
文章图片
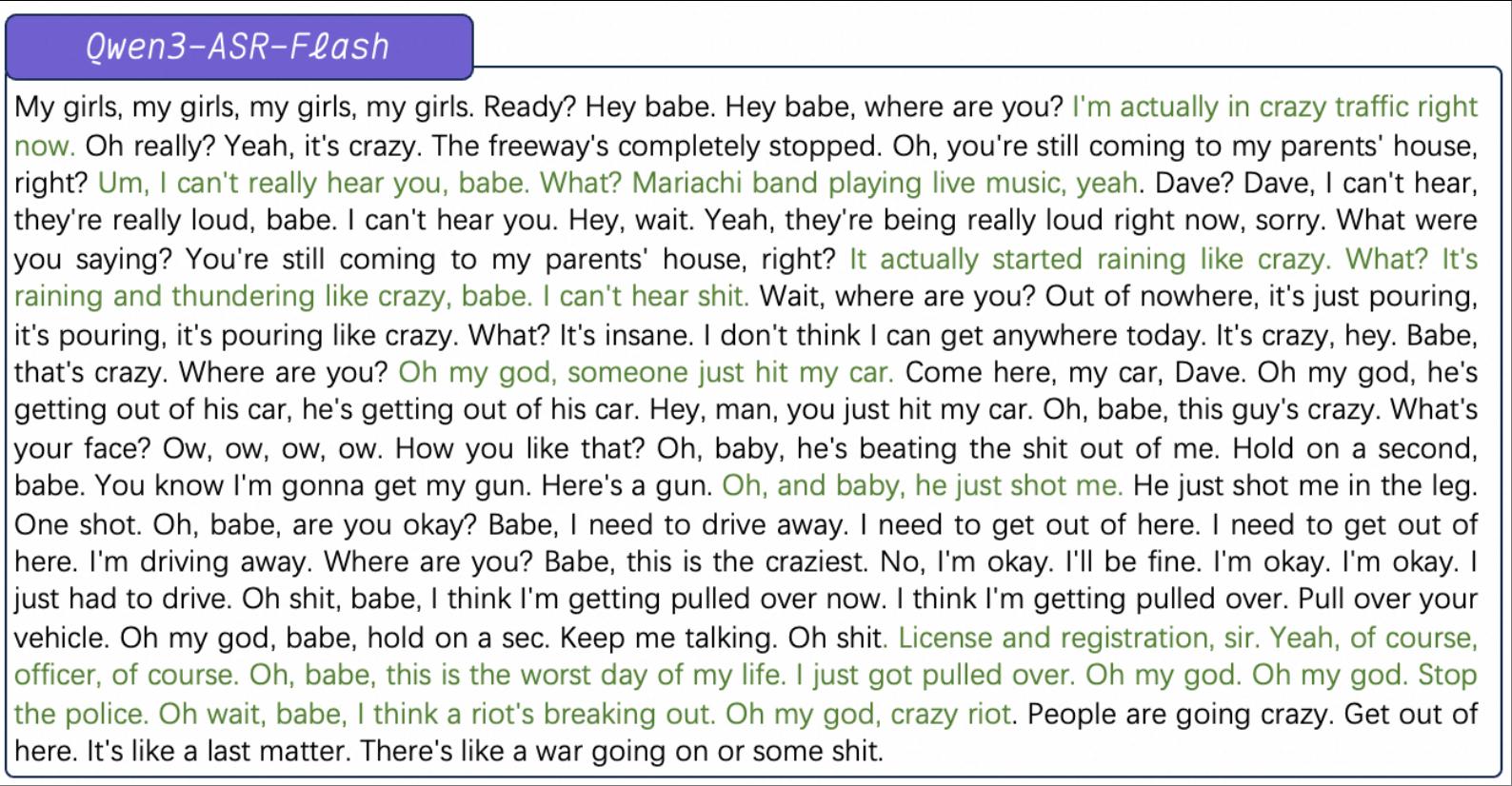
文章图片

文章图片
头图由AI生成
智东西
作者 | 程茜
编辑 | 心缘
智东西9月9日报道 , 昨天 , 阿里发布最新语音识别模型Qwen3-ASR-Flash , 该模型基于Qwen3基座模型训练 , 支持11种语言和多种口音 。 用户可以通过ModelScope、HuggingFace和阿里云百炼API Qwen3-ASR-Flash免费体验 。
在ASR(自动语音识别)的多项基准测试中 , Qwen3-ASR-Flash在方言、多语种、关键信息识别、歌词等方面的识别错误率明显低于谷歌Gemini-2.5-Pro、OpenAI GPT-4o-Transcribe、阿里巴巴语音实验室Paraformer-v1、字节豆包Doubao-ASR 。
具体来看 , 该模型支持中文、英语、法语、德语等11个语种 , 识别过程中能自动分辨语音语种、自动过滤静音和背景噪声等非语音片段 , 其是基于海量多模态数据以及千万小时规模的ASR数据构建的语音识别服务 。
此外 , 用户还可定制ASR结果 , 通过在上传音频时添加关键信息术语、音频发生背景等上下文信息 , 就能使识别结果匹配这些已有信息 。
下面是官方放出的电竞比赛解说音频示例 。 研究人员为这一场景配置了背景信息 , 包括关键词列表、这场游戏的背景等 。 因此识别结果中 , 即使电竞解说人员的语速非常快也没有影响识别游戏专业术语的效果 。
https://oss.zhidx.com/fec737df52316dd65dba06796cdb1eb9/68befd80/uploads/2025/09/68bf7afe744dc_68bf7afe6ff29_68bf7afe6fede_csgo.wav
ModelScope地址:
https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo
Hugging Face地址:
https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
阿里云百炼API调用地址:
https://bailian.console.aliyun.com/?tab=doc#/doc/?type=modelurl=2979031
一、能识别游戏解说、英文说唱 , 连续多种噪音抗干扰拉满官方放出了5个演示示例 , 包含多种类型噪声、多语种快速切换、方言、专业名词的音频识别难题 。
第一个是夹杂手机铃声、车铃声、音乐声、水声、雷声等多种类型的连续噪音 , 其中还会有不同人物之间切换对话 , Qwen3-ASR-Flash在多人同时说话或者说话间隔非常短的情况下也对语音进行了准确识别 , 没有受到噪声干扰 。
https://oss.zhidx.com/383cc163e20957eddc21e7e86a4b3f07/68befd80/uploads/2025/09/68bf7ae0b33d2_68bf7ae0ab8c0_68bf7ae0ab888_noise3.wav
第二个是英文说唱 。 英文说唱的特点是语速快、歌词中单词连读情况多 , 识别结果中很多歌词中的单词连读、长难句识别准确 , 且没有受到背景音乐的干扰 。
https://oss.zhidx.com/b2535c852c6391fdc4b1c8e71e963b26/68befd80/uploads/2025/09/68bf7b0a871b3_68bf7b0a80b74_68bf7b0a80b42_en_rap2.wav
第三个是方言的识别 。 这一场景中 , 音频中主人公正在开车 , 有主人公的方言和智能语音客服的普通话穿插出现 , 音频中智能语音客服将“纠正”错误识别成了“96” , Qwen3-ASR-Flash进行了准确识别 。
