
文章图片
文章图片
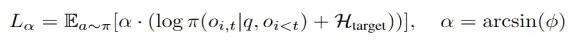
文章图片

文章图片
近年来 , 链式推理和强化学习已经被广泛应用于大语言模型 , 让大语言模型的推理能力得到了显著提升 。 然而 , 在图像生成模型中 , 这种成功经验尚未得到充分探索 。 图像生成模型往往直接依据给定文本生成图像 , 缺乏类似人类创作过程中的推理 , 导致生成的图像在语义遵循上仍有一定局限 。
近期 , 上海科技大学、微软亚洲研究院和复旦大学提出了 ReasonGen-R1 框架 , 一个两阶段训练框架 , 将链式推理监督微调(Supervised Fine-tuning)与强化学习(Reinforcement Learning)相结合 , 以提升自回归图像生成模型的推理和创作能力 。 ReasonGen-R1 使得自回归图像生成模型可以端到端地在输出图片之前先进行文本「思考」 , 大幅提升了基座模型的语义遵循能力 , 并在多个语义指标上取得突破 。
目前 , ReasonGen-R1 已全面开源(包括训练、评测代码 , 训练数据以及模型) 。
- 论文标题:ReasonGen-R1: CoT for Autoregressive Image Generation model through SFT and RL
- Arxiv 地址:https://arxiv.org/abs/2505.24875
- 代码地址:https://github.com/Franklin-Zhang0/ReasonGen-R1
- 项目主页:https://reasongen-r1.github.io
方法概览ReasonGen-R1 的训练包括两个核心阶段:监督微调阶段(SFT)以及强化学习阶段(RL) 。
监督微调阶段首先构建了一个大规模图片生成推理数据集 , 共包含 20 万条图像-文本对 。 该数据集基于 LAION 美学子集 , 利用 GPT-4.1 根据图片自动生成两类描述:一是多样化的简洁图片描述(包括常规叙述、基于标签和以物体为中心的叙述) , 二是丰富的推理式 CoT(chain-of-thought)叙述 。 多风格的简洁图片描述设计有效避免了模型在 SFT 阶段对单一 prompt 模式的过拟合 。
随后 , ReasonGen-R1 按照「Prompt → CoT → <img_start> → Image」的 token 顺序进行 SFT 微调 , 使得基座模型拥有了初步的在图像生成之前进行文本「思考」的能力 。
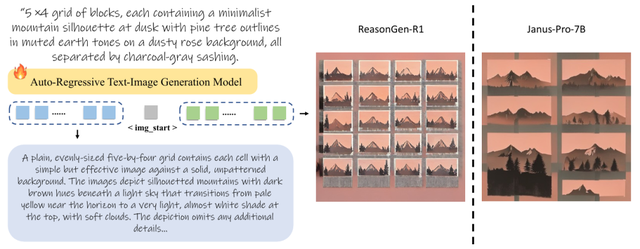
图1. ReasonGen-R1 模型架构概览 。 ReasonGen-R1通过监督微调(SFT)以及强化学习(RL)使得模型可以先进行链式推理 , 再生成最终图片 。
强化学习阶段通过 Group Relative Policy Optimization(GRPO)进一步优化模型输出 。 为了有效评价生成输出图像的质量和输入文本-输出图像的一致性 , ReasonGen-R1 采用了预训练视觉语言模型 Qwen-2.5-VL-7B 作为奖励模型 , 让其对于每个输出图片 , 根据图片以及输入文本是否一致 , 给出 0、1 奖励 。
图2. ReasonGen-R1强化学习框架概览 。
此外 , 为确保训练稳定性 , ReasonGen-R1 提出了一种改进的自适应熵损失函数 , 该损失函数能够将输出 token 的熵动态调节到目标熵附近 , 有效防止了在文本图像混合强化训练过程中训练不稳定导致模式崩塌的问题 。
图3. 自适应熵损失中用于更新熵损失参数的loss function
ReasonGen-R1 实验结果
团队基于 Janus-Pro-7B 模型对 ReasonGen-R1 进行了全方面测试 , 选取了三个图像生成语义遵循指标:GenEval、DPG-Bench 以及 T2I-Benchmark 。
