文章图片
文章图片
文章图片

文章图片

文章图片

文章图片

文章图片
Grok 4跑分提前泄露 , 在「人类最后考试」中高达45%的得分 , 远超Gemini与Claude , 成为当前测试中最强模型之一 。 马斯克表示Grok 4以「第一性原理」构建推理机制 , Grok 4有望改写LLM格局 。
Grok 4马上就来 , 马斯克说的!
甚至 , 现在部署的Grok , 已经在能力上有了显著的提升 。
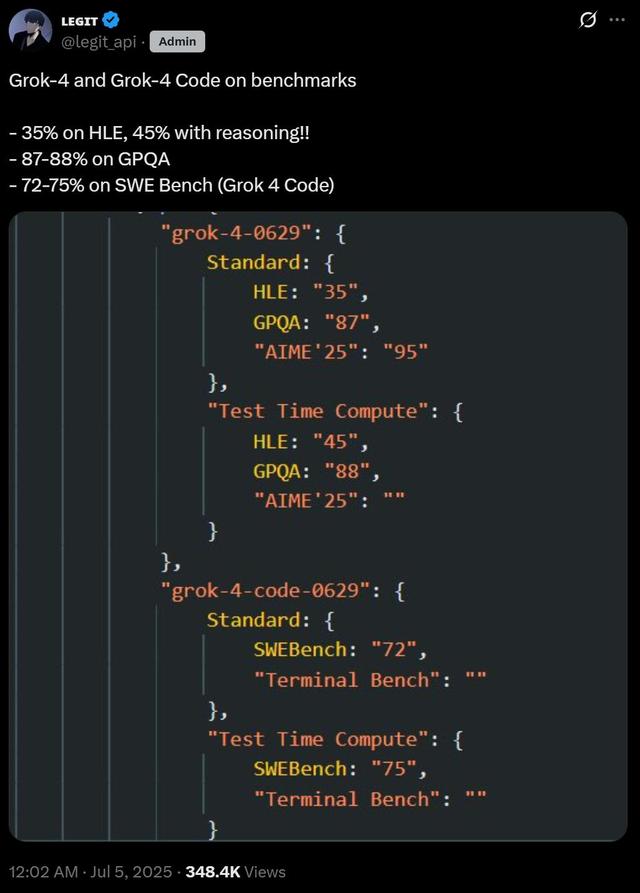
与此同时 , 网友LEGIT的一张截图 , 更是直接泄露了Grok 4和Grok 4 Code在多个关键基准评测上的跑分 。
目前 , 这一消息已经得到了AI圈知名大佬Tibor Blaho的确认 。
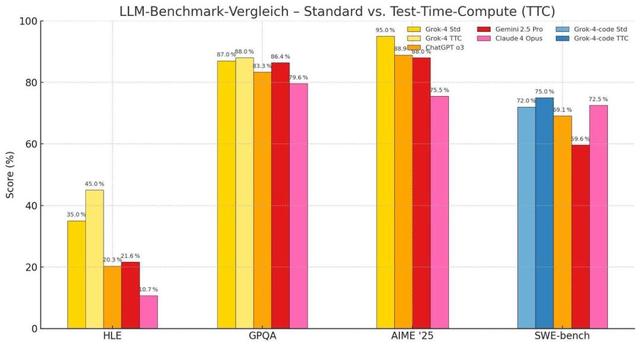
根据泄露的数据 , Grok 4在GPQA、AIME 25和SWE-bench评测中可谓是「遥遥领先」 , 全面碾压谷歌Gemini 2.5 Pro、OpenAI o3和Claude 4 Opus 。
GPQA(研究生级物理和天文学问题):Grok 4得分87-88% , 略优于Gemini 2.5 Pro的86.4% , 明显超过Claude 4 Opus的79.6% 。
AIME 25(2025美国数学邀请赛):Grok 4得分95% , 大幅超越Claude 4 Opus的75.5% , 并优于OpenAI o3的88.9% 。
SWE-bench(真实软件工程问题):Grok 4 Code得分72-75% , 略优于Claude Opus 4的72.5% , 略高于OpenAI o3的71.7% 。
不仅如此 , Grok 4还在覆盖范围最广、难度最高的终极闭卷学术基准「人类最后的考试」(Human Last Exam , HLE)上取得了默认35%、最高45%的惊人高分 。
这也意味着 , 最强状态下的Grok 4 , 得分是现任老大Gemini 2.5 Pro的2倍——高出了整整24个百分点 。
相比正确率只有10.7%的Claude 4 Opus , 成绩直接翻了4倍还多 。
HLF这门考试堪称残酷 , 是专为挫败LLM的锐气而设计:
横跨100多个学科的2500道专家级试题
14%为多模态题型(文本+图像)
24%的问题为多项选择题
设有防记忆陷阱和隐藏测试集 , 用于阻止「作弊式训练」
下图是所含知识的高层次可视化图表 , 其中的每个类别还包含有很多具体学科 。
项目主页:https://lastexam.ai/
要知道 , 大多数前沿模型在这一分数面前都望尘莫及 。
如果此次泄露属实 , 那么Grok 4就算闯过了AI基准测试领域最难的关卡之一 。
由于在HLF的得分异常地高 , Grok 4的发布再度引起了社区的广泛讨论 。
是的 , 如果属实 , 这意味着该模型具有极其强大的世界知识 。
看到如此之强的Grok 4 , 网友们已经迫不及待了 , 纷纷在线催更:
Grok 4源代码泄露大家对于Grok 4的期待可以说是完全拉满了 。
马斯克此前的采访中 , 曾经透露说 。
Grok 3.5 正在尝试从第一性原理出发进行推理 , 也就是将物理学的方法应用到思维过程中 。
Grok-3.5正是如今的Grok 4 , 老马决定一步到位 , 从Grok-3直接到Grok 4 , 不再挤牙膏了 。
这似乎预示着Grok 4的能力会非常大的突破!
几天前 , X上就有人发现在xAI控制台源代码中发现的2个Grok 4模型:Grok 4和Grok 4 Code
【马斯克Grok 4逆天跑分泄露,“人类最后考试”豪取45%全场第一】Grok 4:
最新、最卓越的旗舰模型 , 在自然语言、数学及推理领域展现出无与伦比的性能 , 堪称万能的完美之选
Grok 4 Code:
专为编程伴侣量身打造的模型 。 可以向它咨询代码相关的问题 , 或直接将其嵌入到代码编辑器中
也有人持怀疑态度当然也有人似乎是被之前Grok 3的炒作「伤透了心」 。
HLE的创建者Dan Hendrycks是xAI的亲密顾问(相比其他实验室而言) 。
网友们想知道Dan Hendrycks是否只提供了安全方面的建议 , 还是以某种方式给出了增强科学知识细节的具体研发建议 。
这不禁让人们联想到此前Llama 4的翻车闹剧 , 也是因为提前进行了「针对性的训练」 。
