谢您的拨冗阅读!
【「Python数据科学」NumPy多维数组的保存与加载】
推荐阅读











- 合计市场份额超6成!华为联手6家HUD供应商「主攻」LCoS
- 全球最强芯片发布:5分钟,能算完超算10亿亿亿年的数据
- 差距在5%以内?疑似AMD Radeon RX9070 XT游戏测试数据流出
- 数据吞吐量提升!面向下一代音频设备 蓝牙HDT、星闪、UWB同台竞技
- 有多少中产,在给智能手表「打黑工」?
- 从心理角度来看,「跟AI交朋友」能成为社交关系的「代餐」吗?
- OPPO A5 Pro评测:一次勇闯耐用赛道的「无人区」
- 三大运营商11月成绩单出炉!用户数据增幅放缓
- 「开了挂」的芯片级游戏技术,跑分321万加,一加Ace5 Pro26日上市
- 国内首款量产闪极AI「拍拍镜」A1发布,功能强悍价格亲民