
文章图片
文章图片
文章图片
为了防止高考生使用AI作弊 , 今年高考期间 , 腾讯混元、通义千问、Kimi、豆包等国内知名AI大模型的图片识别问答功能均暂停服务 。 对于这些企业的做法 , 小雷却有一些质疑 , 之前小雷测试AI大模型做高考题 , 大多表现不佳 , 暂停图片识别问答服务似乎过于高看自家AI大模型的能力 。
到截稿时 , 2025年高考全国一卷仅有语文、英语和数学三套试卷公布 , 其中语文高考题目曝光后 , 已有多家媒体实测AI大模型撰写作文 。 不过作文写得如何 , 每个人的观点可能不同 , 小雷看到的几篇评测基本是截取AI大模型撰写的文章 , 没有给出点评 , 文章质量需要读者评判 。
(图源:百度搜索截图)
慎重起见 , 小雷选择了有标准答案的数学科目 , 测试AI大模型的能力 , 所选的AI大模型分别为DeepSeek、豆包、讯飞星火、文心一言、Kimi、通义千问 , 它们能考上985、211吗?
六款大模型PK , 谁才是AI界的高考状元?首先说一下测试环境和题目 , 考虑到部分AI大模型不支持手动开关联网模式 , 因而所有AI大模型启用联网搜索 , 深度思考功能也全部打开 。
所选的数学题 , 包含一道单选题、一道多选题、一道填空题、一道简答题 , 最终会按照题目的分数进行打分 。
第一题(5分):
若双曲线C虚轴长是实轴长的√7倍 , 则C离心率为(正确答案:D)
A:√6B:2C:√7D:2√2
第一道题属于开胃小菜 , 难度不算大 , 参与测试的六款AI大模型也没有令小雷失望 , 全部计算出了正确答案 , 而且给出了详细推理过程 。 本题测试中 , 所有AI大模型均获得满分5分 。 (图片从左往右以此为:DeepSeek、讯飞星火、豆包、Kimi、文心一言、通义千问 , 下图同)
(图源:App截图)
尽管这道题难度不算高 , 但这六款AI大模型的表现令小雷眼前一亮 。 此前测试AI大模型的数学计算能力时 , 面对稍微复杂一些的问题 , AI大模型很难计算出正确答案 。
仅一轮测试 , DeepSeek、讯飞星火、豆包、文心一言、Kimi、通义千问六款AI大模型就证明了它们的能力 , 存在被高考生用于的作弊的可能性 , 暂停图片识别问答功能绝非为了蹭高考的热度 。
第二题(6分):
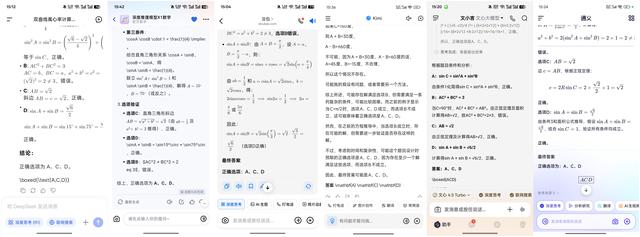
若cos 2A+cos 2B+2sin C=2 , SΔABC=1/4 , cos Acos Bsin C=1/4 , 则(正确答案:ACD)
A:sin C=sin2A+sin2BB:AC2+BC2=3C:AB=√2
D:sin A+sin B=(√6)/2
这道题难度相当高 , 仅有豆包在两分钟内计算出正确答案 , 讯飞星火和通义千问耗时略长一些 , 其他几款AI大模型用时更长 , 尤其是DeepSeek , 耗时足足572秒 , 接近10分钟 。
(图源:App截图)
若是AI大模型像考生一样每次只做一道题 , 推理较慢的三款AI大模型 , 存在两小时时间做不完题的可能性 。
尽管本轮测试中所有AI大模型均正确回答出了问题 , 但结合推理所需时长来看 , 豆包、讯飞星火、通义千问表现较好 。
第三题(5分):
若一个等比数列的前4项和为4 , 前8项和为68 , 则该等比数列的公比为(正确答案:±2)
与上一题相比 , 这一题的难度有所下降 , 讯飞星火、文心一言、Kimi、通义千问、DeepSeek五款大模型均迅速计算出了正确答案 , 文心一言几乎是秒算 。 豆包虽计算出了正确答案 , 但在输出答案时却犯了迷糊 , 排除了-2 。 因此 , 小雷不得不扣掉豆包的三分 , 该题豆包只能得2分 。
(图源:App截图)
在本轮测试中 , DeepSeek服务器繁忙的问题频繁发生 , 小雷不得不借助第三方应用 。 好在 , 现阶段许多AI应用已接入DeepSeek , 小雷使用的腾讯元宝App , 无论是推理速度 , 还是稳定性 , 都远高于DeepSeek网页版或App 。
第四题(17分):
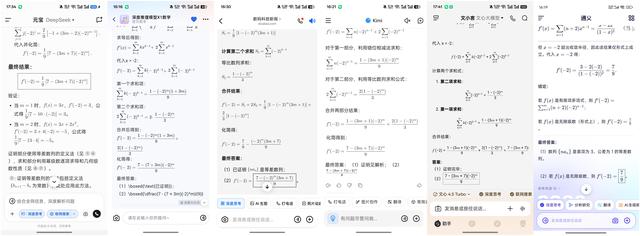
设数列{an满足a?=3 , (an+1)/n=(an/(n+1))+(1/(n(n+1)))
(1)证明:{n an是等差数列;(正确答案:n an是an=3 , 公差为1的等差数列)