马斯克亲自带货马斯克曾在6月27日发帖称 , 正和团队加班加点的研发Grok 。
将在7月4日后发布Grok 4 , 按照美东时间 , 今天开始 , 任何时候都有可能见证Grok 4的发布 。
马斯克特地强调了 , 需要一次大型训练来开发了「特殊」的编码模型 。
在5月20日的微软Build 2025大会上 , 马斯克现场讲述了Grok 3.5(Grok 4)将从第一性原理出发进行构建 。
马斯克:
尤其是在即将发布的Grok 3.5中 , 我们的目标是让模型从 第一性原理出发进行推理 。
也就是说 , 像物理学家那样思考 , 借用物理的工具来分析问题 。
如果你想要探寻事物的本质真相 , 就必须把问题分解到最基本、最可能正确的公理层面 , 然后再从这些基础出发向上推理 。
接着 , 你可以将最终结论与这些基本原理进行校验 。在物理学中 , 如果你得出的结果违反了能量守恒或动量守恒 , 那你要么发现了诺奖级别的新理论 , 要么——更可能的是——你搞错了 。
所以我们打造Grok 3.5的核心目标 , 就是以物理的基本原理为指导 , 应用这些方法来推理各种问题 , 力求以最小的误差 , 接近真实 。
当然 , 出错是难免的 , 但我们的目标是持续减少这些错误 。 这个方向对于 AI 安全 至关重要 。
我长久以来都在思考AI安全问题 , 而我最终得出的结论 , 其实可以用一句老话来概括: 诚实是最好的策略 。
这不仅是道德要求 , 更是安全保障 。当然我们也会犯错 , 但我们承诺会尽快修正这些错误 。
我们也非常期待来自开发者社区的反馈——你们需要什么?我们哪里做错了?又该如何改进?
我们希望Grok成为一个令开发者充满期待的工具 , 一个他们的声音能真正被听到的平台 。
Grok将不断进化 , 努力满足开发者的需求 。
编码能力成为必争之地根据Grok API此前的模型推测 , 这次Grok 4 Code将是发布的重头戏 , 也许还会有Grok 4 mini 。
马斯克特地提到Grok 4的编码能力 , 也是受到如今各家的影响 , 编码能力称为了衡量新模型的试金石 。
谷歌
Gemini2.5包括改进的代码生成、复杂代码重构/转换、上下文管理、更好的PR评审能力 , 以及可定制命令等 。
Gemini CLI是近期推出的命令行AI助手 , 基于Gemini2.5 Pro , 可处理长达百万token的上下文 , 支持包括代码编写、调试、内容生成和任务管理于一体的多功能开发体验 。
Anthropic
Claude 4(包含Opus与Sonnet)是Anthropic迄今最强大的模型系列 , 显著提升编码与AI agent能力 。
Claude Code专注于终端环境使用 , 提供从代码编辑、问题修复、架构理解 , 到运行测试、lint、git操作、PR创建的一站式工具 。
OpenAI
新版Codex是基于OpenAI o3微调而来的 , 用于自然语言翻译代码 , 延续迄今生成工具(如GitHubCopilot)的核心能力 。
DeepSeek
DeepSeek?R1?0528是DeepSeek推出的R1最新版本 , 定位为全能推理与编码能力提升模型 。
既然老马着重提到了编码能力 , 那么也许这次是值得期待的 。
参考资料:
https://x.com/WesRothMoney/status/1941227129875857869
https://x.com/legit_api/status/1941165728708874514
推荐阅读











- 百元也有好麦克风体验,在家K歌,就选得胜DM103有线动圈麦克风
- 独家专访安克:关于被召回的70万台充电宝的一切
- 安克与ATL达成战略合作!锁定4500万片高能量密度电芯
- Grok 4泄露!6大关键特性曝出,马斯克团队搭帐篷通宵,要用它重写人类知识库
- Grok 4源代码泄露,上线倒计时,马斯克xAI估值破1130亿,大模型要变天
- 实测支持90W小米澎湃秒充!安克智显充Lite100W充电器评测
- 马斯克特朗普撕破脸!特斯拉星链遭冲击,美科技圈要变天?
- 马斯克带货Labubu?两个同济校友搞出的这款AI神器,要卷死广告圈
- 马斯克称特斯拉 Robotaxi 或一两个月内减少安全监督员
- 217克+三防破界,vivo X Fold5重塑折叠屏可靠性