文章图片

文章图片

文章图片
豆包 , 可以视频通话了 。
自年初更新「实时语音通话」功能之后 , 这一功能就持续受到用户欢迎 。 现在在社交媒体上搜索豆包 , 排名前十的热门关键词中 , 有 6 个与「打电话」功能有关 。 大量和豆包通话相关的创意内容也受到了观众追捧 。
随着视频能力上线 , 豆包的通话功能迎来了一次「升维」 , 变得更实用、好用 。 结合视频图像 , 很多即便模糊的语音输入 , 也能够更好地被 AI 理解 , 用户不需要再组织语言去描述眼前的信息 。
视频通话是一个单点功能 , 但在这背后是语言能力、多模态能力、推理能力、知识库等等多个垂直领域的技术积累、整合 , 以及对成本和效率的平衡 。
更重要的是 , 视频通话能力预示了 AI 助手更远的前景 。 当 AI 同时拥有了眼睛和耳朵 , 在未来更多硬件创新的支持下 , 还将解放更大的创新潜力 。
01帮你理解眼前一切的豆包
视频通话能力给豆包带来的 , 首先是多模态理解的能力提升和交互优化 。
从最基础的「理解」场景开始 , 用户可以把手机摄像头对准任何信息 , 如信息版、菜单 , 让豆包给出翻译、解释 。 而且过程中 , 用户可以不断通过语言输入 , 来修正豆包的关注重点 。
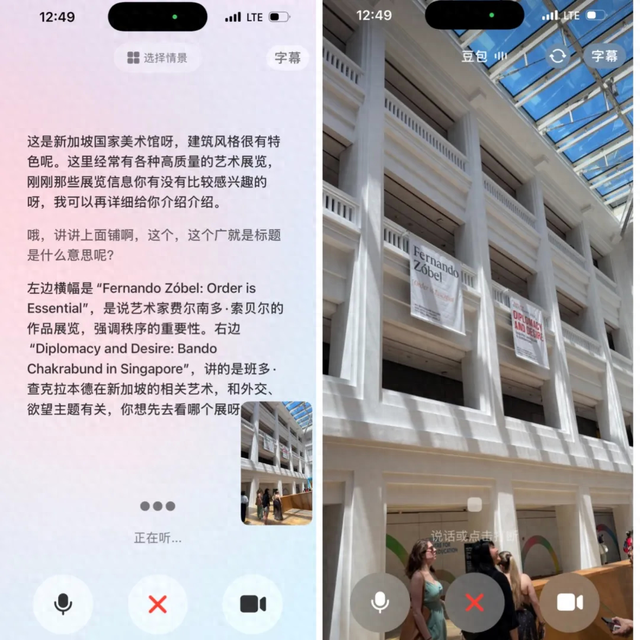
比如在一个博物馆里 , 当我们开启视频通话 , 问豆包这是什么 , 豆包首先会根据画面里的地标特征 , 识别出这是「新加坡国家美术馆」 。 然后我们如果继续追问 , 楼上挂着的横幅是什么意思 , 豆包又会给出具体展览信息的翻译和解释 。
而在看展览的过程中 , 我们也可以举着手机 , 随时针对任何一幅作品向豆包发问 。 从基本的翻译作品信息 , 到问它作品风格具体属于哪一个派别 , 是否有模仿哪个艺术家的痕迹 , 豆包都能给出精准判断 。
基于豆包给出的信息 , 我们也能进一步挖掘一些更深的隐藏关联 。 比如在新加坡国家美术馆里有一个法院拘留室的展示区域 , 问过豆包之后我发现 , 这里的关系在于 , 新加坡国家美术馆由原政府大厦和原最高法院大楼改建而成 。 前法院的拘留室曾用于关押候审的被告 , 在美术馆改建后 , 部分拘留室被保留了下来 , 成为了美术馆的一部分 , 供公众参观 , 让人们可以了解新加坡的司法历史 。
除此之外 , 我们还可以和豆包讲讲自己对美术作品的一些理解和看法 , 进行观点碰撞 。 实际上 , 豆包已经具备一定的「纠错」能力 , 不是只会一味地顺从用户的理解 。 比如这里 , 当我引用了错误的类比 , 说这个作品像「蒙德里安」风格时 , 豆包能够纠正我的错误 , 告诉我实际像的是安迪·沃霍尔 。 之后我们还可以进一步探讨 , 为什么会出现这个错误 。 我们也可以引导豆包对作品进行批判性的解读和评价 。
这里还有一个很关键的点 , 因为有了图像视觉信息作为辅助 , 很多时候即便我发出指令的声音很小 , 豆包并未完整识别我所说的句子的每一个字 , 但它依然能通过捕捉关键词 , 准确理解我的意图 。
在旅行、观光、展览……等视觉信息占比更高的场景 , 最能体现出豆包视频通话能力的优势 。 我们可以随手举起手机 , 让豆包看到我们眼前的东西 , 从最基本的「这是什么?」出发 , 一点点挖掘出更多的信息和知识 。 比如让豆包根据周边的景色推理出我们在哪 , 推荐周边值得一去的景点、活动、特色饮食 , 这既具有实用价值也充满乐趣 , 适合出游不喜欢做严密的计划 , 喜欢遇到更多偶然惊喜的 P 人 。
包括在餐厅吃饭 , 碰到那些「不知道该怎么吃」的情形 , 也很适合通过视频通话功能求助豆包 。 比如吃荞麦面的时候店员端上来一壶像热水一样的东西 , 这个时候豆包也轻松给出了正确答案 , 壶里装的是荞麦面汤 , 可以和酱汁混合在一起喝掉 。
豆包的视频通话功能 , 相比普通的图像识别 , 最关键的优势依然在于它的「互动性」更强 。 基于单张图像的理解和推理 , 很可能出现各种理解偏差、错误 。 有了视频模式之后 , 即便豆包给出了一个比较可疑的回应 , 我们也可以通过换个角度 , 提供更多信息 , 来给豆包进行更多思考和修正的机会 。
比如在这个场景下 , 我们想知道酒店的某个装置的作用 , 问豆包之后它首先以为我们问的是前面的熨衣板 。 经过进一步交互 , 它知道了我们想问的是后面的行李架 , 但因为角度问题 , 它将行李架错误理解成了健身器材 , 之后换个角度进一步追问并识别之后 , 豆包成功给出了行李架这一答案 。