如图 4 所示 , ReasonGen-R1 在所有指标上都较基座模型有了显著的提升 。 这些结果表明 , 将文本推理通过 SFT-RL 的框架应用于图片生成 , 能够显著提升自回归图像生成模型的性能 。
图4. 左图:基座模型Janus-Pro-7B和ReasonGen-R1生成图像可视化比较;右图:三个指令遵循指标上的表现比较 。 ReasonGen-R1在所有指标上均超过了基座模型 , 体现了指令遵循能力的巨大提升 。
为深入探讨 ReasonGen-R1 各个模块的贡献 , 研究还进行了以下消融实验:
SFT 阶段的作用:为了测试 SFT 阶段对于模型最终性能的影响 , ReasonGen-R1 对比了直接强化学习的结果 。 如表 1 所示 , 仅使用强化学习(RL)而未进行监督微调(SFT)时 , 模型表现显著下降 , 证明了 SFT 阶段对模型后续强化学习阶段的重要性 。
奖励模型规模影响:实验还对比了不同大小的奖励模型 。 如表 1 所示 , 较小规模的奖励模型(Qwen-2.5-VL-3B)无法提供足够精准的反馈信号 , 严重影响强化学习阶段的表现 。 因此 , 选择高精度、大规模的奖励模型至关重要 。
表1. ReasonGen-R1在GenEval指标上对于架构设计的消融实验
自适应熵损失函数的稳定作用:如图 6 所示 , 在没有熵损失的情况下 , 模型在经过 100 步的训练后会出现熵爆炸 , 同时 Reward 开始缓慢下降 。 另一方面 , 施加固定熵惩罚(–0.002)会使熵持续下降 , 并在第 80 步时过低 , 进而引发图片生成模式崩塌和奖励急剧下滑 。 这些现象凸显了在交错文本与图像的 RL 训练中 , 对于熵损失正则化设置的敏感性 。 相比之下 , 采用 ReasonGen-R1 提出的自适应熵损失能够将熵保持在最佳范围内 , 确保训练过程的稳定性以及奖励的稳定增长 。
图6. 对于各个熵正则化策略在强化学习中的效果比较
ReasonGen-R1 CoT 分析
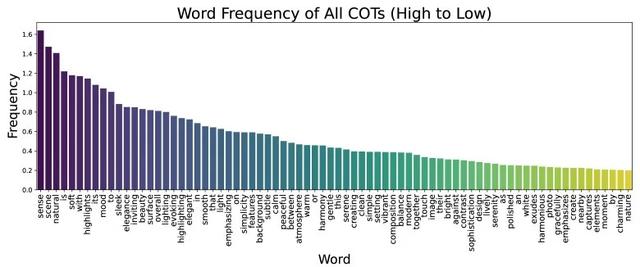
图7. 1000次CoT输出中的单词频率 。 只有出现频率高于20%的单词被展示 。 出现频率最高的三个’a an the’被移除以关注保护更多信息的词语
图 7 展示了 ReasonGen-R1 推理链的模式 。 首先 , 它通过「感知」(sense)、「场景」(scene)和「自然」(natural)等高频词(在超过 140% 的 CoT 中出现)来奠定总体框架 , 强调整体语境和真实场景 。 接着 , 它细化视觉风格:诸如「柔和」(soft)、「高光」(highlights)、「氛围」(mood)和「流畅」(sleek)等词汇(均在超过 100% 的 CoT 中出现)用以描述光照质量、情感基调和质感 。
更关键的是 , 「突出」(highlighting)和「强调」(emphasizing)这两个词各自在至少 70% 的 CoT 中出现 , 表明模型有意识地聚焦于主要主体 。 这揭示出 ReasonGen-R1 不仅仅是在描述物体 , 而是在主动规划构图焦点 。
除了核心词汇外 , ReasonGen-R1 还运用了大量修饰词——「背景」(background)用于建立环境氛围;「特征」(features)用于突出显著视觉元素;「宁静」(calm)用于渲染平和氛围;「瞬间」(moments)用于传达时间抓拍感;「捕捉」(captured)用于强调摄影真实感;等等——以在每条推理序列中注入细腻的、情境化的细节 。
【SFT+RL双管齐下:ReasonGen-R1如何破解文生图「指令不遵」难题?】总体而言 , ReasonGen-R1 的推理链通过场景框架、风格细节、主体聚焦和细节修饰等要素 , 有效地引导了图像生成过程 。