(2)设f(x)=a?X+a?X2+a?X3+...+amX^m , 求f′(-2) 。 (正确答案:f′(-2)=(7/9)-((3m+7)/9)·(-2^m))
【大模型PK高考数学:DeepSeek文心豆包皆满分,差生意外】前三道题 , 几款AI应用仅在体验上存在一定的差异 , 能力基本没有表现出区别 , 第四道题不同 , 它的复杂度远超前面三道题 , 也是检验AI大模型能力最重要的一项挑战 。
在本轮测试中 , 豆包、讯飞星火、Kimi、文心一言、DeepSeek依然表现出色 , 正确计算出了两道题的答案 。 通义千问解答这道题时 , 能够推理出第一道小题的答案 , 但第二道小题却给出了错误答案 , 表现稍逊一筹 。
(图源:App截图)
豆包、讯飞星火、文心一言、Kimi、DeepSeek可以在本轮测试中拿到满分17分 , 通义千问因答错了第二道小题 , 只能获得7分 。
依靠公式和逻辑推理的数学题 , 似乎更符合AI的特性 , 但往年的评测中 , AI大模型通常做阅读理解和写作文效果较好 , 面对复杂的数学题找不到答题方法 。
光明网在去年6月的报道中提到 , 复旦大学NLP实验结果显示 , AI大模型在做2024年高考题时 , 在语文领域的表现远强于数学 , 部分数学题AI大模型甚至全军覆没 , 没有一个能够正确计算出答案 , 遇到多选题时也是错误频出 。 究其原因 , 数学失之毫厘差之千里 , 不能出一丁点错误 , 文史类内容则可以允许出现部分错误和较为模糊的答案 。
一年时间过去 , AI大模型进步神速 , 深度思考模式的加入、针对数学题的专项优化 , 令AI大模型在处理高考数学题时更加游刃有余 。
比学霸更牛 , 但大模型做题能力已拉开差距四道题目测试下来 , 最终得分如下:
DeepSeek:33分; 讯飞星火:33分; 豆包:30分; Kimi:33分; 文心一言:33分; 通义千问:23分 。经过测试 , DeepSeek、讯飞星火、Kimi、文心一言均获得满分 , 豆包表现不错 , 因一时疏忽 , 遗憾丢了三分 , 痛失高考状元 。 通义千问计算较为简单的问题时 , 都保持了极高的水准 , 但处理较难的问题时出现了计算错误 , 需要再接再厉 。
(图源:豆包AI生成)
总是向AI行业泼冷水的苹果 , 日前在论文中表示 , AI推理模型只是「假思考」 , 根本没有稳定、可理解的推理过程 , 更像是记忆 , 处理复杂任务时可能会崩溃 。 AI研究者Lisan al Gaib复刻苹果测试方法后表示 , 模型不是因为推理能力差失败 , 而是因为苹果限制了输出token 。
或许AI大模型推理能力仍存在上限 , 但我们看得到它们的进步 。 去年复旦大学NLP实验室测试AI大模型时 , 它们面对高考数学题表现糟糕 , 小雷在几次AI大模型横评测试中 , 也得到了类似的结果 。 今年的测试中 , AI大模型基本都能计算出问题的正确答案 , 曾经难住AI大模型的多选题 , 也未能再对AI大模型造成困扰 。
AI大模型数学题解答能力提升 , 最大受惠者可能是学生群体 。 国内学习机厂商和教育辅导平台 , 已陆续加入AI答题能力 , 但许多设备的AI大模型仅能解答中小学问题 , 例如行业翘楚小猿搜题 , 题目库不包含大学课程 。
这六款AI大模型的优秀表现 , 证明了国内头部AI企业的实力 , 高考数学题已被征服 , 高等数学也不会远了 。 学习机厂商、教辅平台可以与头部AI企业合作 , 增强产品AI答题的能力 , 继续强化AI教育硬件业务 。
?本文来自“雷科技” , 36氪经授权转载 。
推荐阅读












- 大模型让P图师也失业了?留给人类的职业真不多了
- 小红书开源首个大模型,中文评测超越DeepSeek-V3
- 全国产AI的胜利:六家主流大模型写高考作文,讯飞星火实测第一
- 高考后换本别着急,看看过来人经验再入手:这几款用到毕业不卡顿
- 全球30名顶尖数学家秘密集会围剿AI,结果如何?
- 大模型「躲在洞穴里」观察世界?强化学习大佬吹哨提醒LLM致命缺点
- 大模型智能体如何突破规模化应用瓶颈,核心在于Agentic ROI
- 高考后!聊聊大学生笔记本电脑选购心得,如何选择适合的电脑?
- 全球30名顶尖数学家秘密集会围剿AI当场破防!惊呼已接近数学天才
- 一周两破18年数学纪录!陶哲轩惊叹:AlphaEvolve带来久违加速度