这是视频通话的功能的关键优势之一 。 当下任何 AI 大模型都不可避免地会有「幻觉」和错误 。 当用户精心编写了一大段 prompt 却没有得到自己想要的输出结果时 , 就会极大打击他们使用 AI 的积极性 。 但通过给到更多信息 , 提供更多角度的输入补充 , 就能让 AI 更接近我们需要的正确答案 。 可以说 , 在视频通话场景下 , AI 和用户形成了互动的正向循环 。
除了日常生活场景 , 豆包的视频通话功能还可以在学习、工作等各种场景发挥作用 , 特别是基于一些纸质的材料进行理解和修改 。 比如对多页的纸质资料进行总结 , 或对学科题目进行解答、纠错 。
02模型技术的「木桶理论」
「视频通话」的功能本身非常简洁 , 任何用户理解起来都没有门槛 , 但在这背后 , 其实需要复杂的技术作为支持 。
豆包视频通话功能的核心来自「豆包视觉理解模型」的支持 。 2024 年 12 月 , 豆包首次发布视觉理解模型 , 为视频通话功能提供了模型能力基础 。
除了视觉感知之外 , 豆包视觉理解模型还具备深度思考能力 。 这让豆包实际上还可以通过摄像头直接进行解学科题目、分析论文以及诊断代码等任务 。 这也是为什么在视频通话过程中豆包能同时结合「图像画面」和「用户语音指令」 , 精准理解用户意图 。
豆包并不是第一个实现这一功能的 AI 助手 , 但想要同时拥有优秀的视觉理解能力 , 再基于视觉理解和用户指令 , 将不同模态的信息综合理解后 , 生成用户想要的信息 , 同时还要做到低延迟 , 这一切就有很高的技术门槛 。
整个过程有点像「木桶理论」 , 一个模型必须同时做好多个方面 , 才能做到像一个真实的「AI 助手」一样 , 满足用户的需要 。
03为什么「视频通话」能解锁 AI 交互的更多创新?
今天 , 「视频通话」只是豆包的一个小功能 。 但实际上 , 视觉理解能力所蕴含的潜力和可能性还不止于此 。
自诞生至今 , 大模型 AI 助手的交互都是「一问一答」式 , 用户输入 prompt , AI 生成反馈 。 这里最大的矛盾在于 , 整理编写 prompt 是有门槛的 , 且这个门槛比想象中更高 , 而一问一答式的交互又是断裂的 , 大家都很容易「把天聊死」 , 面对 AI 也一样 。
而视觉图像的引入 , 则为人机交互建立了一个「语境」 , 且这个语境的建立不需要任何门槛 , 天然富含信息 , 用户只需要举起摄像头就行了 。 实际上 , 人类自身理解世界的过程中 , 我们最重要的信息接收器官也一直是眼睛 。
通过豆包的视频通话功能 , 这一模式的有效性已经得到体现 。 通过连贯的互动加上视觉理解 , 用户和 AI 交互的过程变得更自然了 , 可以通过不断补充、解释 , 来接近自己想要的那个目标 。 这种用户和 AI 互相引导 , 对 propmt 进行不断修正 , 能极大增加 prompt 输入的带宽和精确度 。
实际上 , 这早就是行业共识 。 自 AI 大模型技术诞生之后 , 几乎所有硬件创新都是在探索一种「摄像头+麦克风」的组合 , 从 AI Pin , 到各种 AI 智能眼镜 , 都是在建立一种让 AI「看+听」的感知模式 。 只不过目前大部分这类硬件 , 都还无法在性能和效率上 , 做到像手机那么高的可行度 。
当下我们在使用豆包的视频通话功能时 , 依然能感受到它被手机这个硬件载体限制着 。 比如我们很难长时间举着手机对准前方我们看到的东西 , 以及在一些公共场合也不便于大声说话 , 无法和 AI 充分进行语音沟通 , 这都是智能手机作为传统硬件的限制所在 。
【豆包为什么要给 AI 助手「开眼」?】从豆包的「视频通话功能」已经可以看出 , 让 AI「看+听」的输入模式 , 可能代表 AI 交互的更多可能性 。 它在软件上完全是可行的 , 随着模型能力的进一步发展 , 结合硬件创新 , 或许将进一步改变我们与 AI 的交互方式 。
推荐阅读















- 为什么我这么多年,一直用苹果iPhone,不换安卓手机?
- 为什么有人就是不“待见”华为手机?3个原因“扎心”又现实!
- 华为,为什么让我们如此自豪?
- 为什么内行人更推荐荣耀200 Pro,而不是荣耀300?因为优势明显!
- 为什么手机厂商不愿配备10000毫安大电池?
- 为什么厂商痴迷于大电池数字?简单原因用户太好骗!
- 为什么说RGB-Mini LED电视是世俱杯球迷的终极选择?三大优势解析
- 华为千亿估值的“独角兽”,为什么选择布局重庆?
- 为什么国人宁愿买苹果,不愿买国产高端,4点原因很现实
- 宗熙先生:什么是EDA软件?它的功能是什么?为什么如此重要?