https://oss.zhidx.com/16a9a5026b271ec29d2b519f5384b210/68befd80/uploads/2025/09/68bf7b174e73d_68bf7b1747a22_68bf7b17479f3_noise1.wav
第四个是多语种句子切换 , 7秒的音频里有英语、日语等5种语言 , 识别结果都进行了一一呈现 。
https://oss.zhidx.com/05e13dcd6a7ff02eddf2fc36c488c698/68befd80/uploads/2025/09/68bf7b2154e14_68bf7b214eed6_68bf7b214eea3_mls3.wav
最后是化学课程的一段音频 。 识别结果中酯基、酸、醛、氨等化学名词 , 以及音频中人物的语气词识别并未出错 。
https://oss.zhidx.com/5f39d32577be13371754b8f8187ad8d2/68befd80/uploads/2025/09/68bf7b289da6c_68bf7b2897f24_68bf7b2897ef8_course.wav
二、歌词识别错误率低于8% , 可定制语音识别结果性能表现 , Qwen3-ASR-Flash的自动语音识别错误率 , 在中文、英文、多语言自动语音识别、歌词、关键信息识别的错误率都要低于Gemini-2.5-Pro、GPT-4o-Transcribe、Paraformer-v1、Doubao-ASR 。
在歌词识别中 , Qwen3-ASR-Flash支持清唱和带毕竟音乐的整首歌识别 , 研究人员实测识别错误率低于8% 。
该模型支持普通话以及四川话、闽南语、吴语、粤语等方言 , 英式、美式及多地区口音的英语 , 其他语言如法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语和阿拉伯语 。
如果想要获得定制化的ASR结果 , 用户可提供任意格式的背景文本来获得倾向性ASR结果 , 且用户无需对上下文信息进行预处理 。
其支持的格式包括但不限于以下一种 , 简单的关键词或热词列表、任意长度和来源的完整段落或整篇文档、以任意格式混合的关键词列表与全文段落、无关甚至无意义的文本 。 研究人员提到 , 模型对无关上下文的负面影响具有高度鲁棒性 。
基于此 , Qwen3-ASR-Flash可以利用该上下文识别并匹配命名实体和其他关键术语 , 输出定制化的识别结果 。
结语:后续将迭代通用语音识别精度一直以来 , 复杂声学环境、多样化语音特征、专业术语等都是语音识别的最大难点 。 此次为了保证用户对输出结果的可控 , 阿里研究人员上线了背景文本上传功能 , 使得这一生成结果能更加符合用户的预期 。
【阿里端出最强语音模型!英文rap精准转文字,准确率干翻全球】下一步 , 研究人员将提升Qwen3-ASR-Flash的通用识别精度 , 进一步降低普通用户的使用门槛 。
推荐阅读











- 权威报告:中国AI云市场阿里云占比35.8%位列第一 高于2到4名总和
- 阿里夸克“教育计划”陷身份认证风波,在华留学生无法领取会员
- 中国力量闪耀IFA2025 海信引领高端出海新范式
- 替代国外芯片,国产最强的CPU、GPU、Soc分析
- 刚刚,阿里首个超万亿参数新王登基!Qwen3-Max屠榜全SOTA
- 7000mAh顶配小屏!小米这新机,预定年度最强
- 联想发布二代旗舰掌机Legion Go 2:最强锐龙U、可拆卸手柄焕然一新
- 半年收入55亿,最强国产“CPU+GPU”龙头,替代intel+Nvidia
- iPhone17 Pro Max价格又变?续航最强却意外“良心定价”
- 搞定3nm,100%自研,中国最强刻蚀机厂商,半年收入50亿