
文章图片

文章图片

文章图片

文章图片
前言看天梯图就能选到一张高性价比显卡吗?不能 。
此文 , 以RX9070GRE 和RTX5070为例 , 将讲解“显卡六维对比法” , 将游戏主机中最贵的配件从头到脚看个清楚 。
正文站长以前介绍过一种简单办法 , 即用【TS分/价格】 , 得出“每一元能买多少性能分数” 。 如果把N卡和A卡拉在一起比较 , 会发现A卡性价比会更高 。
例如:
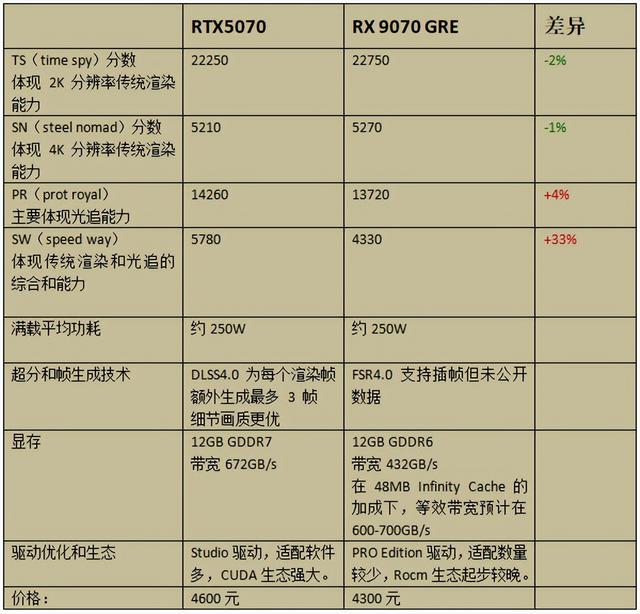
RTX5070:TS=22200分 , 价格4600元 , 比值4.8
RX9070GRE :TS=22700分 , 价格4300元 , 比值5.3
这种方法的弊端相当明显 , 因为TS只能反应“在2K分辨率下的传统渲染性能” , 而忽略了很多重要指标 。
如果要全面地横向对比N卡和A卡 , 要从九个维度考量 , 分别是:制程、能效比、光栅性能、光追性能、超分与帧生成技术、显存、驱动优化和生态、价格和残值率 。
由于制程和能效比密切相关 , 如果不考虑残值率 , 在研究性价比时 , 可以缩减到六个维度 , 分别是:
能效比、传统渲染性价比、传统渲染和光追综合性价比、超分与帧生成技术、显存、驱动优化和生态 。
下面的内容涉及到N卡和A卡的比较 , 站长不会和稀泥 , 高手对决 , 必分高下 。
一、能效比
能效比是衡量显卡是否优秀最重要的因素 , 高能效比=优秀的制程+优秀的架构+优秀的驱动
计算方法——
TS分/满载平均功耗 , 两者打平 。
SN分/满载平均功耗 , 两者打平 。
SW分/满载平均功耗 , RTX5070胜利
如用SW分数计算 , RTX50系列排序更高 。
二、驱动优化和生态
驱动是一款显卡的核心竞争力 , 包含三个层面:稳定性、面向游戏的优化、面向专业的优化 。 另外 , 我们把生态也算在一起 。
从RDNA诞生以来 , A卡的驱动稳定性要略低于N卡 , 这种情况延续到RDNA2 , 到了RDNA3有好转 , 掉驱动的报告明显减少 , RDNA4预计应该更稳 , 这里暂时认为 , 在稳定性方面 , 两者打平 。
面向游戏的优化:各有优势 , 两者打平 。
面向专业的生态:英伟达向游戏显卡提供了Studio 驱动 , 对专业软件优化 , 如3DS MAX、Maya、Adobe Premiere、Maya 等 。 (具体可参考极速空间专业文章:《这类显卡日落西山 , 但落不下去》) 。 AMD也提供了PRO Edition专业版驱动 , 但这个驱动并不是针对游戏显卡的 , 官方的解释是“”未经验证 , 理论上兼容” 。 实际测试表明 , PRO Edition也是可以用在游戏显卡上的 , 玩游戏和Adrenalin驱动差不多 , 但对专业软件优化的数量和质量上和Studio相比还有较大的差距 。
生态:CUDA在科学计算、AI 开发、3D 建模等专业领域广泛使用 , 拥有庞大的开发者社区和丰富的软件支持 。 AMD的ROCm起步较晚 , 这方面CDUA完胜 。
三、传统渲染性价比
计算方法:
TS分数(小于3万分时)/价格 , 其含义是每一元能买到多少性能分数 。
SN分数(大于3万分时)/价格 , 比值越高 , 性价比越好 。
比赛结果(见此文末尾图):此项目RX9070小幅领先于RTX5070 。 实际游戏表现两者互有胜负 。
四、传统渲染和光追综合性价比
计算方法:SW分数/价格
比赛结果:RTX5070胜利 。
大家发现没有 , 二者的TS、SN分数接近 , 功耗接近 , 但一到SW测试中 , 差距就拉开了 。
原因如下:
1、RTX5070采用Blackwell架构 , 其光线追踪单元(RT Core)和AI加速单元(Tensor Core)与CUDA核心的协同设计更紧密 。
2、显存原生带宽显存优于等效带宽 , 运行更高效 。
RTX5070是GDDR7显存 , 带宽672GB/s 。
RX9070GRE是GDDR6显存 , 带宽432GB/S , 在独家黑科技48MB Infinity Cache的加成下 , 等效带宽可达600-700GB/s 。
传统渲染数据重复性高 , 这时可以充分发挥Infinity Cache的威力 。 但在SW这类复杂的混合场景中 , 光线追踪、动态光照、粒子效果等需要频繁访问显存中非连续或随机分布的数据 , 此时缓存命中率显著下降 , 显存带宽将受限于GDDR6原生的432GB/s 。
这就是二者TS/SN分数接近 , 但SW分数差距明显的原因 。
看到这里 , 可能大家会有一个疑问:为啥不把光追单独拿出来对比呢?
原因很简单 , 实际游戏中并不是只有光追计算 , PR分数的光追占比太大 , 使用SW分数更贴合实际游戏场景 。
五、超分辨率和帧生成技术
现在的游戏画面越来越复杂 , 单纯的依靠GPU蛮力计算很难大幅度提升帧数 。 英伟达的DLSS和AMD FSR能在高分辨率场景下大幅度提升FPS 。
两者相同之处:都通过渲染低分辨率画面 , 再运用AI技术 , 将画面“脑补”到高分辨率 , 同时还能“脑补”出更多的画面 , 然后输出 。
区别在于:DLSS4全程依赖专用AI硬件(如Tensor Core) , 而FSR4以算法为主 , AI为辅 。
英伟达的DLSS4官宣为每个渲染帧额外生成最多 3 帧 , 细节画质更优 。 AMD的未公布插帧数量 。
六、显存
两者都是12GB容量 , RTX5070是GDDR7 , 原生带宽更大 , 明显更优 , 这个优势在上文已作讲解 。
总结
六维对比法可以全面评估显卡的性价比 , RX9070GRE在传统渲染性领先 , 其余均逊色于对手 。 目前两者相差300元 , 这点差价无法弥补传统渲染和光追综合性价比的短板 , 更难以覆盖超分和帧生成技术的差距 。 如果不考虑以上六维中的第一二五六项 , 也不考虑残值率 , 仅用第三和第四项做加权平均 , 可得到15%这个值 , 这意味着 , 两者的价格要相差15%性价比才相等 。
【RX9070GRE和RTX5070性价比谁更好?用“六维对比法”一决高下】常有读者提问:N卡和A卡哪个好?这个问题没有绝对的答案 。 价格到位就是好卡 , 价格贵了就会掉价 , 这是经济规律决定的 。 RX9070GRE是一张好显卡 , 但目前和RX5070没有拉开应该有的差距 , 个人预测 , 未来两者的价格差距会大于15% 。
推荐阅读








- 传闻要消失的国补和提前的618:狂欢来临还是暗夜将至?
- 375元的“洋垃圾”笔记本,还是2.5K高分屏,能刷Win11和黑苹果
- 微信悄悄升级新功能:安卓和鸿蒙独享!建议快快升级!
- RTX5070游戏本扎堆上市,一文带你读懂三款高人气机型如何选
- 如何用电脑管理和控制闲置的手机?
- 华为5月火力全开!nova14也要来了,将和首款鸿蒙电脑同台亮相
- 拼多多降低商家虚假发货和欺诈发货的赔付比例
- 鸿蒙PC三大狠招实测:Windows和macOS真慌了?
- 交换机如何支持灵活的链路聚合和分流?
- 光电耦合器在信号传输和隔离中的作用